 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagPipe: Accelerating Deep Recommendation Model Training
Paper and Code
Feb 24, 2022
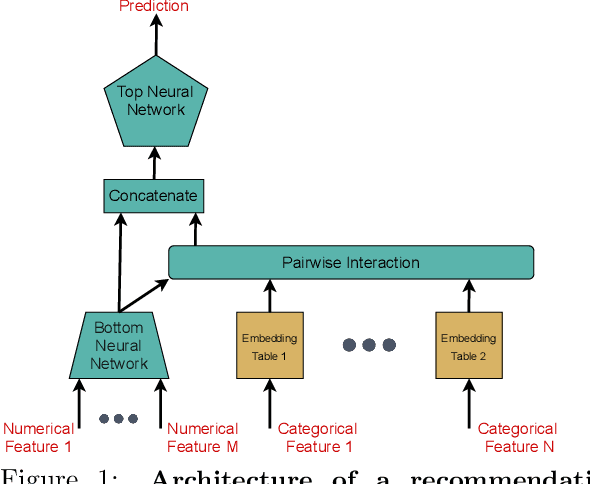
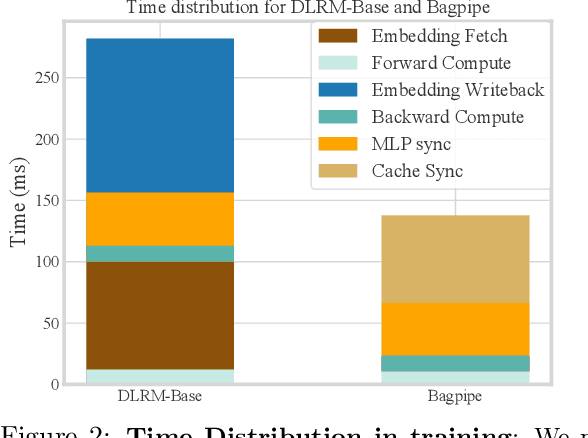
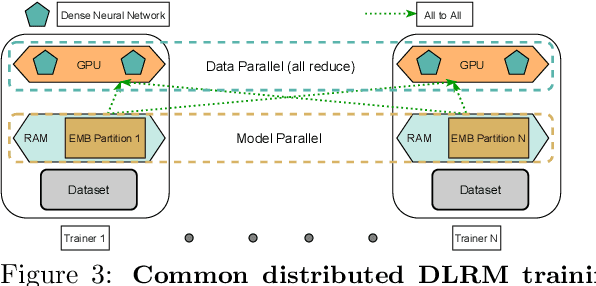
Deep learning based recommendation models (DLRM) are widely used in several business critical applications. Training such recommendation models efficiently is challenging primarily because they consist of billions of embedding-based parameters which are often stored remotely leading to significant overheads from embedding access. By profiling existing DLRM training, we observe that only 8.5% of the iteration time is spent in forward/backward pass while the remaining time is spent on embedding and model synchronization. Our key insight in this paper is that access to embeddings have a specific structure and pattern which can be used to accelerate training. We observe that embedding accesses are heavily skewed, with almost 1% of embeddings represent more than 92% of total accesses. Further, we observe that during training we can lookahead at future batches to determine exactly which embeddings will be needed at what iteration in the future. Based on these insight, we propose Bagpipe, a system for training deep recommendation models that uses caching and prefetching to overlap remote embedding accesses with the computation. We designed an Oracle Cacher, a new system component which uses our lookahead algorithm to generate optimal cache update decisions and provide strong consistency guarantees. Our experiments using three datasets and two models shows that our approach provides a speed up of up to 6.2x compared to state of the art baselines, while providing the same convergence and reproducibility guarantees as synchronous training.