 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFreeze: Automatically Freezing Model Blocks to Accelerate Fine-tuning
Paper and Code
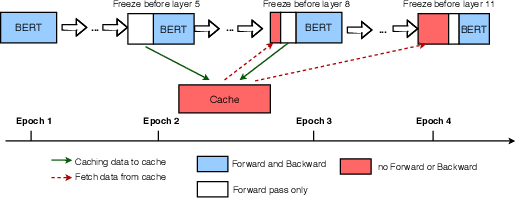
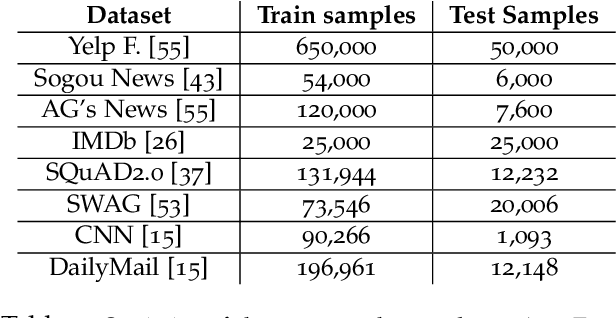
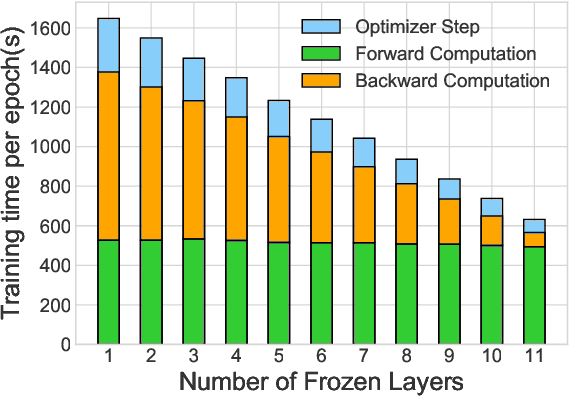
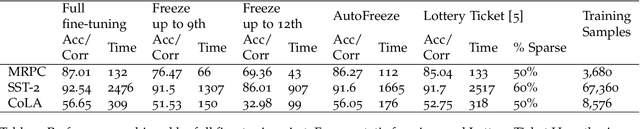
With the rapid adoption of machine learning (ML), a number of domains now use the approach of fine-tuning models pre-trained on a large corpus of data. However, our experiments show that even fine-tuning on models like BERT can take many hours when using GPUs. While prior work proposes limiting the number of layers that are fine-tuned, e.g., freezing all layers but the last layer, we find that such static approaches lead to reduced accuracy. We propose, AutoFreeze, a system that uses an adaptive approach to choose which layers are trained and show how this can accelerate model fine-tuning while preserving accuracy. We also develop mechanisms to enable efficient caching of intermediate activations which can reduce the forward computation time when performing fine-tuning. Our evaluation on fourNLP tasks shows that AutoFreeze, with caching enabled, can improve fine-tuning performance by up to 2.55x.