 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Utility of Gradient Compression in Distributed Training Systems
Paper and Code
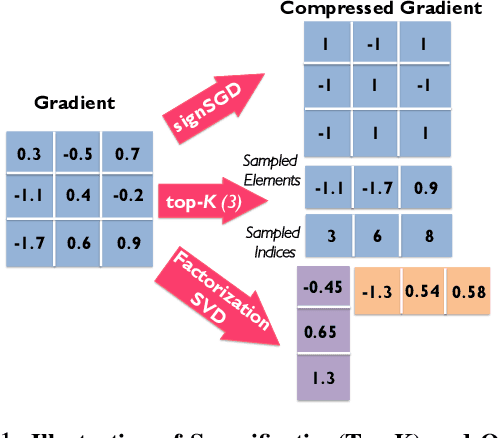


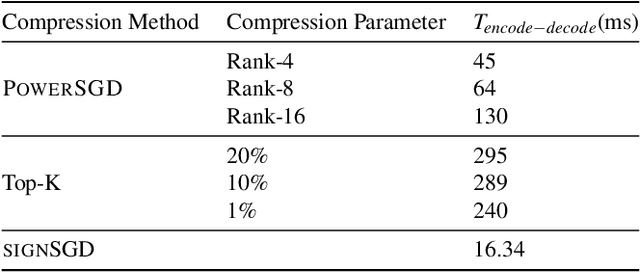
Rapid growth in data sets and the scale of neural network architectures have rendered distributed training a necessity. A rich body of prior work has highlighted the existence of communication bottlenecks in synchronous data-parallel training. To alleviate these bottlenecks, the machine learning community has largely focused on developing gradient and model compression methods. In parallel, the systems community has adopted several High Performance Computing (HPC)techniques to speed up distributed training. In this work, we evaluate the efficacy of gradient compression methods and compare their scalability with optimized implementations of synchronous data-parallel SGD. Surprisingly, we observe that due to computation overheads introduced by gradient compression, the net speedup over vanilla data-parallel training is marginal, if not negative. We conduct an extensive investigation to identify the root causes of this phenomenon, and offer a performance model that can be used to identify the benefits of gradient compression for a variety of system setups. Based on our analysis, we propose a list of desirable properties that gradient compression methods should satisfy, in order for them to provide a meaningful end-to-end speedup