 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuttlefish: Low-Rank Model Training without All the Tuning
May 05, 2023Recent research has shown that training low-rank neural networks can effectively reduce the total number of trainable parameters without sacrificing predictive accuracy, resulting in end-to-end speedups. However, low-rank model training necessitates adjusting several additional factorization hyperparameters, such as the rank of the factorization at each layer. In this paper, we tackle this challenge by introducing Cuttlefish, an automated low-rank training approach that eliminates the need for tuning factorization hyperparameters. Cuttlefish leverages the observation that after a few epochs of full-rank training, the stable rank (i.e., an approximation of the true rank) of each layer stabilizes at a constant value. Cuttlefish switches from full-rank to low-rank training once the stable ranks of all layers have converged, setting the dimension of each factorization to its corresponding stable rank. Our results show that Cuttlefish generates models up to 5.6 times smaller than full-rank models, and attains up to a 1.2 times faster end-to-end training process while preserving comparable accuracy. Moreover, Cuttlefish outperforms state-of-the-art low-rank model training methods and other prominent baselines. The source code for our implementation can be found at: https://github.com/hwang595/Cuttlefish.
MRL: Learning to Mix with Attention and Convolutions
Aug 30, 2022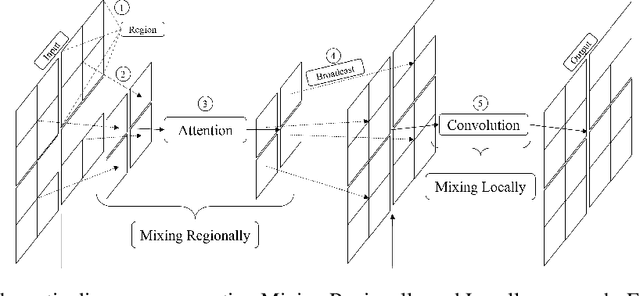
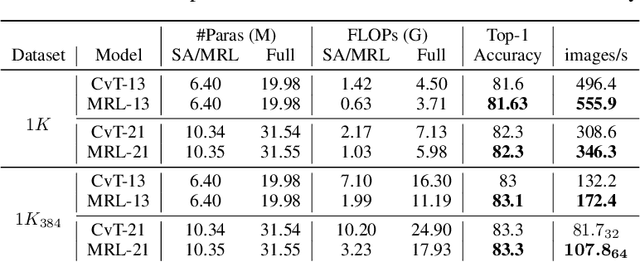

In this paper, we present a new neural architectural block for the vision domain, named Mixing Regionally and Locally (MRL), developed with the aim of effectively and efficiently mixing the provided input features. We bifurcate the input feature mixing task as mixing at a regional and local scale. To achieve an efficient mix, we exploit the domain-wide receptive field provided by self-attention for regional-scale mixing and convolutional kernels restricted to local scale for local-scale mixing. More specifically, our proposed method mixes regional features associated with local features within a defined region, followed by a local-scale features mix augmented by regional features. Experiments show that this hybridization of self-attention and convolution brings improved capacity, generalization (right inductive bias), and efficiency. Under similar network settings, MRL outperforms or is at par with its counterparts in classification, object detection, and segmentation tasks. We also show that our MRL-based network architecture achieves state-of-the-art performance for H&E histology datasets. We achieved DICE of 0.843, 0.855, and 0.892 for Kumar, CoNSep, and CPM-17 datasets, respectively, while highlighting the versatility offered by the MRL framework by incorporating layers like group convolutions to improve dataset-specific generalization.
ImageNet/ResNet-50 Training in 224 Seconds
Nov 13, 2018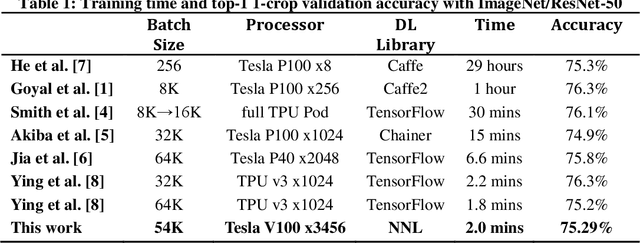
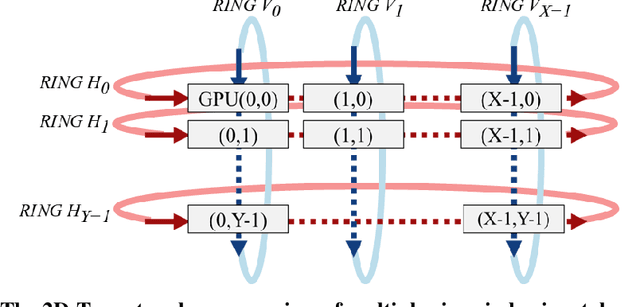

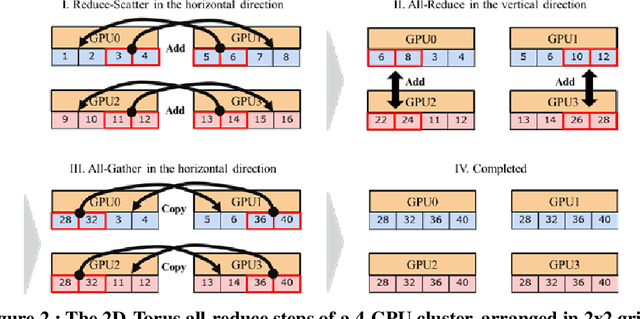
Scaling the distributed deep learning to a massive GPU cluster level is challenging due to the instability of the large mini-batch training and the overhead of the gradient synchronization. We address the instability of the large mini-batch training with batch size control. We address the overhead of the gradient synchronization with 2D-Torus all-reduce. Specifically, 2D-Torus all-reduce arranges GPUs in a logical 2D grid and performs a series of collective operation in different orientations. These two techniques are implemented with Neural Network Libraries (NNL). We have successfully trained ImageNet/ResNet-50 in 224 seconds without significant accuracy loss on ABCI cluster.