 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable K-Medoids via True Error Bound and Familywise Bandits
Paper and Code
May 27, 2019
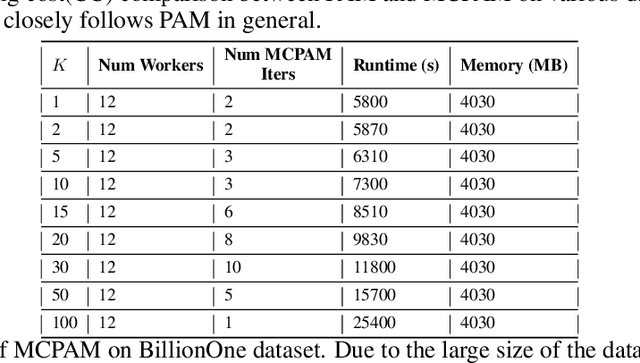
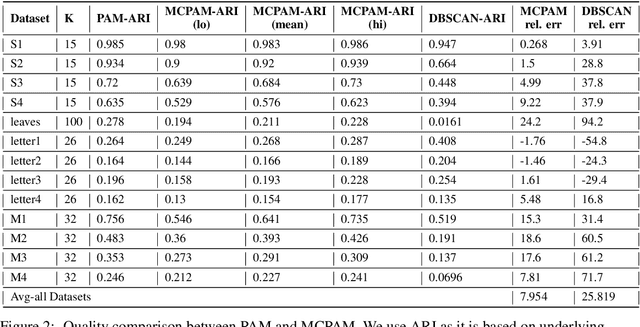
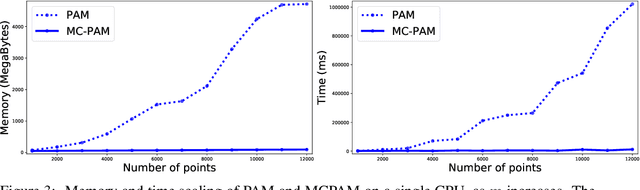
K-Medoids(KM) is a standard clustering method, used extensively on semi-metric data. Error analyses of KM have traditionally used an in-sample notion of error, which can be far from the true error and suffer from generalization error. We formalize the true K-Medoid error based on the underlying data distribution, by decomposing it into fundamental statistical problems of: minimum estimation (ME) and minimum mean estimation (MME). We provide a convergence result for MME and bound the true KM error for iid data. Inspired by this bound, we propose a computationally efficient, distributed KM algorithm namely MCPAM. MCPAM has expected runtime $\mathcal{O}(km)$ and provides massive computational savings for a small tradeoff in accuracy. We verify the quality and scaling properties of MCPAM on various datasets. And achieve the hitherto unachieved feat of calculating the KM of 1 billion points on semi-metric spaces.