 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftSketch: A Diffusion Model for Image-to-Vector Sketch Generation
Feb 12, 2025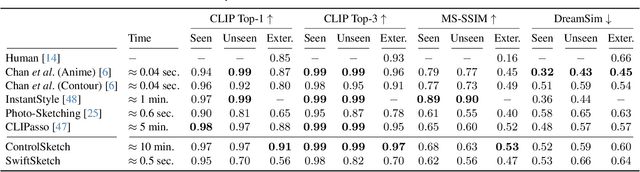
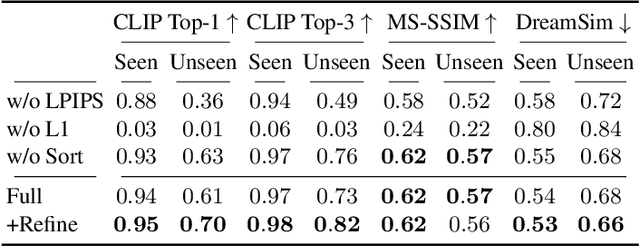
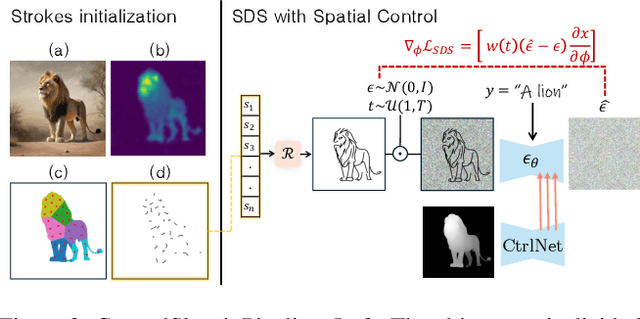
Recent advancements in large vision-language models have enabled highly expressive and diverse vector sketch generation. However, state-of-the-art methods rely on a time-consuming optimization process involving repeated feedback from a pretrained model to determine stroke placement. Consequently, despite producing impressive sketches, these methods are limited in practical applications. In this work, we introduce SwiftSketch, a diffusion model for image-conditioned vector sketch generation that can produce high-quality sketches in less than a second. SwiftSketch operates by progressively denoising stroke control points sampled from a Gaussian distribution. Its transformer-decoder architecture is designed to effectively handle the discrete nature of vector representation and capture the inherent global dependencies between strokes. To train SwiftSketch, we construct a synthetic dataset of image-sketch pairs, addressing the limitations of existing sketch datasets, which are often created by non-artists and lack professional quality. For generating these synthetic sketches, we introduce ControlSketch, a method that enhances SDS-based techniques by incorporating precise spatial control through a depth-aware ControlNet. We demonstrate that SwiftSketch generalizes across diverse concepts, efficiently producing sketches that combine high fidelity with a natural and visually appealing style.
Implicit Style-Content Separation using B-LoRA
Mar 21, 2024Image stylization involves manipulating the visual appearance and texture (style) of an image while preserving its underlying objects, structures, and concepts (content). The separation of style and content is essential for manipulating the image's style independently from its content, ensuring a harmonious and visually pleasing result. Achieving this separation requires a deep understanding of both the visual and semantic characteristics of images, often necessitating the training of specialized models or employing heavy optimization. In this paper, we introduce B-LoRA, a method that leverages LoRA (Low-Rank Adaptation) to implicitly separate the style and content components of a single image, facilitating various image stylization tasks. By analyzing the architecture of SDXL combined with LoRA, we find that jointly learning the LoRA weights of two specific blocks (referred to as B-LoRAs) achieves style-content separation that cannot be achieved by training each B-LoRA independently. Consolidating the training into only two blocks and separating style and content allows for significantly improving style manipulation and overcoming overfitting issues often associated with model fine-tuning. Once trained, the two B-LoRAs can be used as independent components to allow various image stylization tasks, including image style transfer, text-based image stylization, consistent style generation, and style-content mixing.