 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynSetExpan: An Iterative Framework for Joint Entity Set Expansion and Synonym Discovery
Sep 29, 2020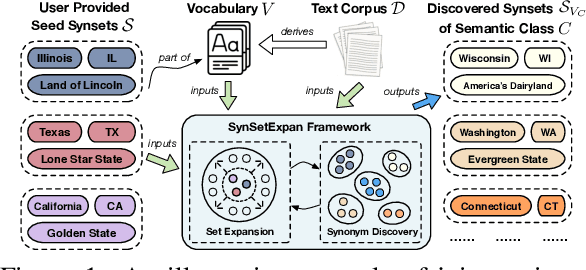

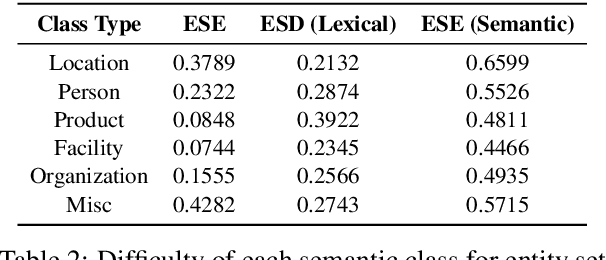
Entity set expansion and synonym discovery are two critical NLP tasks. Previous studies accomplish them separately, without exploring their interdependencies. In this work, we hypothesize that these two tasks are tightly coupled because two synonymous entities tend to have similar likelihoods of belonging to various semantic classes. This motivates us to design SynSetExpan, a novel framework that enables two tasks to mutually enhance each other. SynSetExpan uses a synonym discovery model to include popular entities' infrequent synonyms into the set, which boosts the set expansion recall. Meanwhile, the set expansion model, being able to determine whether an entity belongs to a semantic class, can generate pseudo training data to fine-tune the synonym discovery model towards better accuracy. To facilitate the research on studying the interplays of these two tasks, we create the first large-scale Synonym-Enhanced Set Expansion (SE2) dataset via crowdsourcing. Extensive experiments on the SE2 dataset and previous benchmarks demonstrate the effectiveness of SynSetExpan for both entity set expansion and synonym discovery tasks.
Benchmark Visual Question Answer Models by using Focus Map
Jan 13, 2018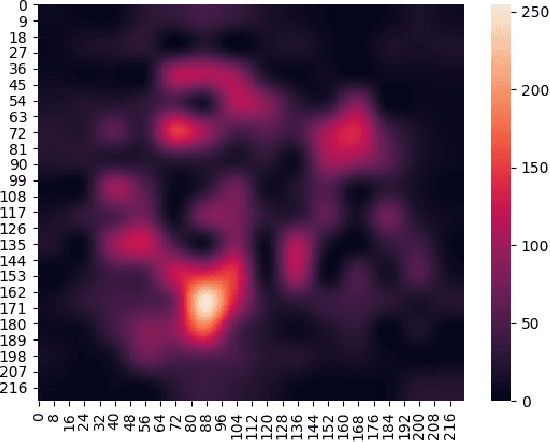

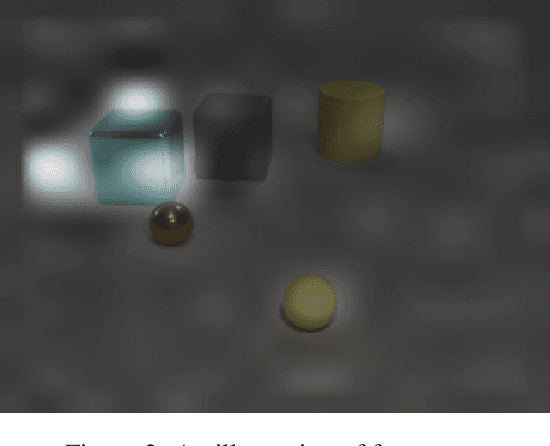
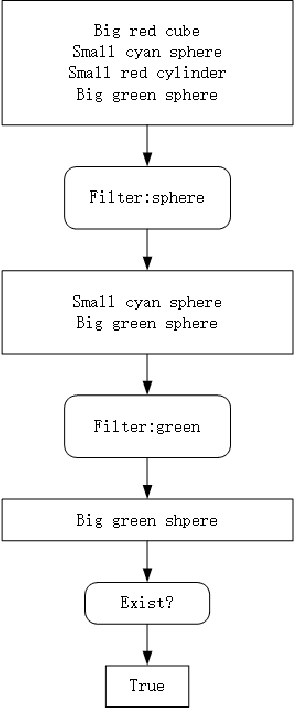
Inferring and Executing Programs for Visual Reasoning proposes a model for visual reasoning that consists of a program generator and an execution engine to avoid end-to-end models. To show that the model actually learns which objects to focus on to answer the questions, the authors give a visualization of the norm of the gradient of the sum of the predicted answer scores with respect to the final feature map. However, the authors do not evaluate the efficiency of focus map. This paper purposed a method for evaluating it. We generate several kinds of questions to test different keywords. We infer focus maps from the model by asking these questions and evaluate them by comparing with the segmentation graph. Furthermore, this method can be applied to any model if focus maps can be inferred from it. By evaluating focus map of different models on the CLEVR dataset, we will show that CLEVR-iep model has learned where to focus more than end-to-end models.