 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate full conformal prediction in an RKHS
Jan 24, 2026Full conformal prediction is a framework that implicitly formulates distribution-free confidence prediction regions for a wide range of estimators. However, a classical limitation of the full conformal framework is the computation of the confidence prediction regions, which is usually impossible since it requires training infinitely many estimators (for real-valued prediction for instance). The main purpose of the present work is to describe a generic strategy for designing a tight approximation to the full conformal prediction region that can be efficiently computed. Along with this approximate confidence region, a theoretical quantification of the tightness of this approximation is developed, depending on the smoothness assumptions on the loss and score functions. The new notion of thickness is introduced for quantifying the discrepancy between the approximate confidence region and the full conformal one.
Approximate full conformal prediction in RKHS
Jan 19, 2026Full conformal prediction is a framework that implicitly formulates distribution-free confidence prediction regions for a wide range of estimators. However, a classical limitation of the full conformal framework is the computation of the confidence prediction regions, which is usually impossible since it requires training infinitely many estimators (for real-valued prediction for instance). The main purpose of the present work is to describe a generic strategy for designing a tight approximation to the full conformal prediction region that can be efficiently computed. Along with this approximate confidence region, a theoretical quantification of the tightness of this approximation is developed, depending on the smoothness assumptions on the loss and score functions. The new notion of thickness is introduced for quantifying the discrepancy between the approximate confidence region and the full conformal one.
A Survey and Implementation of Performance Metrics for Self-Organized Maps
Nov 11, 2020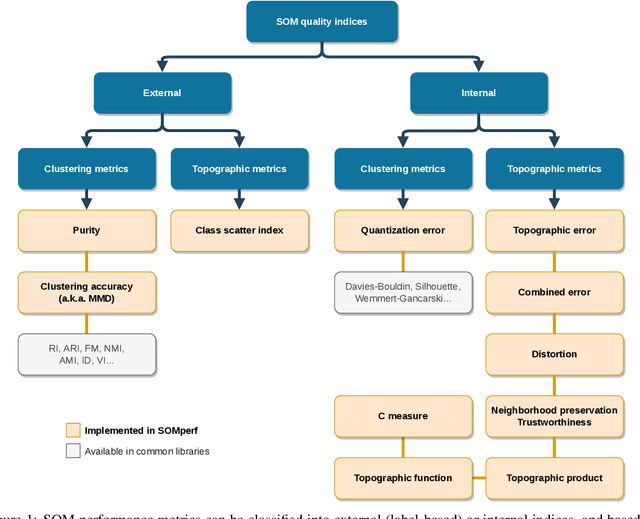
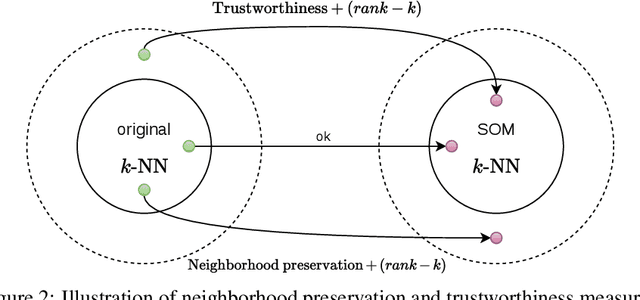
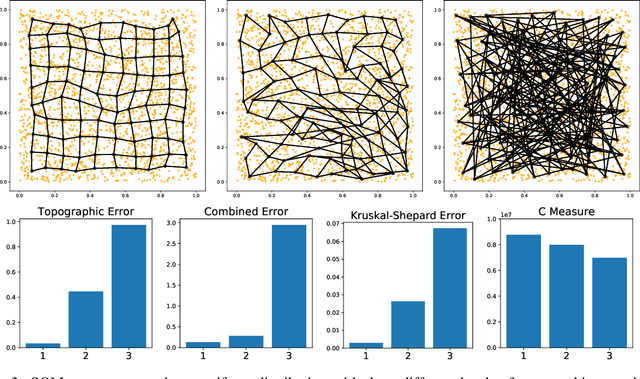
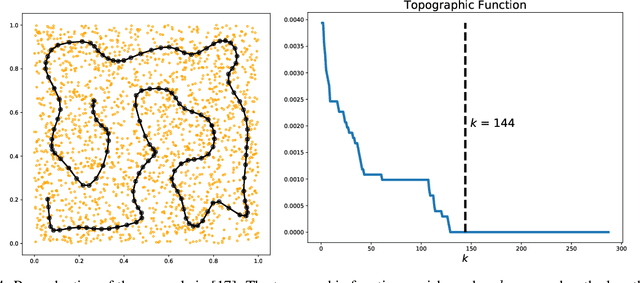
Self-Organizing Map algorithms have been used for almost 40 years across various application domains such as biology, geology, healthcare, industry and humanities as an interpretable tool to explore, cluster and visualize high-dimensional data sets. In every application, practitioners need to know whether they can \textit{trust} the resulting mapping, and perform model selection to tune algorithm parameters (e.g. the map size). Quantitative evaluation of self-organizing maps (SOM) is a subset of clustering validation, which is a challenging problem as such. Clustering model selection is typically achieved by using clustering validity indices. While they also apply to self-organized clustering models, they ignore the topology of the map, only answering the question: do the SOM code vectors approximate well the data distribution? Evaluating SOM models brings in the additional challenge of assessing their topology: does the mapping preserve neighborhood relationships between the map and the original data? The problem of assessing the performance of SOM models has already been tackled quite thoroughly in literature, giving birth to a family of quality indices incorporating neighborhood constraints, called \textit{topographic} indices. Commonly used examples of such metrics are the topographic error, neighborhood preservation or the topographic product. However, open-source implementations are almost impossible to find. This is the issue we try to solve in this work: after a survey of existing SOM performance metrics, we implemented them in Python and widely used numerical libraries, and provide them as an open-source library, SOMperf. This paper introduces each metric available in our module along with usage examples.
Selecting the Number of Clusters $K$ with a Stability Trade-off: an Internal Validation Criterion
Jul 16, 2020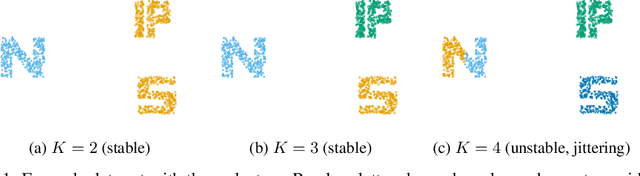
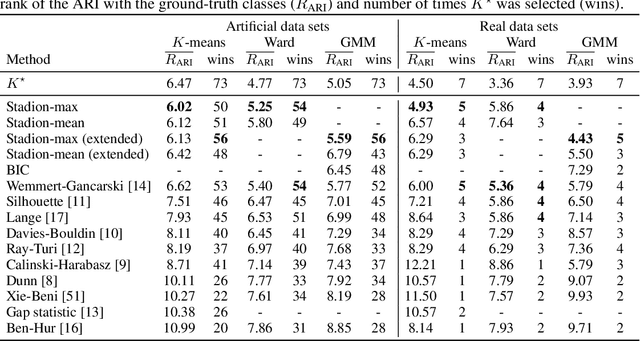
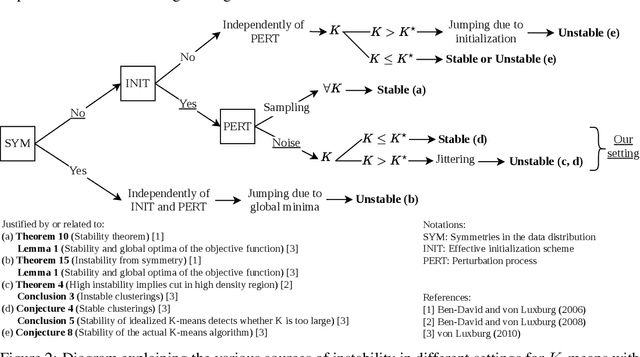
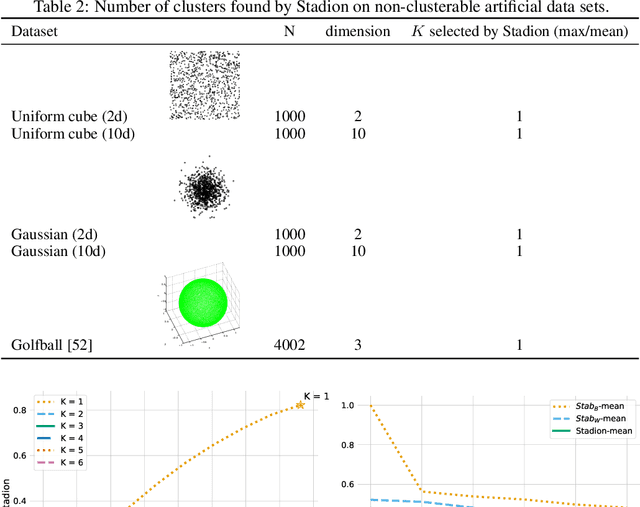
Model selection is a major challenge in non-parametric clustering. There is no universally admitted way to evaluate clustering results for the obvious reason that there is no ground truth against which results could be tested, as in supervised learning. The difficulty to find a universal evaluation criterion is a direct consequence of the fundamentally ill-defined objective of clustering. In this perspective, clustering stability has emerged as a natural and model-agnostic principle: an algorithm should find stable structures in the data. If data sets are repeatedly sampled from the same underlying distribution, an algorithm should find similar partitions. However, it turns out that stability alone is not a well-suited tool to determine the number of clusters. For instance, it is unable to detect if the number of clusters is too small. We propose a new principle for clustering validation: a good clustering should be stable, and within each cluster, there should exist no stable partition. This principle leads to a novel internal clustering validity criterion based on between-cluster and within-cluster stability, overcoming limitations of previous stability-based methods. We empirically show the superior ability of additive noise to discover structures, compared with sampling-based perturbation. We demonstrate the effectiveness of our method for selecting the number of clusters through a large number of experiments and compare it with existing evaluation methods.
Search Strategies for Binary Feature Selection for a Naive Bayes Classifier
Jun 12, 2015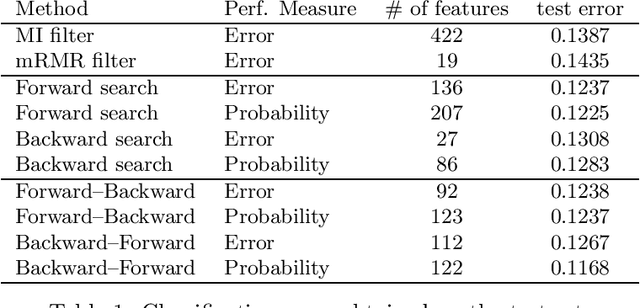
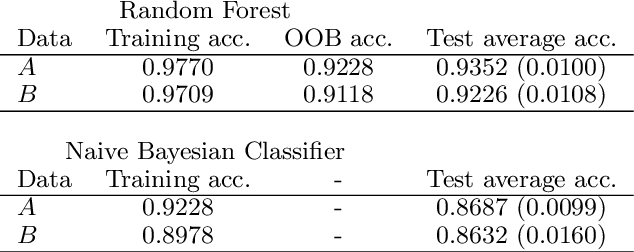
We compare in this paper several feature selection methods for the Naive Bayes Classifier (NBC) when the data under study are described by a large number of redundant binary indicators. Wrapper approaches guided by the NBC estimation of the classification error probability out-perform filter approaches while retaining a reasonable computational cost.
Interpretable Aircraft Engine Diagnostic via Expert Indicator Aggregation
Mar 18, 2015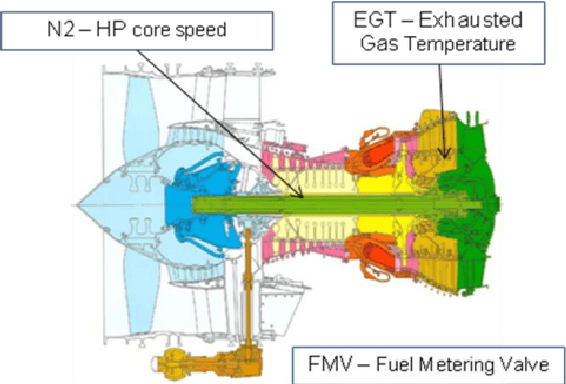



Detecting early signs of failures (anomalies) in complex systems is one of the main goal of preventive maintenance. It allows in particular to avoid actual failures by (re)scheduling maintenance operations in a way that optimizes maintenance costs. Aircraft engine health monitoring is one representative example of a field in which anomaly detection is crucial. Manufacturers collect large amount of engine related data during flights which are used, among other applications, to detect anomalies. This article introduces and studies a generic methodology that allows one to build automatic early signs of anomaly detection in a way that builds upon human expertise and that remains understandable by human operators who make the final maintenance decision. The main idea of the method is to generate a very large number of binary indicators based on parametric anomaly scores designed by experts, complemented by simple aggregations of those scores. A feature selection method is used to keep only the most discriminant indicators which are used as inputs of a Naive Bayes classifier. This give an interpretable classifier based on interpretable anomaly detectors whose parameters have been optimized indirectly by the selection process. The proposed methodology is evaluated on simulated data designed to reproduce some of the anomaly types observed in real world engines.
* arXiv admin note: substantial text overlap with arXiv:1408.6214, arXiv:1409.4747, arXiv:1407.0880
Anomaly Detection Based on Indicators Aggregation
Sep 16, 2014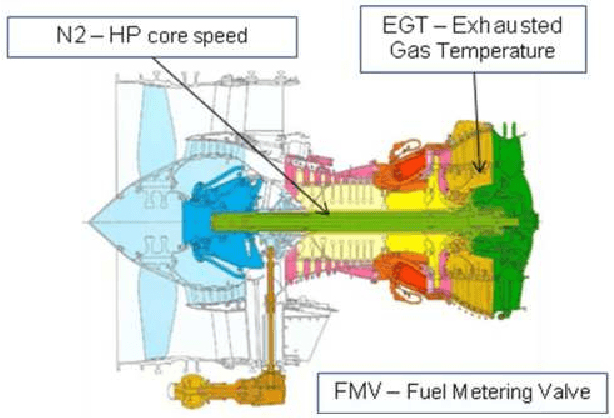
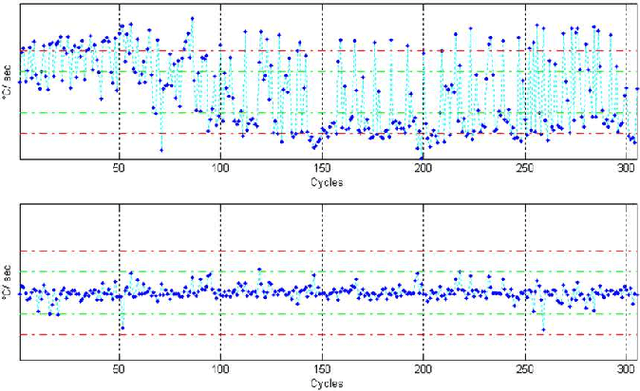
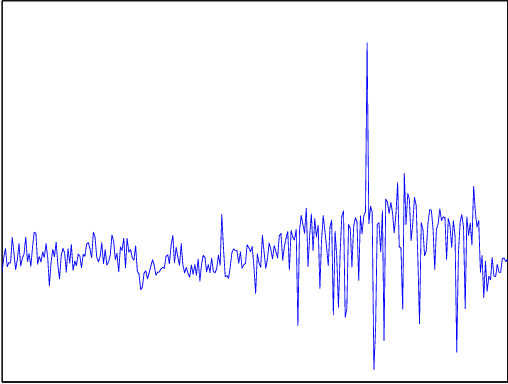
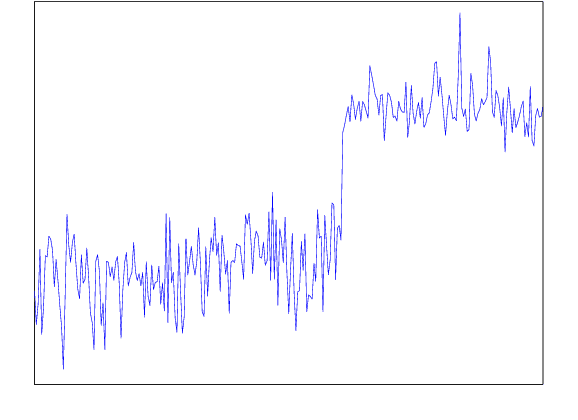
Automatic anomaly detection is a major issue in various areas. Beyond mere detection, the identification of the source of the problem that produced the anomaly is also essential. This is particularly the case in aircraft engine health monitoring where detecting early signs of failure (anomalies) and helping the engine owner to implement efficiently the adapted maintenance operations (fixing the source of the anomaly) are of crucial importance to reduce the costs attached to unscheduled maintenance. This paper introduces a general methodology that aims at classifying monitoring signals into normal ones and several classes of abnormal ones. The main idea is to leverage expert knowledge by generating a very large number of binary indicators. Each indicator corresponds to a fully parametrized anomaly detector built from parametric anomaly scores designed by experts. A feature selection method is used to keep only the most discriminant indicators which are used at inputs of a Naive Bayes classifier. This give an interpretable classifier based on interpretable anomaly detectors whose parameters have been optimized indirectly by the selection process. The proposed methodology is evaluated on simulated data designed to reproduce some of the anomaly types observed in real world engines.
Anomaly Detection Based on Aggregation of Indicators
Sep 16, 2014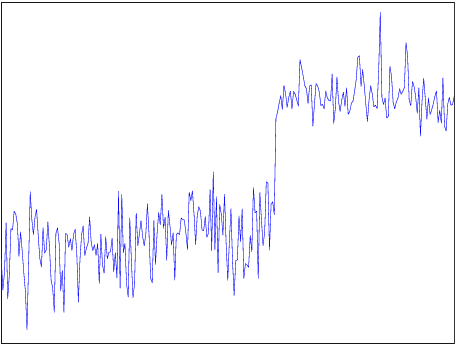
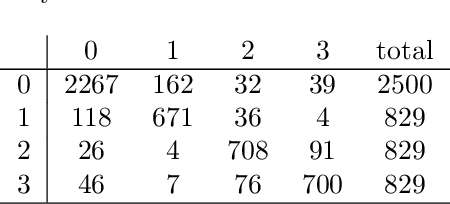
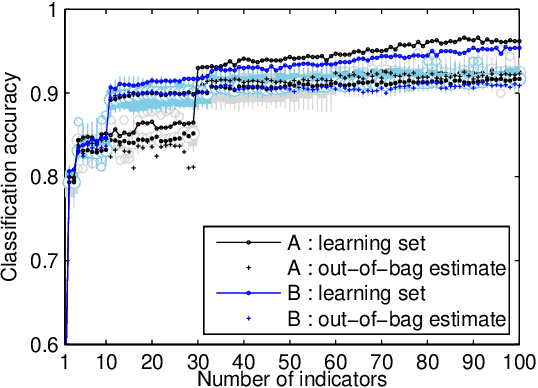
Automatic anomaly detection is a major issue in various areas. Beyond mere detection, the identification of the origin of the problem that produced the anomaly is also essential. This paper introduces a general methodology that can assist human operators who aim at classifying monitoring signals. The main idea is to leverage expert knowledge by generating a very large number of indicators. A feature selection method is used to keep only the most discriminant indicators which are used as inputs of a Naive Bayes classifier. The parameters of the classifier have been optimized indirectly by the selection process. Simulated data designed to reproduce some of the anomaly types observed in real world engines.
A Methodology for the Diagnostic of Aircraft Engine Based on Indicators Aggregation
Aug 26, 2014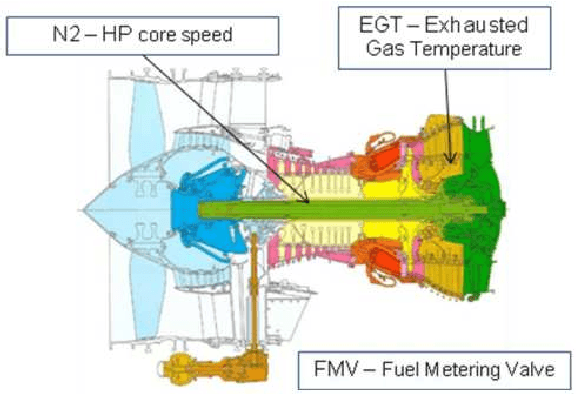

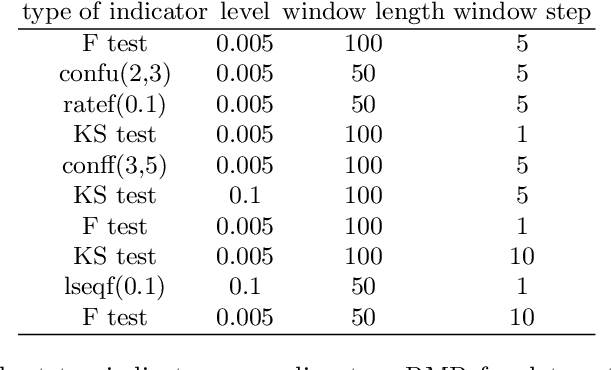
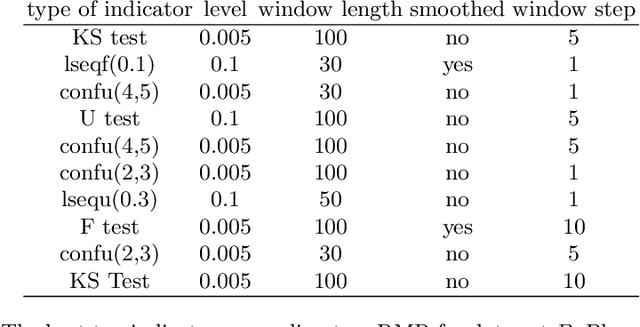
Aircraft engine manufacturers collect large amount of engine related data during flights. These data are used to detect anomalies in the engines in order to help companies optimize their maintenance costs. This article introduces and studies a generic methodology that allows one to build automatic early signs of anomaly detection in a way that is understandable by human operators who make the final maintenance decision. The main idea of the method is to generate a very large number of binary indicators based on parametric anomaly scores designed by experts, complemented by simple aggregations of those scores. The best indicators are selected via a classical forward scheme, leading to a much reduced number of indicators that are tuned to a data set. We illustrate the interest of the method on simulated data which contain realistic early signs of anomalies.