 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to improve robustness in Kohonen maps and display additional information in Factorial Analysis: application to text mining
Jun 25, 2015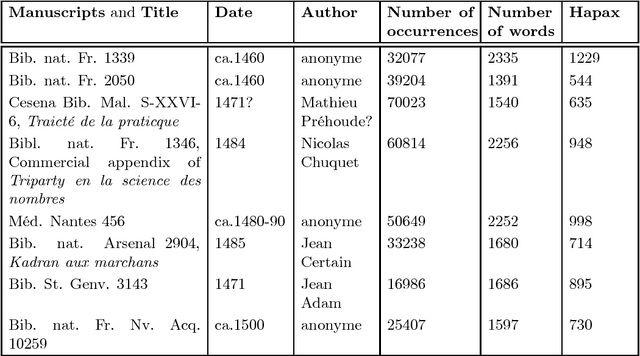
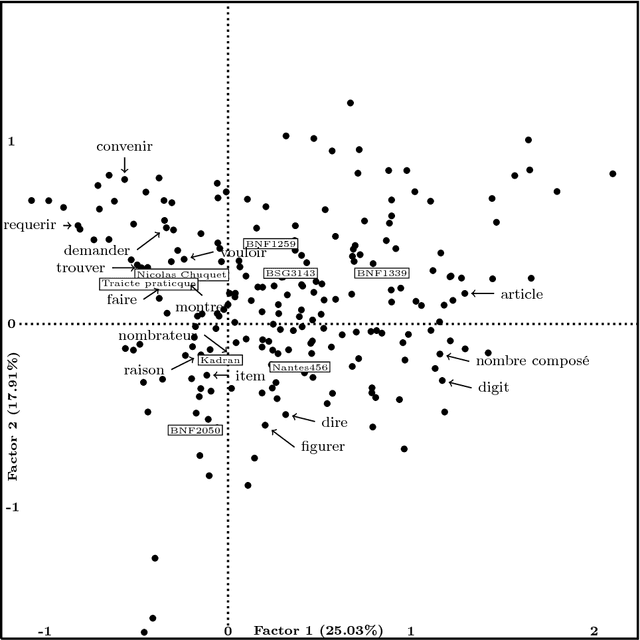
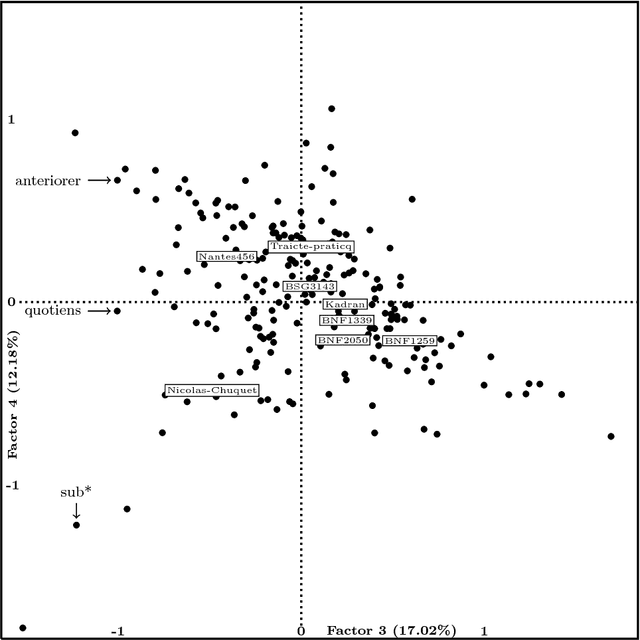
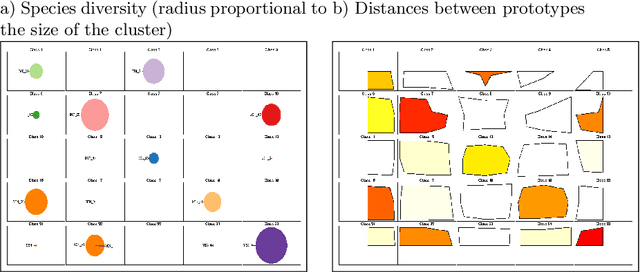
This article is an extended version of a paper presented in the WSOM'2012 conference [1]. We display a combination of factorial projections, SOM algorithm and graph techniques applied to a text mining problem. The corpus contains 8 medieval manuscripts which were used to teach arithmetic techniques to merchants. Among the techniques for Data Analysis, those used for Lexicometry (such as Factorial Analysis) highlight the discrepancies between manuscripts. The reason for this is that they focus on the deviation from the independence between words and manuscripts. Still, we also want to discover and characterize the common vocabulary among the whole corpus. Using the properties of stochastic Kohonen maps, which define neighborhood between inputs in a non-deterministic way, we highlight the words which seem to play a special role in the vocabulary. We call them fickle and use them to improve both Kohonen map robustness and significance of FCA visualization. Finally we use graph algorithmic to exploit this fickleness for classification of words.
Search Strategies for Binary Feature Selection for a Naive Bayes Classifier
Jun 12, 2015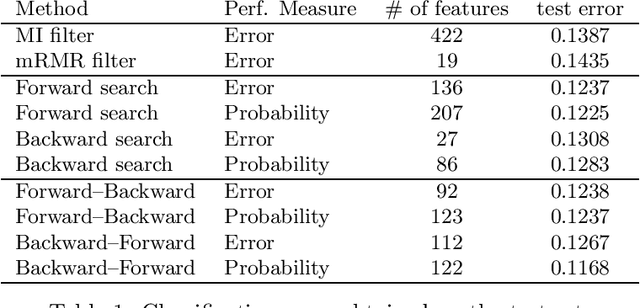
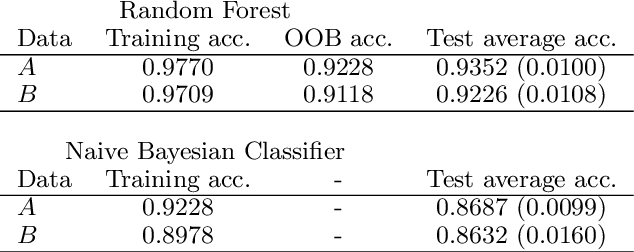
We compare in this paper several feature selection methods for the Naive Bayes Classifier (NBC) when the data under study are described by a large number of redundant binary indicators. Wrapper approaches guided by the NBC estimation of the classification error probability out-perform filter approaches while retaining a reasonable computational cost.
Interpretable Aircraft Engine Diagnostic via Expert Indicator Aggregation
Mar 18, 2015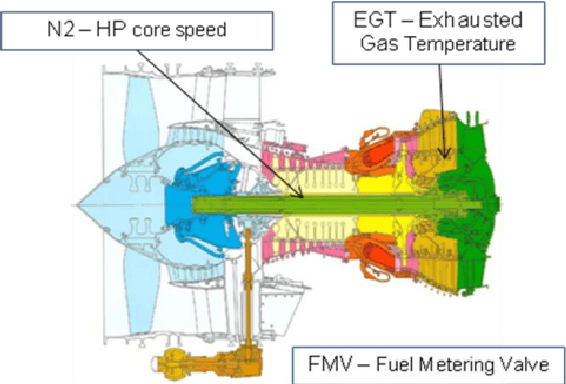



Detecting early signs of failures (anomalies) in complex systems is one of the main goal of preventive maintenance. It allows in particular to avoid actual failures by (re)scheduling maintenance operations in a way that optimizes maintenance costs. Aircraft engine health monitoring is one representative example of a field in which anomaly detection is crucial. Manufacturers collect large amount of engine related data during flights which are used, among other applications, to detect anomalies. This article introduces and studies a generic methodology that allows one to build automatic early signs of anomaly detection in a way that builds upon human expertise and that remains understandable by human operators who make the final maintenance decision. The main idea of the method is to generate a very large number of binary indicators based on parametric anomaly scores designed by experts, complemented by simple aggregations of those scores. A feature selection method is used to keep only the most discriminant indicators which are used as inputs of a Naive Bayes classifier. This give an interpretable classifier based on interpretable anomaly detectors whose parameters have been optimized indirectly by the selection process. The proposed methodology is evaluated on simulated data designed to reproduce some of the anomaly types observed in real world engines.
* arXiv admin note: substantial text overlap with arXiv:1408.6214, arXiv:1409.4747, arXiv:1407.0880
Anomaly Detection Based on Indicators Aggregation
Sep 16, 2014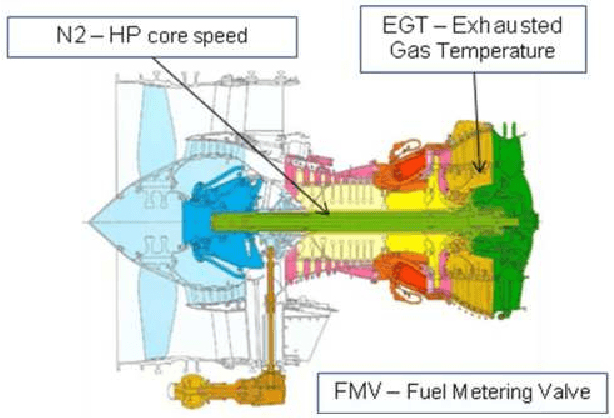
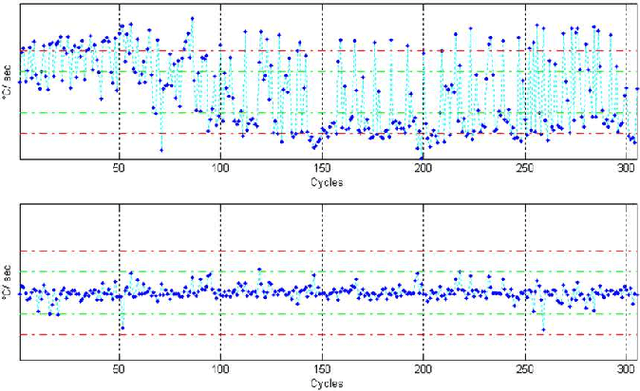
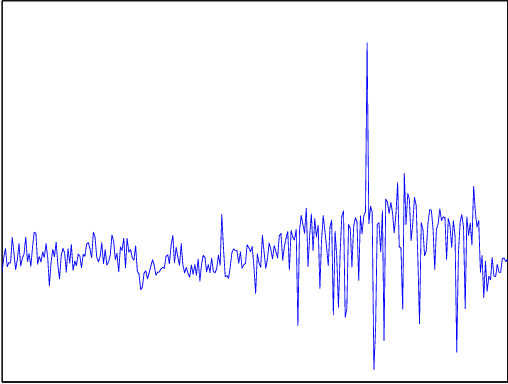
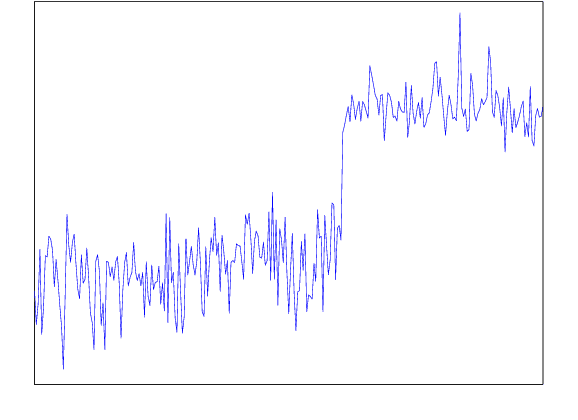
Automatic anomaly detection is a major issue in various areas. Beyond mere detection, the identification of the source of the problem that produced the anomaly is also essential. This is particularly the case in aircraft engine health monitoring where detecting early signs of failure (anomalies) and helping the engine owner to implement efficiently the adapted maintenance operations (fixing the source of the anomaly) are of crucial importance to reduce the costs attached to unscheduled maintenance. This paper introduces a general methodology that aims at classifying monitoring signals into normal ones and several classes of abnormal ones. The main idea is to leverage expert knowledge by generating a very large number of binary indicators. Each indicator corresponds to a fully parametrized anomaly detector built from parametric anomaly scores designed by experts. A feature selection method is used to keep only the most discriminant indicators which are used at inputs of a Naive Bayes classifier. This give an interpretable classifier based on interpretable anomaly detectors whose parameters have been optimized indirectly by the selection process. The proposed methodology is evaluated on simulated data designed to reproduce some of the anomaly types observed in real world engines.
Anomaly Detection Based on Aggregation of Indicators
Sep 16, 2014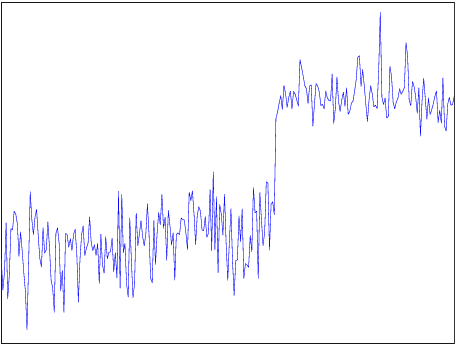
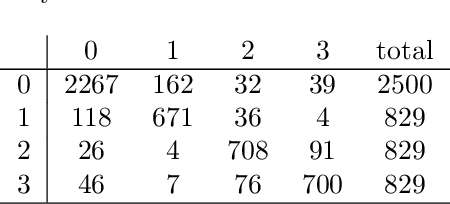
Automatic anomaly detection is a major issue in various areas. Beyond mere detection, the identification of the origin of the problem that produced the anomaly is also essential. This paper introduces a general methodology that can assist human operators who aim at classifying monitoring signals. The main idea is to leverage expert knowledge by generating a very large number of indicators. A feature selection method is used to keep only the most discriminant indicators which are used as inputs of a Naive Bayes classifier. The parameters of the classifier have been optimized indirectly by the selection process. Simulated data designed to reproduce some of the anomaly types observed in real world engines.
A Methodology for the Diagnostic of Aircraft Engine Based on Indicators Aggregation
Aug 26, 2014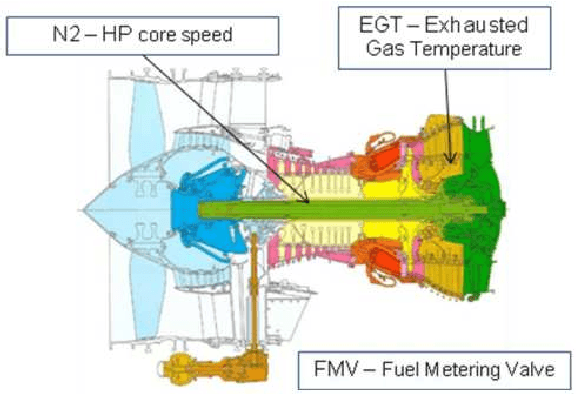

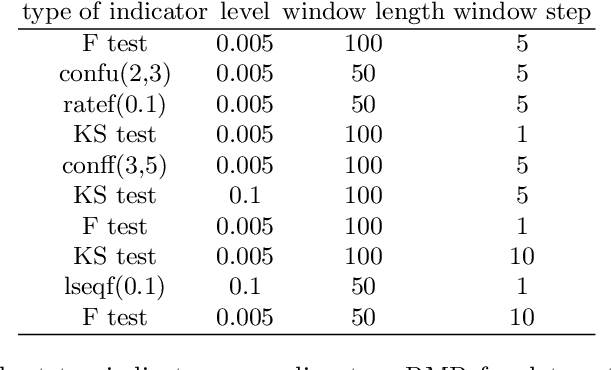
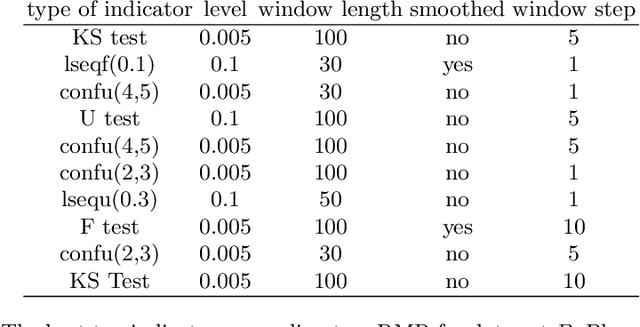
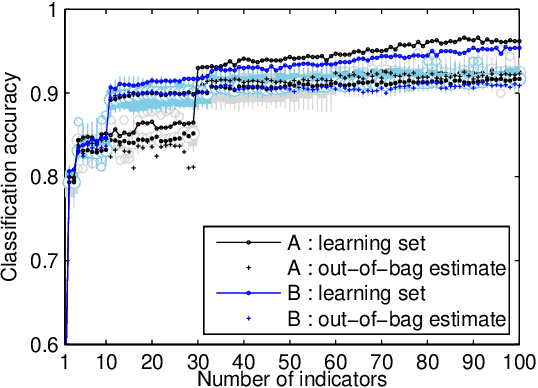
Aircraft engine manufacturers collect large amount of engine related data during flights. These data are used to detect anomalies in the engines in order to help companies optimize their maintenance costs. This article introduces and studies a generic methodology that allows one to build automatic early signs of anomaly detection in a way that is understandable by human operators who make the final maintenance decision. The main idea of the method is to generate a very large number of binary indicators based on parametric anomaly scores designed by experts, complemented by simple aggregations of those scores. The best indicators are selected via a classical forward scheme, leading to a much reduced number of indicators that are tuned to a data set. We illustrate the interest of the method on simulated data which contain realistic early signs of anomalies.
On-line relational SOM for dissimilarity data
Dec 27, 2012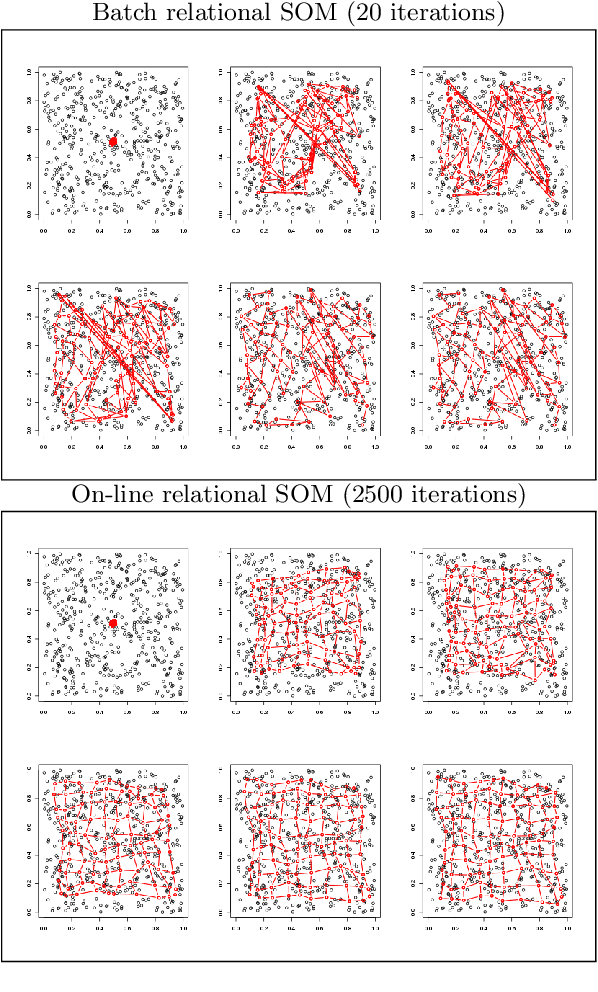

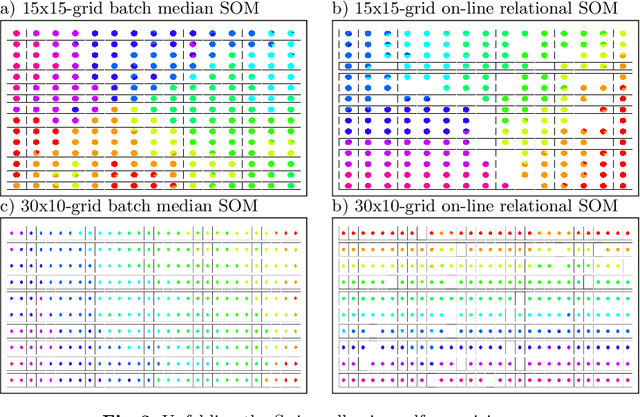
In some applications and in order to address real world situations better, data may be more complex than simple vectors. In some examples, they can be known through their pairwise dissimilarities only. Several variants of the Self Organizing Map algorithm were introduced to generalize the original algorithm to this framework. Whereas median SOM is based on a rough representation of the prototypes, relational SOM allows representing these prototypes by a virtual combination of all elements in the data set. However, this latter approach suffers from two main drawbacks. First, its complexity can be large. Second, only a batch version of this algorithm has been studied so far and it often provides results having a bad topographic organization. In this article, an on-line version of relational SOM is described and justified. The algorithm is tested on several datasets, including categorical data and graphs, and compared with the batch version and with other SOM algorithms for non vector data.
Neural Networks for Complex Data
Oct 24, 2012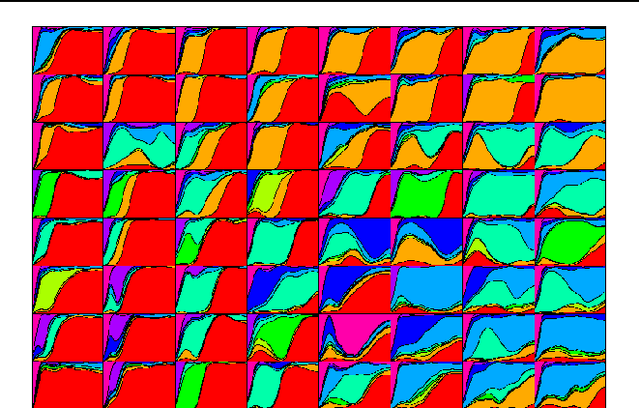
Artificial neural networks are simple and efficient machine learning tools. Defined originally in the traditional setting of simple vector data, neural network models have evolved to address more and more difficulties of complex real world problems, ranging from time evolving data to sophisticated data structures such as graphs and functions. This paper summarizes advances on those themes from the last decade, with a focus on results obtained by members of the SAMM team of Universit\'e Paris 1
Traitement Des Donnees Manquantes Au Moyen De L'Algorithme De Kohonen
Apr 13, 2007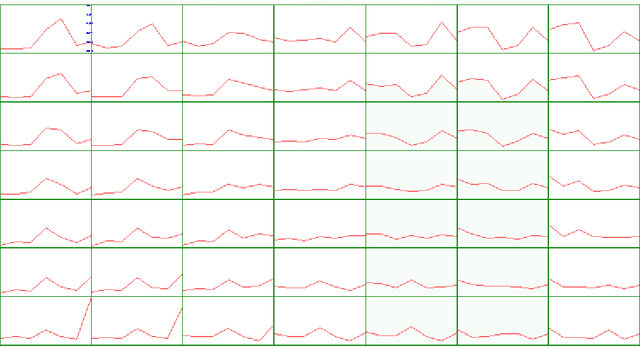
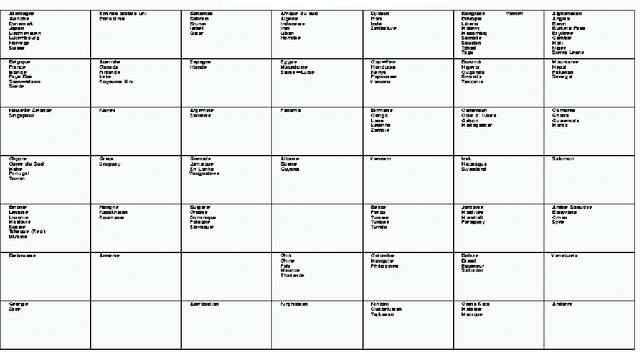
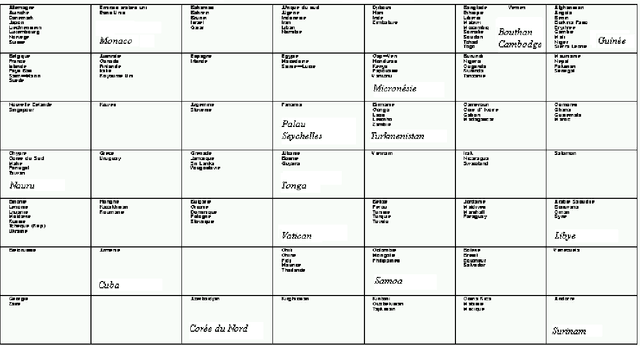

Nous montrons comment il est possible d'utiliser l'algorithme d'auto organisation de Kohonen pour traiter des donn\'ees avec valeurs manquantes et estimer ces derni\`eres. Apr\`es un rappel m\'ethodologique, nous illustrons notre propos \`a partir de trois applications \`a des donn\'ees r\'eelles. ----- We show how it is possible to use the Kohonen self-organizing algorithm to deal with data which contain missing values and to estimate them. After a methodological recall, we illustrate our purpose from three real databases applications.
Consumer Profile Identification and Allocation
Apr 03, 2007
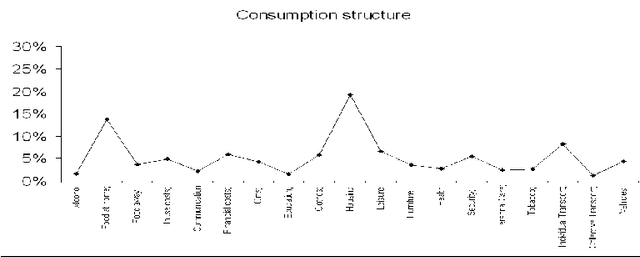


We propose an easy-to-use methodology to allocate one of the groups which have been previously built from a complete learning data base, to new individuals. The learning data base contains continuous and categorical variables for each individual. The groups (clusters) are built by using only the continuous variables and described with the help of the categorical ones. For the new individuals, only the categorical variables are available, and it is necessary to define a model which computes the probabilities to belong to each of the clusters, by using only the categorical variables. Then this model provides a decision rule to assign the new individuals and gives an efficient tool to decision-makers. This tool is shown to be very efficient for customers allocation in consumer clusters for marketing purposes, for example.