 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to improve robustness in Kohonen maps and display additional information in Factorial Analysis: application to text mining
Jun 25, 2015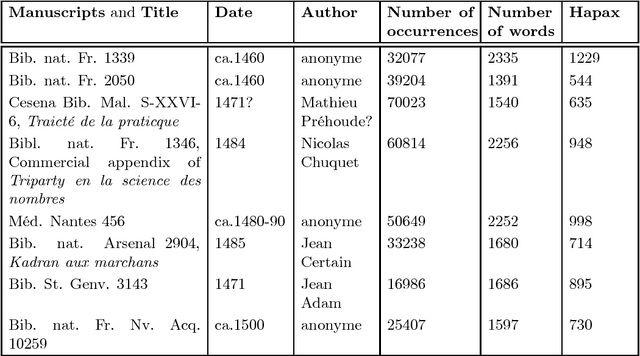
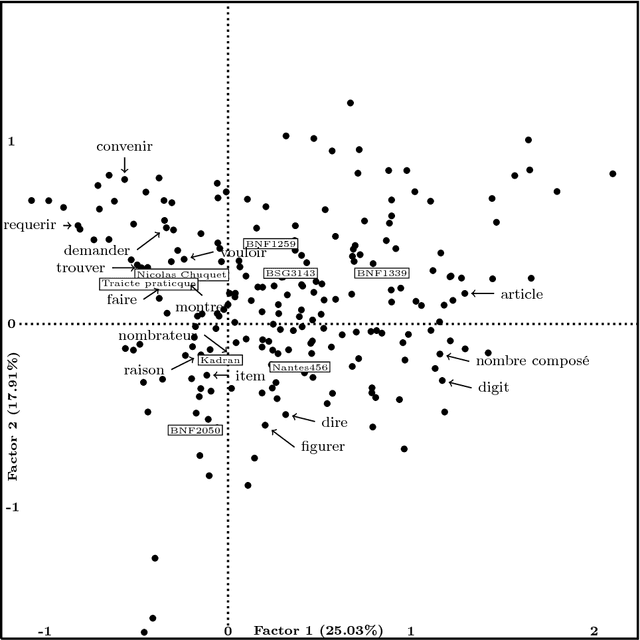
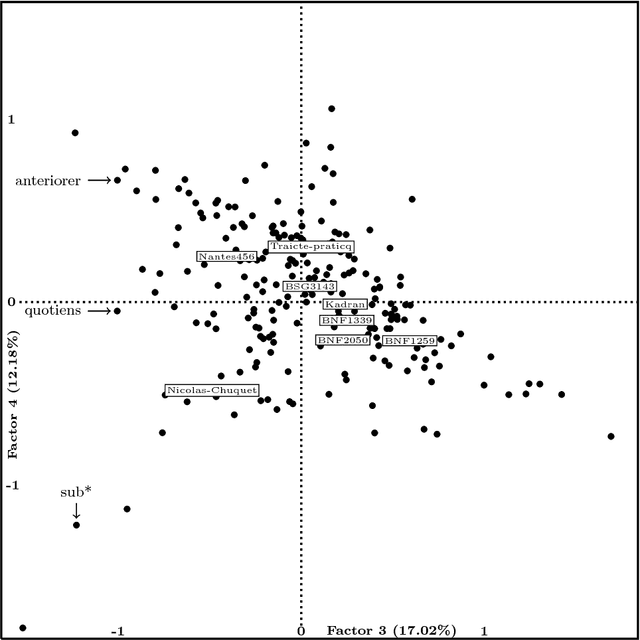
This article is an extended version of a paper presented in the WSOM'2012 conference [1]. We display a combination of factorial projections, SOM algorithm and graph techniques applied to a text mining problem. The corpus contains 8 medieval manuscripts which were used to teach arithmetic techniques to merchants. Among the techniques for Data Analysis, those used for Lexicometry (such as Factorial Analysis) highlight the discrepancies between manuscripts. The reason for this is that they focus on the deviation from the independence between words and manuscripts. Still, we also want to discover and characterize the common vocabulary among the whole corpus. Using the properties of stochastic Kohonen maps, which define neighborhood between inputs in a non-deterministic way, we highlight the words which seem to play a special role in the vocabulary. We call them fickle and use them to improve both Kohonen map robustness and significance of FCA visualization. Finally we use graph algorithmic to exploit this fickleness for classification of words.
Traitement Des Donnees Manquantes Au Moyen De L'Algorithme De Kohonen
Apr 13, 2007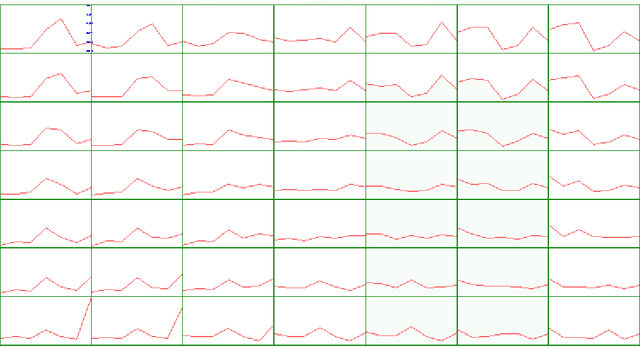
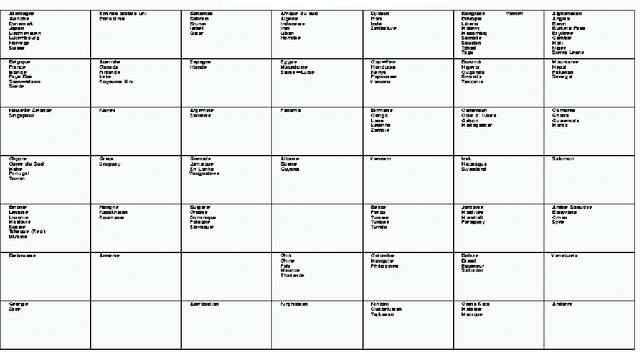
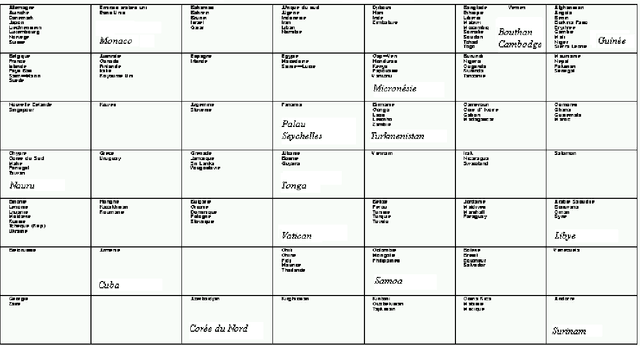

Nous montrons comment il est possible d'utiliser l'algorithme d'auto organisation de Kohonen pour traiter des donn\'ees avec valeurs manquantes et estimer ces derni\`eres. Apr\`es un rappel m\'ethodologique, nous illustrons notre propos \`a partir de trois applications \`a des donn\'ees r\'eelles. ----- We show how it is possible to use the Kohonen self-organizing algorithm to deal with data which contain missing values and to estimate them. After a methodological recall, we illustrate our purpose from three real databases applications.
Consumer Profile Identification and Allocation
Apr 03, 2007
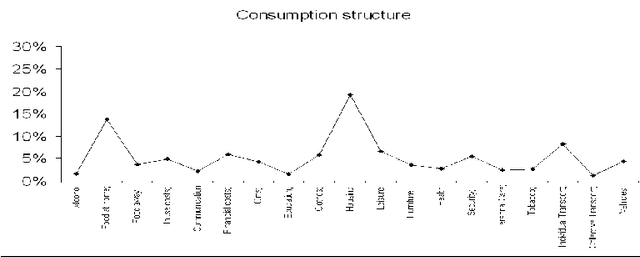


We propose an easy-to-use methodology to allocate one of the groups which have been previously built from a complete learning data base, to new individuals. The learning data base contains continuous and categorical variables for each individual. The groups (clusters) are built by using only the continuous variables and described with the help of the categorical ones. For the new individuals, only the categorical variables are available, and it is necessary to define a model which computes the probabilities to belong to each of the clusters, by using only the categorical variables. Then this model provides a decision rule to assign the new individuals and gives an efficient tool to decision-makers. This tool is shown to be very efficient for customers allocation in consumer clusters for marketing purposes, for example.
Missing values : processing with the Kohonen algorithm
Jan 05, 2007

The processing of data which contain missing values is a complicated and always awkward problem, when the data come from real-world contexts. In applications, we are very often in front of observations for which all the values are not available, and this can occur for many reasons: typing errors, fields left unanswered in surveys, etc. Most of the statistical software (as SAS for example) simply suppresses incomplete observations. It has no practical consequence when the data are very numerous. But if the number of remaining data is too small, it can remove all significance to the results. To avoid suppressing data in that way, it is possible to replace a missing value with the mean value of the corresponding variable, but this approximation can be very bad when the variable has a large variance. So it is very worthwhile seeing that the Kohonen algorithm (as well as the Forgy algorithm) perfectly deals with data with missing values, without having to estimate them beforehand. We are particularly interested in the Kohonen algorithm for its visualization properties.
On the use of self-organizing maps to accelerate vector quantization
Jan 04, 2007



Self-organizing maps (SOM) are widely used for their topology preservation property: neighboring input vectors are quantified (or classified) either on the same location or on neighbor ones on a predefined grid. SOM are also widely used for their more classical vector quantization property. We show in this paper that using SOM instead of the more classical Simple Competitive Learning (SCL) algorithm drastically increases the speed of convergence of the vector quantization process. This fact is demonstrated through extensive simulations on artificial and real examples, with specific SOM (fixed and decreasing neighborhoods) and SCL algorithms.
* A la suite de la conference ESANN 1999
Working times in atypical forms of employment: the special case of part-time work
Nov 14, 2006



In the present article, we attempt to devise a typology of forms of part-time employment by applying a widely used neuronal methodology called Kohonen maps. Starting out with data that we describe using category-specific variables, we show how it is possible to represent observations and the modalities of the variables that define them simultaneously, on a single map. This allows us to ascertain, and to try to describe, the main categories of part-time employment.
* Chapitre 5, \`{a} la suite de la conf\'{e}rence ACSEG 2001 \`{a} Rennes
Cartes auto-organisées pour l'analyse exploratoire de données et la visualisation
Nov 14, 2006



This paper shows how to use the Kohonen algorithm to represent multidimensional data, by exploiting the self-organizing property. It is possible to get such maps as well for quantitative variables as for qualitative ones, or for a mixing of both. The contents of the paper come from various works by SAMOS-MATISSE members, in particular by E. de Bodt, B. Girard, P. Letr\'{e}my, S. Ibbou, P. Rousset. Most of the examples have been studied with the computation routines written by Patrick Letr\'{e}my, with the language IML-SAS, which are available on the WEB page http://samos.univ-paris1.fr.
* Article de synth\`{e}se sur les applications de l'algorithme de Kohonen pour la visualisation et l'analyse de donn\'{e}es