 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynAlign: Unsupervised Dynamic Taxonomy Alignment for Cross-Domain Segmentation
Jan 27, 2025



Current unsupervised domain adaptation (UDA) methods for semantic segmentation typically assume identical class labels between the source and target domains. This assumption ignores the label-level domain gap, which is common in real-world scenarios, thus limiting their ability to identify finer-grained or novel categories without requiring extensive manual annotation. A promising direction to address this limitation lies in recent advancements in foundation models, which exhibit strong generalization abilities due to their rich prior knowledge. However, these models often struggle with domain-specific nuances and underrepresented fine-grained categories. To address these challenges, we introduce DynAlign, a framework that integrates UDA with foundation models to bridge both the image-level and label-level domain gaps. Our approach leverages prior semantic knowledge to align source categories with target categories that can be novel, more fine-grained, or named differently (e.g., vehicle to {car, truck, bus}). Foundation models are then employed for precise segmentation and category reassignment. To further enhance accuracy, we propose a knowledge fusion approach that dynamically adapts to varying scene contexts. DynAlign generates accurate predictions in a new target label space without requiring any manual annotations, allowing seamless adaptation to new taxonomies through either model retraining or direct inference. Experiments on the street scene semantic segmentation benchmarks GTA to Mapillary Vistas and GTA to IDD validate the effectiveness of our approach, achieving a significant improvement over existing methods. Our code will be publicly available.
Recall and Refine: A Simple but Effective Source-free Open-set Domain Adaptation Framework
Nov 19, 2024Open-set Domain Adaptation (OSDA) aims to adapt a model from a labeled source domain to an unlabeled target domain, where novel classes - also referred to as target-private unknown classes - are present. Source-free Open-set Domain Adaptation (SF-OSDA) methods address OSDA without accessing labeled source data, making them particularly relevant under privacy constraints. However, SF-OSDA presents significant challenges due to distribution shifts and the introduction of novel classes. Existing SF-OSDA methods typically rely on thresholding the prediction entropy of a sample to identify it as either a known or unknown class but fail to explicitly learn discriminative features for the target-private unknown classes. We propose Recall and Refine (RRDA), a novel SF-OSDA framework designed to address these limitations by explicitly learning features for target-private unknown classes. RRDA employs a two-step process. First, we enhance the model's capacity to recognize unknown classes by training a target classifier with an additional decision boundary, guided by synthetic samples generated from target domain features. This enables the classifier to effectively separate known and unknown classes. In the second step, we adapt the entire model to the target domain, addressing both domain shifts and improving generalization to unknown classes. Any off-the-shelf source-free domain adaptation method (e.g., SHOT, AaD) can be seamlessly integrated into our framework at this stage. Extensive experiments on three benchmark datasets demonstrate that RRDA significantly outperforms existing SF-OSDA and OSDA methods.
Efficient Unsupervised Domain Adaptation Regression for Spatial-Temporal Air Quality Sensor Fusion
Nov 11, 2024



The deployment of affordable Internet of Things (IoT) sensors for air pollution monitoring has increased in recent years due to their scalability and cost-effectiveness. However, accurately calibrating these sensors in uncontrolled environments remains a significant challenge. While expensive reference sensors can provide accurate ground truth data, they are often deployed on a limited scale due to high costs, leading to a scarcity of labeled data. In diverse urban environments, data distributions constantly shift due to varying factors such as traffic patterns, industrial activities, and weather conditions, which impact sensor readings. Consequently, traditional machine learning models -- despite their increasing deployment for environmental sensor calibration -- often struggle to provide reliable pollutant measurements across different locations due to domain shifts. To address these challenges, we propose a novel unsupervised domain adaptation (UDA) method specifically tailored for regression tasks on graph-structured data. Our approach leverages Graph Neural Networks (GNNs) to model the relationships between sensors. To effectively capture critical spatial-temporal interactions, we incorporate spatial-temporal graph neural networks (STGNNs), which extend GNNs by incorporating temporal dynamics. To handle the resulting larger embeddings, we propose a domain adaptation method using a closed-form solution inspired by the Tikhonov-regularized least-squares problem. This method leverages Cholesky decomposition and power iteration to align the subspaces between source and target domains. By aligning these subspaces, our approach allows low-cost IoT sensors to learn calibration parameters from expensive reference sensors. This facilitates reliable pollutant measurements in new locations without the need for additional costly equipment.
IM-Context: In-Context Learning for Imbalanced Regression Tasks
May 28, 2024



Regression models often fail to generalize effectively in regions characterized by highly imbalanced label distributions. Previous methods for deep imbalanced regression rely on gradient-based weight updates, which tend to overfit in underrepresented regions. This paper proposes a paradigm shift towards in-context learning as an effective alternative to conventional in-weight learning methods, particularly for addressing imbalanced regression. In-context learning refers to the ability of a model to condition itself, given a prompt sequence composed of in-context samples (input-label pairs) alongside a new query input to generate predictions, without requiring any parameter updates. In this paper, we study the impact of the prompt sequence on the model performance from both theoretical and empirical perspectives. We emphasize the importance of localized context in reducing bias within regions of high imbalance. Empirical evaluations across a variety of real-world datasets demonstrate that in-context learning substantially outperforms existing in-weight learning methods in scenarios with high levels of imbalance.
Uncertainty-Guided Alignment for Unsupervised Domain Adaptation in Regression
Jan 26, 2024



Unsupervised Domain Adaptation for Regression (UDAR) aims to adapt a model from a labeled source domain to an unlabeled target domain for regression tasks. Recent successful works in UDAR mostly focus on subspace alignment, involving the alignment of a selected subspace within the entire feature space. This contrasts with the feature alignment methods used for classification, which aim at aligning the entire feature space and have proven effective but are less so in regression settings. Specifically, while classification aims to identify separate clusters across the entire embedding dimension, regression induces less structure in the data representation, necessitating additional guidance for efficient alignment. In this paper, we propose an effective method for UDAR by incorporating guidance from uncertainty. Our approach serves a dual purpose: providing a measure of confidence in predictions and acting as a regularization of the embedding space. Specifically, we leverage the Deep Evidential Learning framework, which outputs both predictions and uncertainties for each input sample. We propose aligning the parameters of higher-order evidential distributions between the source and target domains using traditional alignment methods at the feature or posterior level. Additionally, we propose to augment the feature space representation by mixing source samples with pseudo-labeled target samples based on label similarity. This cross-domain mixing strategy produces more realistic samples than random mixing and introduces higher uncertainty, facilitating further alignment. We demonstrate the effectiveness of our approach on four benchmarks for UDAR, on which we outperform existing methods.
Semi-Supervised Health Index Monitoring with Feature Generation and Fusion
Dec 05, 2023



The Health Index (HI) is crucial for evaluating system health, aiding tasks like anomaly detection and predicting remaining useful life for systems demanding high safety and reliability. Tight monitoring is crucial for achieving high precision at a lower cost, with applications such as spray coating. Obtaining HI labels in real-world applications is often cost-prohibitive, requiring continuous, precise health measurements. Therefore, it is more convenient to leverage run-to failure datasets that may provide potential indications of machine wear condition, making it necessary to apply semi-supervised tools for HI construction. In this study, we adapt the Deep Semi-supervised Anomaly Detection (DeepSAD) method for HI construction. We use the DeepSAD embedding as a condition indicators to address interpretability challenges and sensitivity to system-specific factors. Then, we introduce a diversity loss to enrich condition indicators. We employ an alternating projection algorithm with isotonic constraints to transform the DeepSAD embedding into a normalized HI with an increasing trend. Validation on the PHME 2010 milling dataset, a recognized benchmark with ground truth HIs demonstrates meaningful HIs estimations. Our methodology is then applied to monitor wear states of thermal spray coatings using high-frequency voltage. Our contributions create opportunities for more accessible and reliable HI estimation, particularly in cases where obtaining ground truth HI labels is unfeasible.
SimMMDG: A Simple and Effective Framework for Multi-modal Domain Generalization
Oct 30, 2023In real-world scenarios, achieving domain generalization (DG) presents significant challenges as models are required to generalize to unknown target distributions. Generalizing to unseen multi-modal distributions poses even greater difficulties due to the distinct properties exhibited by different modalities. To overcome the challenges of achieving domain generalization in multi-modal scenarios, we propose SimMMDG, a simple yet effective multi-modal DG framework. We argue that mapping features from different modalities into the same embedding space impedes model generalization. To address this, we propose splitting the features within each modality into modality-specific and modality-shared components. We employ supervised contrastive learning on the modality-shared features to ensure they possess joint properties and impose distance constraints on modality-specific features to promote diversity. In addition, we introduce a cross-modal translation module to regularize the learned features, which can also be used for missing-modality generalization. We demonstrate that our framework is theoretically well-supported and achieves strong performance in multi-modal DG on the EPIC-Kitchens dataset and the novel Human-Animal-Cartoon (HAC) dataset introduced in this paper. Our source code and HAC dataset are available at https://github.com/donghao51/SimMMDG.
DARE-GRAM : Unsupervised Domain Adaptation Regression by Aligning Inverse Gram Matrices
Mar 23, 2023Unsupervised Domain Adaptation Regression (DAR) aims to bridge the domain gap between a labeled source dataset and an unlabelled target dataset for regression problems. Recent works mostly focus on learning a deep feature encoder by minimizing the discrepancy between source and target features. In this work, we present a different perspective for the DAR problem by analyzing the closed-form ordinary least square~(OLS) solution to the linear regressor in the deep domain adaptation context. Rather than aligning the original feature embedding space, we propose to align the inverse Gram matrix of the features, which is motivated by its presence in the OLS solution and the Gram matrix's ability to capture the feature correlations. Specifically, we propose a simple yet effective DAR method which leverages the pseudo-inverse low-rank property to align the scale and angle in a selected subspace generated by the pseudo-inverse Gram matrix of the two domains. We evaluate our method on three domain adaptation regression benchmarks. Experimental results demonstrate that our method achieves state-of-the-art performance. Our code is available at https://github.com/ismailnejjar/DARE-GRAM.
Domain Adaptation via Alignment of Operation Profile for Remaining Useful Lifetime Prediction
Feb 03, 2023Effective Prognostics and Health Management (PHM) relies on accurate prediction of the Remaining Useful Life (RUL). Data-driven RUL prediction techniques rely heavily on the representativeness of the available time-to-failure trajectories. Therefore, these methods may not perform well when applied to data from new units of a fleet that follow different operating conditions than those they were trained on. This is also known as domain shifts. Domain adaptation (DA) methods aim to address the domain shift problem by extracting domain invariant features. However, DA methods do not distinguish between the different phases of operation, such as steady states or transient phases. This can result in misalignment due to under- or over-representation of different operation phases. This paper proposes two novel DA approaches for RUL prediction based on an adversarial domain adaptation framework that considers the different phases of the operation profiles separately. The proposed methodologies align the marginal distributions of each phase of the operation profile in the source domain with its counterpart in the target domain. The effectiveness of the proposed methods is evaluated using the New Commercial Modular Aero-Propulsion System (N-CMAPSS) dataset, where sub-fleets of turbofan engines operating in one of the three different flight classes (short, medium, and long) are treated as separate domains. The experimental results show that the proposed methods improve the accuracy of RUL predictions compared to current state-of-the-art DA methods.
Injecting Knowledge in Data-driven Vehicle Trajectory Predictors
Mar 08, 2021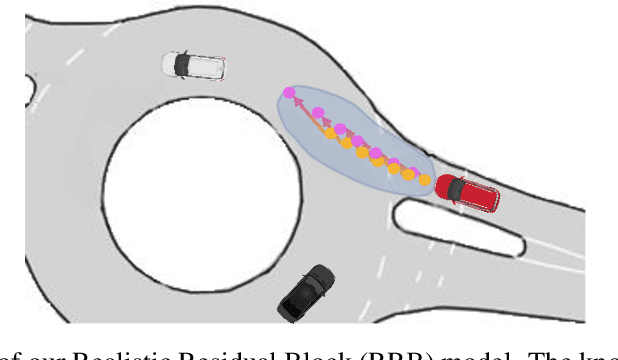
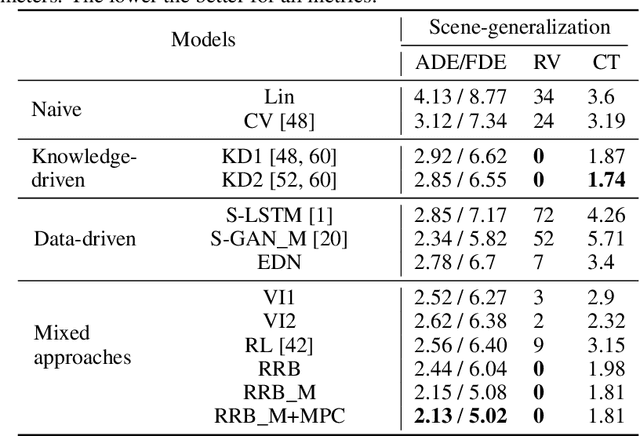
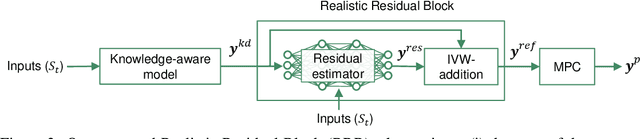
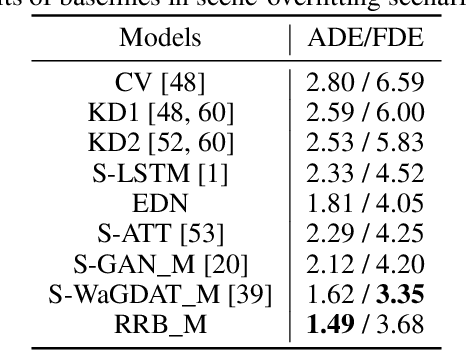
Vehicle trajectory prediction tasks have been commonly tackled from two distinct perspectives: either with knowledge-driven methods or more recently with data-driven ones. On the one hand, we can explicitly implement domain-knowledge or physical priors such as anticipating that vehicles will follow the middle of the roads. While this perspective leads to feasible outputs, it has limited performance due to the difficulty to hand-craft complex interactions in urban environments. On the other hand, recent works use data-driven approaches which can learn complex interactions from the data leading to superior performance. However, generalization, \textit{i.e.}, having accurate predictions on unseen data, is an issue leading to unrealistic outputs. In this paper, we propose to learn a "Realistic Residual Block" (RRB), which effectively connects these two perspectives. Our RRB takes any off-the-shelf knowledge-driven model and finds the required residuals to add to the knowledge-aware trajectory. Our proposed method outputs realistic predictions by confining the residual range and taking into account its uncertainty. We also constrain our output with Model Predictive Control (MPC) to satisfy kinematic constraints. Using a publicly available dataset, we show that our method outperforms previous works in terms of accuracy and generalization to new scenes. We will release our code and data split here: https://github.com/vita-epfl/RRB.