 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViroBench: Benchmarking Nucleotide Foundation Models on Viral Genomics Tasks
May 25, 2026Nucleotide sequences constitute the fundamental genetic basis of biological systems, rendering viral genomic analysis critical for biomedical advancement. Despite progress in biological foundation models, specifically nucleotide foundation models (NFMs), the field lacks a unified standard for viral genomics to facilitate community development and enforce biosecurity constraints. To address this, we introduce ViroBench, the first comprehensive and large-scale benchmark specifically designed for NFMs in viral settings. ViroBench evaluates models across two critical dimensions: biological understanding and latent biosecurity risk, covering 18 diverse scenarios within 4 task types. Extensive evaluation of 66 NFMs across diverse architectures yields three critical conclusions. Firstly, NFMs exhibit a performance degradation in biological understanding under phylogenetic and temporal shifts, indicating weak extrapolation capabilities. Secondly, generation tasks reveal a decoupling between statistical likelihood and biological functional validity, posing latent biosecurity risks. Thirdly, controlled ablation studies reveal that taxonomic diversity in pretraining data outweighs parameter scale. Specifically, a lightweight baseline trained on diverse data achieves a 67.5% performance gain over its original model. Overall, ViroBench provides interpretable, diagnostic evaluations and a reproducible measurement framework for future research on viral nucleotide foundation models. The datasets and code are publicly available at https://github.com/QIANJINYDX/ViroBench.
Knowledge-to-Verification: Exploring RLVR for LLMs in Knowledge-Intensive Domains
May 18, 2026Reinforcement learning with verifiable rewards (RLVR) has demonstrated promising potential to enhance the reasoning capabilities of large language models (LLMs) in domains such as mathematics and coding. However, its applications on knowledge-intensive domains have not been effectively explored due to the scarcity of high-quality verifiable data. Furthermore, current RLVR focuses solely on the correctness of final answers, leading to the limitations of flawed reasoning and sparse reward signals. In this work, we propose Knowledge-to-Verification (K2V), a framework that extends RLVR to knowledge-intensive domains through automated verifiable data synthesis, while enabling verification of the LLM's reasoning process. Extensive experiments demonstrate that K2V enhances the reasoning of LLM in knowledge-intensive domains without significantly compromising the model's general capabilities. This study also suggests that integrating automated data synthesis with reasoning verification is a promising direction to enhance model capabilities in these broader domains. Code is available at https://github.com/SeedScientist/K2V.
Advanced Multi-Microscopic Views Cell Semi-supervised Segmentation
Mar 21, 2023Although deep learning (DL) shows powerful potential in cell segmentation tasks, it suffers from poor generalization as DL-based methods originally simplified cell segmentation in detecting cell membrane boundary, lacking prominent cellular structures to position overall differentiating. Moreover, the scarcity of annotated cell images limits the performance of DL models. Segmentation limitations of a single category of cell make massive practice difficult, much less, with varied modalities. In this paper, we introduce a novel semi-supervised cell segmentation method called Multi-Microscopic-view Cell semi-supervised Segmentation (MMCS), which can train cell segmentation models utilizing less labeled multi-posture cell images with different microscopy well. Technically, MMCS consists of Nucleus-assisted global recognition, Self-adaptive diameter filter, and Temporal-ensembling models. Nucleus-assisted global recognition adds additional cell nucleus channel to improve the global distinguishing performance of fuzzy cell membrane boundaries even when cells aggregate. Besides, self-adapted cell diameter filter can help separate multi-resolution cells with different morphology properly. It further leverages the temporal-ensembling models to improve the semi-supervised training process, achieving effective training with less labeled data. Additionally, optimizing the weight of unlabeled loss contributed to total loss also improve the model performance. Evaluated on the Tuning Set of NeurIPS 2022 Cell Segmentation Challenge (NeurIPS CellSeg), MMCS achieves an F1-score of 0.8239 and the running time for all cases is within the time tolerance.
Transferable Active Grasping and Real Embodied Dataset
Apr 28, 2020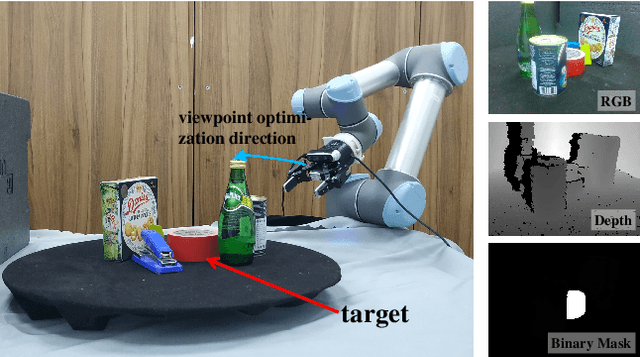



Grasping in cluttered scenes is challenging for robot vision systems, as detection accuracy can be hindered by partial occlusion of objects. We adopt a reinforcement learning (RL) framework and 3D vision architectures to search for feasible viewpoints for grasping by the use of hand-mounted RGB-D cameras. To overcome the disadvantages of photo-realistic environment simulation, we propose a large-scale dataset called Real Embodied Dataset (RED), which includes full-viewpoint real samples on the upper hemisphere with amodal annotation and enables a simulator that has real visual feedback. Based on this dataset, a practical 3-stage transferable active grasping pipeline is developed, that is adaptive to unseen clutter scenes. In our pipeline, we propose a novel mask-guided reward to overcome the sparse reward issue in grasping and ensure category-irrelevant behavior. The grasping pipeline and its possible variants are evaluated with extensive experiments both in simulation and on a real-world UR-5 robotic arm.