 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Active Grasping and Real Embodied Dataset
Paper and Code
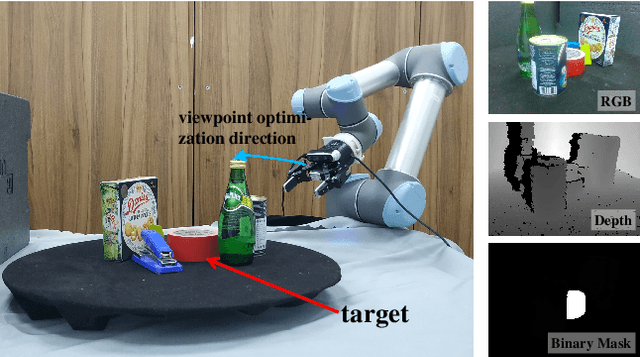



Grasping in cluttered scenes is challenging for robot vision systems, as detection accuracy can be hindered by partial occlusion of objects. We adopt a reinforcement learning (RL) framework and 3D vision architectures to search for feasible viewpoints for grasping by the use of hand-mounted RGB-D cameras. To overcome the disadvantages of photo-realistic environment simulation, we propose a large-scale dataset called Real Embodied Dataset (RED), which includes full-viewpoint real samples on the upper hemisphere with amodal annotation and enables a simulator that has real visual feedback. Based on this dataset, a practical 3-stage transferable active grasping pipeline is developed, that is adaptive to unseen clutter scenes. In our pipeline, we propose a novel mask-guided reward to overcome the sparse reward issue in grasping and ensure category-irrelevant behavior. The grasping pipeline and its possible variants are evaluated with extensive experiments both in simulation and on a real-world UR-5 robotic arm.