 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJOLO-GCN: Mining Joint-Centered Light-Weight Information for Skeleton-Based Action Recognition
Nov 16, 2020
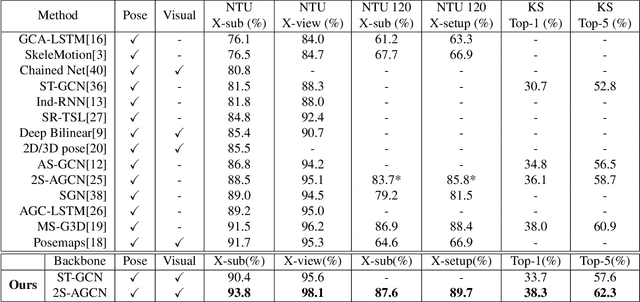
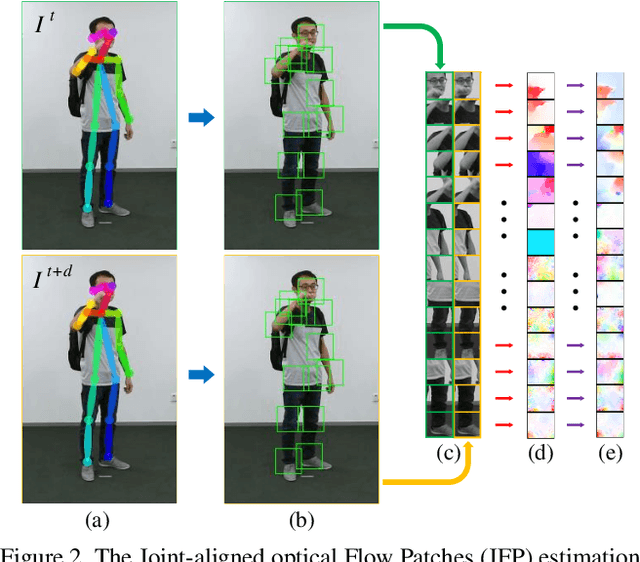

Skeleton-based action recognition has attracted research attentions in recent years. One common drawback in currently popular skeleton-based human action recognition methods is that the sparse skeleton information alone is not sufficient to fully characterize human motion. This limitation makes several existing methods incapable of correctly classifying action categories which exhibit only subtle motion differences. In this paper, we propose a novel framework for employing human pose skeleton and joint-centered light-weight information jointly in a two-stream graph convolutional network, namely, JOLO-GCN. Specifically, we use Joint-aligned optical Flow Patches (JFP) to capture the local subtle motion around each joint as the pivotal joint-centered visual information. Compared to the pure skeleton-based baseline, this hybrid scheme effectively boosts performance, while keeping the computational and memory overheads low. Experiments on the NTU RGB+D, NTU RGB+D 120, and the Kinetics-Skeleton dataset demonstrate clear accuracy improvements attained by the proposed method over the state-of-the-art skeleton-based methods.
Adversarial 3D Human Pose Estimation via Multimodal Depth Supervision
Sep 21, 2018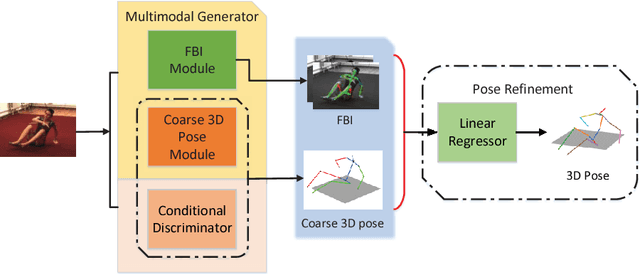

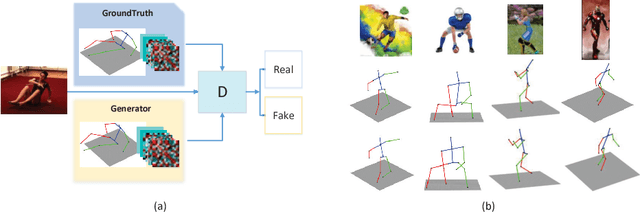
In this paper, a novel deep-learning based framework is proposed to infer 3D human poses from a single image. Specifically, a two-phase approach is developed. We firstly utilize a generator with two branches for the extraction of explicit and implicit depth information respectively. During the training process, an adversarial scheme is also employed to further improve the performance. The implicit and explicit depth information with the estimated 2D joints generated by a widely used estimator, in the second step, are together fed into a deep 3D pose regressor for the final pose generation. Our method achieves MPJPE of 58.68mm on the ECCV2018 3D Human Pose Estimation Challenge.