 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Reviews Matter for Recommendations in the Era of Large Language Models?
Dec 15, 2025



With the advent of large language models (LLMs), the landscape of recommender systems is undergoing a significant transformation. Traditionally, user reviews have served as a critical source of rich, contextual information for enhancing recommendation quality. However, as LLMs demonstrate an unprecedented ability to understand and generate human-like text, this raises the question of whether explicit user reviews remain essential in the era of LLMs. In this paper, we provide a systematic investigation of the evolving role of text reviews in recommendation by comparing deep learning methods and LLM approaches. Particularly, we conduct extensive experiments on eight public datasets with LLMs and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We further introduce a benchmarking evaluation framework for review-aware recommender systems, RAREval, to comprehensively assess the contribution of textual reviews to the recommendation performance of review-aware recommender systems. Our framework examines various scenarios, including the removal of some or all textual reviews, random distortion, as well as recommendation performance in data sparsity and cold-start user settings. Our findings demonstrate that LLMs are capable of functioning as effective review-aware recommendation engines, generally outperforming traditional deep learning approaches, particularly in scenarios characterized by data sparsity and cold-start conditions. In addition, the removal of some or all textual reviews and random distortion does not necessarily lead to declines in recommendation accuracy. These findings motivate a rethinking of how user preference from text reviews can be more effectively leveraged. All code and supplementary materials are available at: https://github.com/zhytk/RAREval-data-processing.
Enhancing Incomplete Multi-modal Brain Tumor Segmentation with Intra-modal Asymmetry and Inter-modal Dependency
Jun 14, 2024



Deep learning-based brain tumor segmentation (BTS) models for multi-modal MRI images have seen significant advancements in recent years. However, a common problem in practice is the unavailability of some modalities due to varying scanning protocols and patient conditions, making segmentation from incomplete MRI modalities a challenging issue. Previous methods have attempted to address this by fusing accessible multi-modal features, leveraging attention mechanisms, and synthesizing missing modalities using generative models. However, these methods ignore the intrinsic problems of medical image segmentation, such as the limited availability of training samples, particularly for cases with tumors. Furthermore, these methods require training and deploying a specific model for each subset of missing modalities. To address these issues, we propose a novel approach that enhances the BTS model from two perspectives. Firstly, we introduce a pre-training stage that generates a diverse pre-training dataset covering a wide range of different combinations of tumor shapes and brain anatomy. Secondly, we propose a post-training stage that enables the model to reconstruct missing modalities in the prediction results when only partial modalities are available. To achieve the pre-training stage, we conceptually decouple the MRI image into two parts: `anatomy' and `tumor'. We pre-train the BTS model using synthesized data generated from the anatomy and tumor parts across different training samples. ... Extensive experiments demonstrate that our proposed method significantly improves the performance over the baseline and achieves new state-of-the-art results on three brain tumor segmentation datasets: BRATS2020, BRATS2018, and BRATS2015.
Diffusion-EXR: Controllable Review Generation for Explainable Recommendation via Diffusion Models
Dec 24, 2023



Denoising Diffusion Probabilistic Model (DDPM) has shown great competence in image and audio generation tasks. However, there exist few attempts to employ DDPM in the text generation, especially review generation under recommendation systems. Fueled by the predicted reviews explainability that justifies recommendations could assist users better understand the recommended items and increase the transparency of recommendation system, we propose a Diffusion Model-based Review Generation towards EXplainable Recommendation named Diffusion-EXR. Diffusion-EXR corrupts the sequence of review embeddings by incrementally introducing varied levels of Gaussian noise to the sequence of word embeddings and learns to reconstruct the original word representations in the reverse process. The nature of DDPM enables our lightweight Transformer backbone to perform excellently in the recommendation review generation task. Extensive experimental results have demonstrated that Diffusion-EXR can achieve state-of-the-art review generation for recommendation on two publicly available benchmark datasets.
A*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019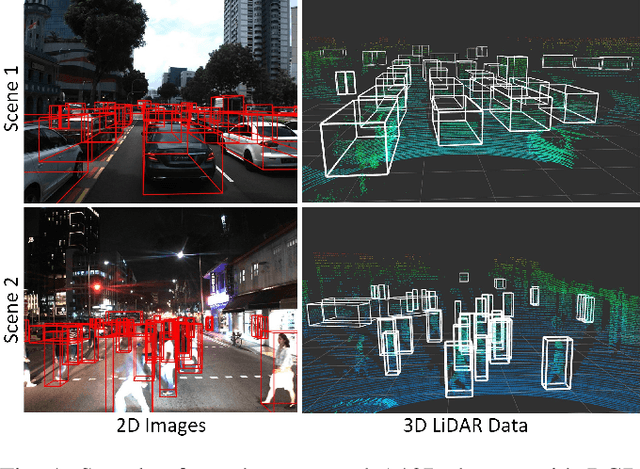
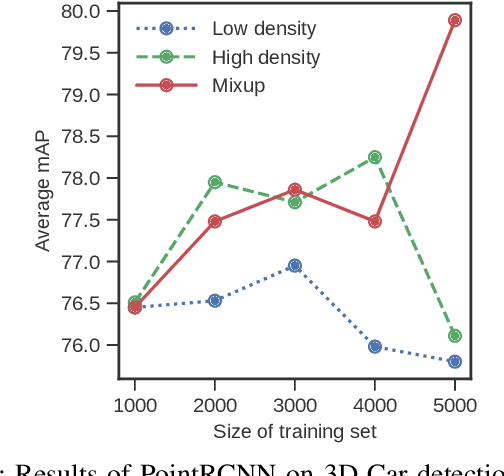
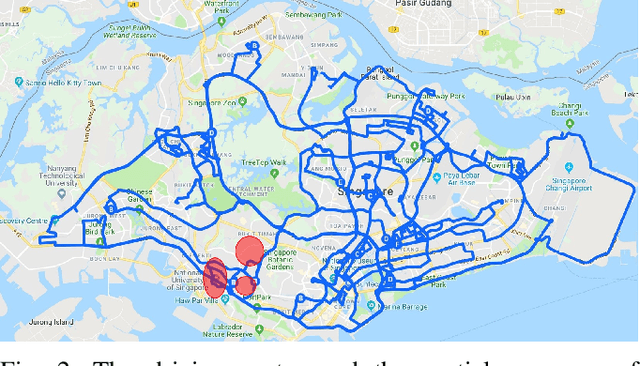
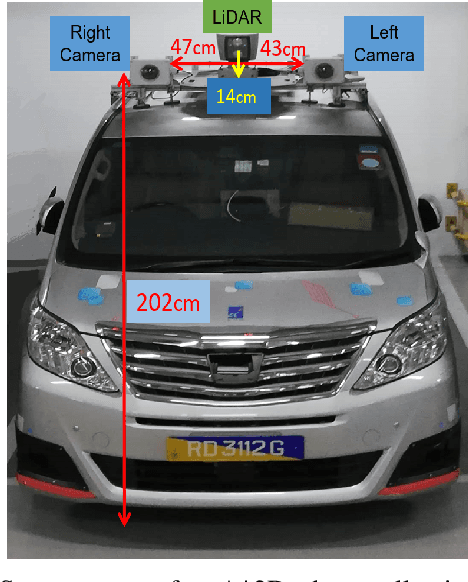
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.