Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInertial Proximal Deep Learning Alternating Minimization for Efficient Neutral Network Training
Paper and Code
Jan 30, 2021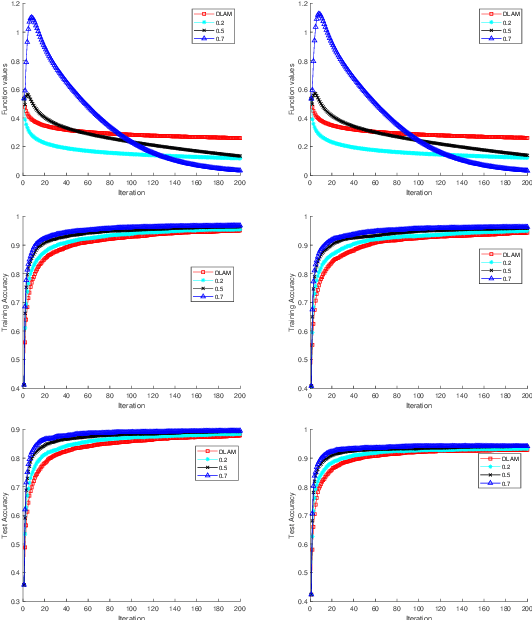
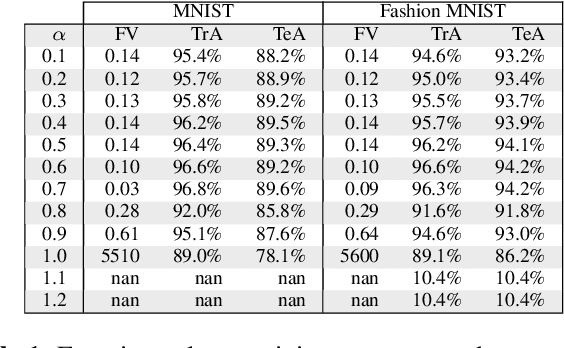
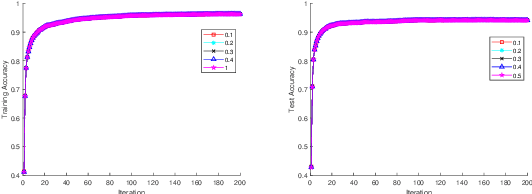
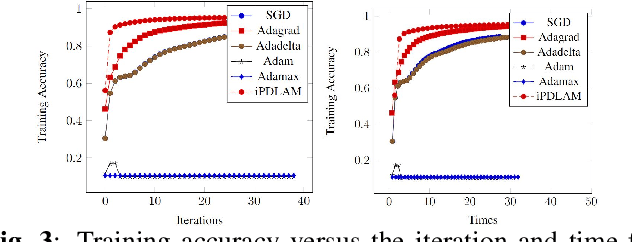
In recent years, the Deep Learning Alternating Minimization (DLAM), which is actually the alternating minimization applied to the penalty form of the deep neutral networks training, has been developed as an alternative algorithm to overcome several drawbacks of Stochastic Gradient Descent (SGD) algorithms. This work develops an improved DLAM by the well-known inertial technique, namely iPDLAM, which predicts a point by linearization of current and last iterates. To obtain further training speed, we apply a warm-up technique to the penalty parameter, that is, starting with a small initial one and increasing it in the iterations. Numerical results on real-world datasets are reported to demonstrate the efficiency of our proposed algorithm.
View paper on