 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDELTA: Dynamically Optimizing GPU Memory beyond Tensor Recomputation
Paper and Code
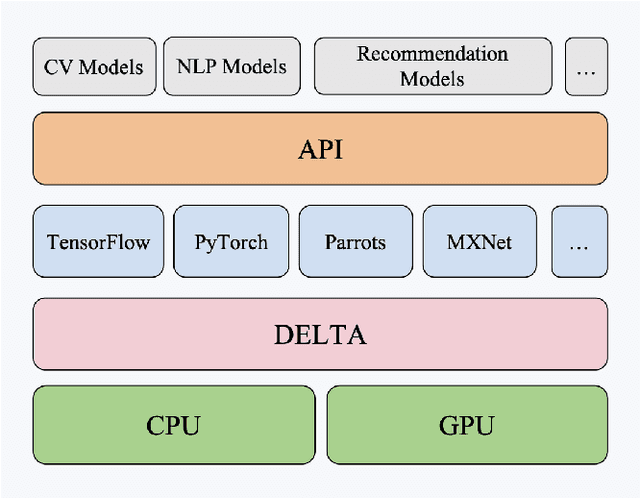

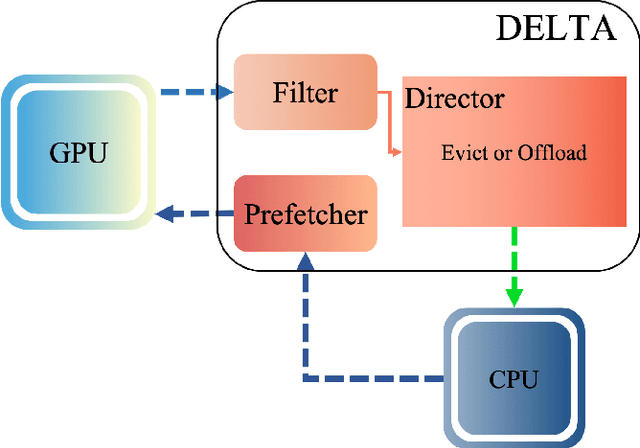
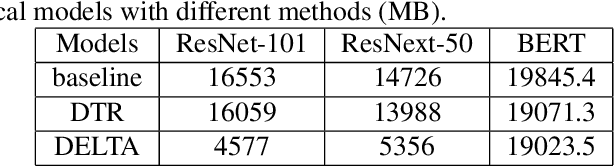
The further development of deep neural networks is hampered by the limited GPU memory resource. Therefore, the optimization of GPU memory resources is highly demanded. Swapping and recomputation are commonly applied to make better use of GPU memory in deep learning. However, as an emerging domain, several challenges remain:1)The efficiency of recomputation is limited for both static and dynamic methods. 2)Swapping requires offloading parameters manually, which incurs a great time cost. 3) There is no such dynamic and fine-grained method that involves tensor swapping together with tensor recomputation nowadays. To remedy the above issues, we propose a novel scheduler manager named DELTA(Dynamic tEnsor offLoad and recompuTAtion). To the best of our knowledge, we are the first to make a reasonable dynamic runtime scheduler on the combination of tensor swapping and tensor recomputation without user oversight. In DELTA, we propose a filter algorithm to select the optimal tensors to be released out of GPU memory and present a director algorithm to select a proper action for each of these tensors. Furthermore, prefetching and overlapping are deliberately considered to overcome the time cost caused by swapping and recomputing tensors. Experimental results show that DELTA not only saves 40%-70% of GPU memory, surpassing the state-of-the-art method to a great extent but also gets comparable convergence results as the baseline with acceptable time delay. Also, DELTA gains 2.04$\times$ maximum batchsize when training ResNet-50 and 2.25$\times$ when training ResNet-101 compared with the baseline. Besides, comparisons between the swapping cost and recomputation cost in our experiments demonstrate the importance of making a reasonable dynamic scheduler on tensor swapping and tensor recomputation, which refutes the arguments in some related work that swapping should be the first and best choice.