 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTOS: Layout-controllable Text-Object Synthesis via Adaptive Cross-attention Fusions
Apr 21, 2024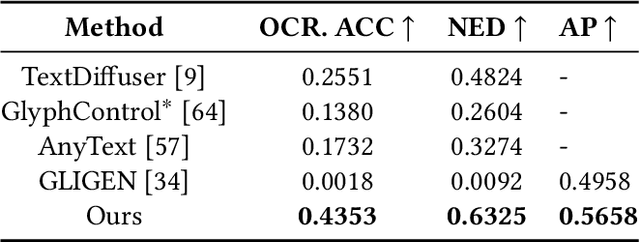
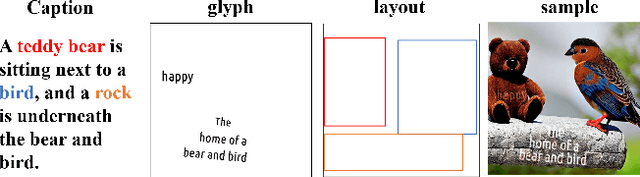


Controllable text-to-image generation synthesizes visual text and objects in images with certain conditions, which are frequently applied to emoji and poster generation. Visual text rendering and layout-to-image generation tasks have been popular in controllable text-to-image generation. However, each of these tasks typically focuses on single modality generation or rendering, leaving yet-to-be-bridged gaps between the approaches correspondingly designed for each of the tasks. In this paper, we combine text rendering and layout-to-image generation tasks into a single task: layout-controllable text-object synthesis (LTOS) task, aiming at synthesizing images with object and visual text based on predefined object layout and text contents. As compliant datasets are not readily available for our LTOS task, we construct a layout-aware text-object synthesis dataset, containing elaborate well-aligned labels of visual text and object information. Based on the dataset, we propose a layout-controllable text-object adaptive fusion (TOF) framework, which generates images with clear, legible visual text and plausible objects. We construct a visual-text rendering module to synthesize text and employ an object-layout control module to generate objects while integrating the two modules to harmoniously generate and integrate text content and objects in images. To better the image-text integration, we propose a self-adaptive cross-attention fusion module that helps the image generation to attend more to important text information. Within such a fusion module, we use a self-adaptive learnable factor to learn to flexibly control the influence of cross-attention outputs on image generation. Experimental results show that our method outperforms the state-of-the-art in LTOS, text rendering, and layout-to-image tasks, enabling harmonious visual text rendering and object generation.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.