 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTTA-T: Continual Test-Time Adaptation for Text Understanding via Teacher-Student with a Domain-aware and Generalized Teacher
Dec 20, 2025Text understanding often suffers from domain shifts. To handle testing domains, domain adaptation (DA) is trained to adapt to a fixed and observed testing domain; a more challenging paradigm, test-time adaptation (TTA), cannot access the testing domain during training and online adapts to the testing samples during testing, where the samples are from a fixed domain. We aim to explore a more practical and underexplored scenario, continual test-time adaptation (CTTA) for text understanding, which involves a sequence of testing (unobserved) domains in testing. Current CTTA methods struggle in reducing error accumulation over domains and enhancing generalization to handle unobserved domains: 1) Noise-filtering reduces accumulated errors but discards useful information, and 2) accumulating historical domains enhances generalization, but it is hard to achieve adaptive accumulation. In this paper, we propose a CTTA-T (continual test-time adaptation for text understanding) framework adaptable to evolving target domains: it adopts a teacher-student framework, where the teacher is domain-aware and generalized for evolving domains. To improve teacher predictions, we propose a refine-then-filter based on dropout-driven consistency, which calibrates predictions and removes unreliable guidance. For the adaptation-generalization trade-off, we construct a domain-aware teacher by dynamically accumulating cross-domain semantics via incremental PCA, which continuously tracks domain shifts. Experiments show CTTA-T excels baselines.
TCM-FTP: Fine-Tuning Large Language Models for Herbal Prescription Prediction
Jul 15, 2024



Traditional Chinese medicine (TCM) relies on specific combinations of herbs in prescriptions to treat symptoms and signs, a practice that spans thousands of years. Predicting TCM prescriptions presents a fascinating technical challenge with practical implications. However, this task faces limitations due to the scarcity of high-quality clinical datasets and the intricate relationship between symptoms and herbs. To address these issues, we introduce DigestDS, a new dataset containing practical medical records from experienced experts in digestive system diseases. We also propose a method, TCM-FTP (TCM Fine-Tuning Pre-trained), to leverage pre-trained large language models (LLMs) through supervised fine-tuning on DigestDS. Additionally, we enhance computational efficiency using a low-rank adaptation technique. TCM-FTP also incorporates data augmentation by permuting herbs within prescriptions, capitalizing on their order-agnostic properties. Impressively, TCM-FTP achieves an F1-score of 0.8031, surpassing previous methods significantly. Furthermore, it demonstrates remarkable accuracy in dosage prediction, achieving a normalized mean square error of 0.0604. In contrast, LLMs without fine-tuning perform poorly. Although LLMs have shown capabilities on a wide range of tasks, this work illustrates the importance of fine-tuning for TCM prescription prediction, and we have proposed an effective way to do that.
Resilient Practical Test-Time Adaptation: Soft Batch Normalization Alignment and Entropy-driven Memory Bank
Jan 26, 2024Test-time domain adaptation effectively adjusts the source domain model to accommodate unseen domain shifts in a target domain during inference. However, the model performance can be significantly impaired by continuous distribution changes in the target domain and non-independent and identically distributed (non-i.i.d.) test samples often encountered in practical scenarios. While existing memory bank methodologies use memory to store samples and mitigate non-i.i.d. effects, they do not inherently prevent potential model degradation. To address this issue, we propose a resilient practical test-time adaptation (ResiTTA) method focused on parameter resilience and data quality. Specifically, we develop a resilient batch normalization with estimation on normalization statistics and soft alignments to mitigate overfitting and model degradation. We use an entropy-driven memory bank that accounts for timeliness, the persistence of over-confident samples, and sample uncertainty for high-quality data in adaptation. Our framework periodically adapts the source domain model using a teacher-student model through a self-training loss on the memory samples, incorporating soft alignment losses on batch normalization. We empirically validate ResiTTA across various benchmark datasets, demonstrating state-of-the-art performance.
Deep Clustering with Features from Self-Supervised Pretraining
Jul 27, 2022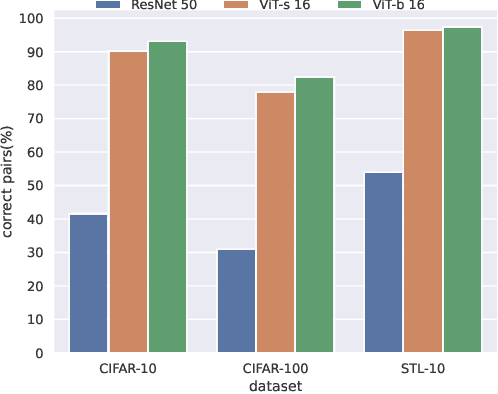
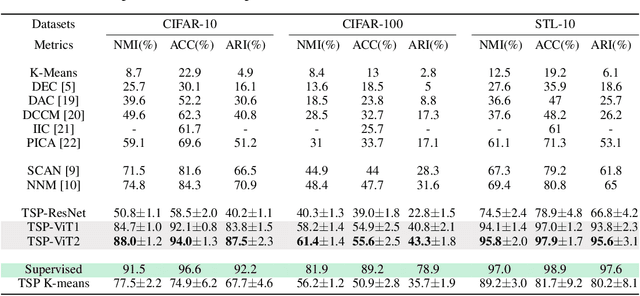

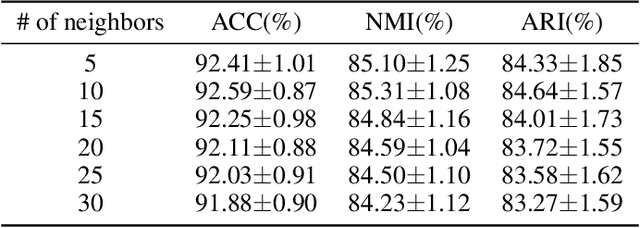
A deep clustering model conceptually consists of a feature extractor that maps data points to a latent space, and a clustering head that groups data points into clusters in the latent space. Although the two components used to be trained jointly in an end-to-end fashion, recent works have proved it beneficial to train them separately in two stages. In the first stage, the feature extractor is trained via self-supervised learning, which enables the preservation of the cluster structures among the data points. To preserve the cluster structures even better, we propose to replace the first stage with another model that is pretrained on a much larger dataset via self-supervised learning. The method is simple and might suffer from domain shift. Nonetheless, we have empirically shown that it can achieve superior clustering performance. When a vision transformer (ViT) architecture is used for feature extraction, our method has achieved clustering accuracy 94.0%, 55.6% and 97.9% on CIFAR-10, CIFAR-100 and STL-10 respectively. The corresponding previous state-of-the-art results are 84.3%, 47.7% and 80.8%. Our code will be available online with the publication of the paper.