 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Clustering with Features from Self-Supervised Pretraining
Paper and Code
Jul 27, 2022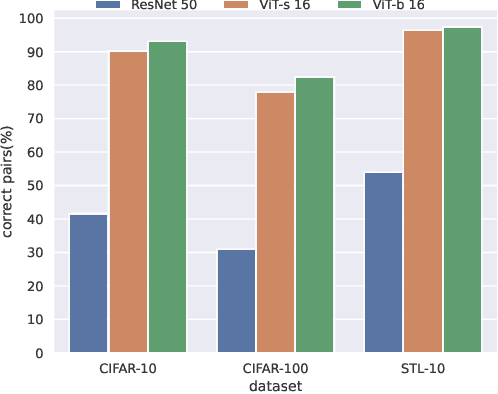
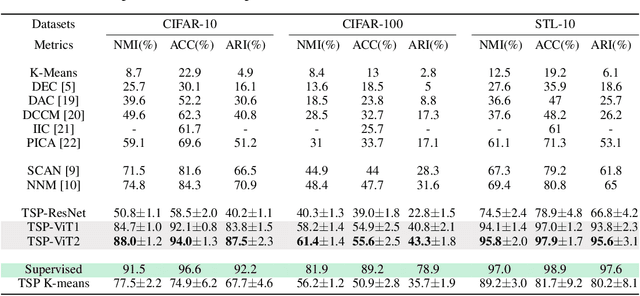

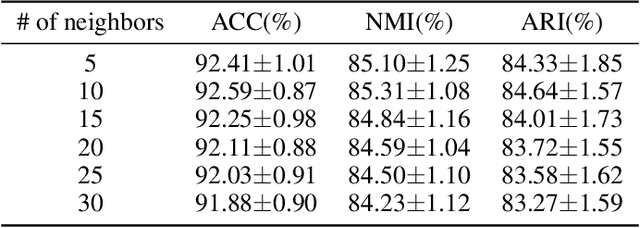
A deep clustering model conceptually consists of a feature extractor that maps data points to a latent space, and a clustering head that groups data points into clusters in the latent space. Although the two components used to be trained jointly in an end-to-end fashion, recent works have proved it beneficial to train them separately in two stages. In the first stage, the feature extractor is trained via self-supervised learning, which enables the preservation of the cluster structures among the data points. To preserve the cluster structures even better, we propose to replace the first stage with another model that is pretrained on a much larger dataset via self-supervised learning. The method is simple and might suffer from domain shift. Nonetheless, we have empirically shown that it can achieve superior clustering performance. When a vision transformer (ViT) architecture is used for feature extraction, our method has achieved clustering accuracy 94.0%, 55.6% and 97.9% on CIFAR-10, CIFAR-100 and STL-10 respectively. The corresponding previous state-of-the-art results are 84.3%, 47.7% and 80.8%. Our code will be available online with the publication of the paper.