 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
Jan 29, 2026The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.
BatonVoice: An Operationalist Framework for Enhancing Controllable Speech Synthesis with Linguistic Intelligence from LLMs
Sep 30, 2025The rise of Large Language Models (LLMs) is reshaping multimodel models, with speech synthesis being a prominent application. However, existing approaches often underutilize the linguistic intelligence of these models, typically failing to leverage their powerful instruction-following capabilities. This limitation hinders the model's ability to follow text instructions for controllable Text-to-Speech~(TTS). To address this, we propose a new paradigm inspired by ``operationalism'' that decouples instruction understanding from speech generation. We introduce BatonVoice, a framework where an LLM acts as a ``conductor'', understanding user instructions and generating a textual ``plan'' -- explicit vocal features (e.g., pitch, energy). A separate TTS model, the ``orchestra'', then generates the speech from these features. To realize this component, we develop BatonTTS, a TTS model trained specifically for this task. Our experiments demonstrate that BatonVoice achieves strong performance in controllable and emotional speech synthesis, outperforming strong open- and closed-source baselines. Notably, our approach enables remarkable zero-shot cross-lingual generalization, accurately applying feature control abilities to languages unseen during post-training. This demonstrates that objectifying speech into textual vocal features can more effectively unlock the linguistic intelligence of LLMs.
Bridging the Capability Gap: Joint Alignment Tuning for Harmonizing LLM-based Multi-Agent Systems
Sep 11, 2025The advancement of large language models (LLMs) has enabled the construction of multi-agent systems to solve complex tasks by dividing responsibilities among specialized agents, such as a planning agent for subgoal generation and a grounding agent for executing tool-use actions. Most existing methods typically fine-tune these agents independently, leading to capability gaps among them with poor coordination. To address this, we propose MOAT, a Multi-Agent Joint Alignment Tuning framework that improves agents collaboration through iterative alignment. MOAT alternates between two key stages: (1) Planning Agent Alignment, which optimizes the planning agent to generate subgoal sequences that better guide the grounding agent; and (2) Grounding Agent Improving, which fine-tunes the grounding agent using diverse subgoal-action pairs generated by the agent itself to enhance its generalization capablity. Theoretical analysis proves that MOAT ensures a non-decreasing and progressively convergent training process. Experiments across six benchmarks demonstrate that MOAT outperforms state-of-the-art baselines, achieving average improvements of 3.1% on held-in tasks and 4.4% on held-out tasks.
Iterative Self-Incentivization Empowers Large Language Models as Agentic Searchers
May 26, 2025Large language models (LLMs) have been widely integrated into information retrieval to advance traditional techniques. However, effectively enabling LLMs to seek accurate knowledge in complex tasks remains a challenge due to the complexity of multi-hop queries as well as the irrelevant retrieved content. To address these limitations, we propose EXSEARCH, an agentic search framework, where the LLM learns to retrieve useful information as the reasoning unfolds through a self-incentivized process. At each step, the LLM decides what to retrieve (thinking), triggers an external retriever (search), and extracts fine-grained evidence (recording) to support next-step reasoning. To enable LLM with this capability, EXSEARCH adopts a Generalized Expectation-Maximization algorithm. In the E-step, the LLM generates multiple search trajectories and assigns an importance weight to each; the M-step trains the LLM on them with a re-weighted loss function. This creates a self-incentivized loop, where the LLM iteratively learns from its own generated data, progressively improving itself for search. We further theoretically analyze this training process, establishing convergence guarantees. Extensive experiments on four knowledge-intensive benchmarks show that EXSEARCH substantially outperforms baselines, e.g., +7.8% improvement on exact match score. Motivated by these promising results, we introduce EXSEARCH-Zoo, an extension that extends our method to broader scenarios, to facilitate future work.
TTPA: Token-level Tool-use Preference Alignment Training Framework with Fine-grained Evaluation
May 26, 2025Existing tool-learning methods usually rely on supervised fine-tuning, they often overlook fine-grained optimization of internal tool call details, leading to limitations in preference alignment and error discrimination. To overcome these challenges, we propose Token-level Tool-use Preference Alignment Training Framework (TTPA), a training paradigm for constructing token-level tool-use preference datasets that align LLMs with fine-grained preferences using a novel error-oriented scoring mechanism. TTPA first introduces reversed dataset construction, a method for creating high-quality, multi-turn tool-use datasets by reversing the generation flow. Additionally, we propose Token-level Preference Sampling (TPS) to capture fine-grained preferences by modeling token-level differences during generation. To address biases in scoring, we introduce the Error-oriented Scoring Mechanism (ESM), which quantifies tool-call errors and can be used as a training signal. Extensive experiments on three diverse benchmark datasets demonstrate that TTPA significantly improves tool-using performance while showing strong generalization ability across models and datasets.
Direct Retrieval-augmented Optimization: Synergizing Knowledge Selection and Language Models
May 05, 2025Retrieval-augmented generation (RAG) integrates large language models ( LLM s) with retrievers to access external knowledge, improving the factuality of LLM generation in knowledge-grounded tasks. To optimize the RAG performance, most previous work independently fine-tunes the retriever to adapt to frozen LLM s or trains the LLMs to use documents retrieved by off-the-shelf retrievers, lacking end-to-end training supervision. Recent work addresses this limitation by jointly training these two components but relies on overly simplifying assumptions of document independence, which has been criticized for being far from real-world scenarios. Thus, effectively optimizing the overall RAG performance remains a critical challenge. We propose a direct retrieval-augmented optimization framework, named DRO, that enables end-to-end training of two key components: (i) a generative knowledge selection model and (ii) an LLM generator. DRO alternates between two phases: (i) document permutation estimation and (ii) re-weighted maximization, progressively improving RAG components through a variational approach. In the estimation step, we treat document permutation as a latent variable and directly estimate its distribution from the selection model by applying an importance sampling strategy. In the maximization step, we calibrate the optimization expectation using importance weights and jointly train the selection model and LLM generator. Our theoretical analysis reveals that DRO is analogous to policy-gradient methods in reinforcement learning. Extensive experiments conducted on five datasets illustrate that DRO outperforms the best baseline with 5%-15% improvements in EM and F1. We also provide in-depth experiments to qualitatively analyze the stability, convergence, and variance of DRO.
Retrieval Models Aren't Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models
Mar 03, 2025Tool learning aims to augment large language models (LLMs) with diverse tools, enabling them to act as agents for solving practical tasks. Due to the limited context length of tool-using LLMs, adopting information retrieval (IR) models to select useful tools from large toolsets is a critical initial step. However, the performance of IR models in tool retrieval tasks remains underexplored and unclear. Most tool-use benchmarks simplify this step by manually pre-annotating a small set of relevant tools for each task, which is far from the real-world scenarios. In this paper, we propose ToolRet, a heterogeneous tool retrieval benchmark comprising 7.6k diverse retrieval tasks, and a corpus of 43k tools, collected from existing datasets. We benchmark six types of models on ToolRet. Surprisingly, even the models with strong performance in conventional IR benchmarks, exhibit poor performance on ToolRet. This low retrieval quality degrades the task pass rate of tool-use LLMs. As a further step, we contribute a large-scale training dataset with over 200k instances, which substantially optimizes the tool retrieval ability of IR models.
MAIR: A Massive Benchmark for Evaluating Instructed Retrieval
Oct 14, 2024



Recent information retrieval (IR) models are pre-trained and instruction-tuned on massive datasets and tasks, enabling them to perform well on a wide range of tasks and potentially generalize to unseen tasks with instructions. However, existing IR benchmarks focus on a limited scope of tasks, making them insufficient for evaluating the latest IR models. In this paper, we propose MAIR (Massive Instructed Retrieval Benchmark), a heterogeneous IR benchmark that includes 126 distinct IR tasks across 6 domains, collected from existing datasets. We benchmark state-of-the-art instruction-tuned text embedding models and re-ranking models. Our experiments reveal that instruction-tuned models generally achieve superior performance compared to non-instruction-tuned models on MAIR. Additionally, our results suggest that current instruction-tuned text embedding models and re-ranking models still lack effectiveness in specific long-tail tasks. MAIR is publicly available at https://github.com/sunnweiwei/Mair.
What Affects the Stability of Tool Learning? An Empirical Study on the Robustness of Tool Learning Frameworks
Jul 03, 2024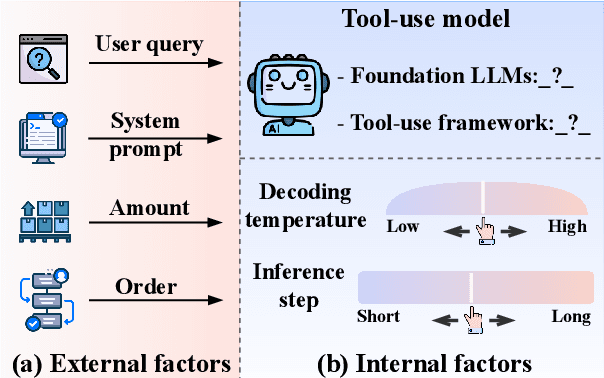

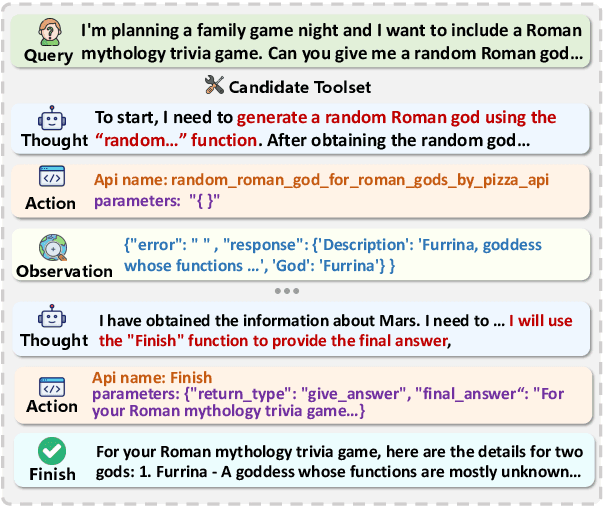
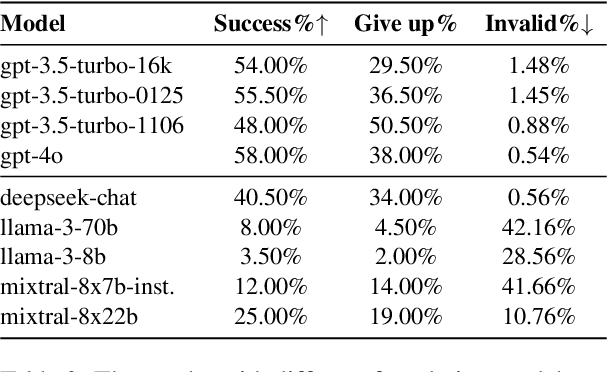
Tool learning methods have enhanced the ability of large language models (LLMs) to interact with real-world applications. Many existing works fine-tune LLMs or design prompts to enable LLMs to select appropriate tools and correctly invoke them to meet user requirements. However, it is observed in previous works that the performance of tool learning varies from tasks, datasets, training settings, and algorithms. Without understanding the impact of these factors, it can lead to inconsistent results, inefficient model deployment, and suboptimal tool utilization, ultimately hindering the practical integration and scalability of LLMs in real-world scenarios. Therefore, in this paper, we explore the impact of both internal and external factors on the performance of tool learning frameworks. Through extensive experiments on two benchmark datasets, we find several insightful conclusions for future work, including the observation that LLMs can benefit significantly from increased trial and exploration. We believe our empirical study provides a new perspective for future tool learning research.
Generate-then-Ground in Retrieval-Augmented Generation for Multi-hop Question Answering
Jun 21, 2024



Multi-Hop Question Answering (MHQA) tasks present a significant challenge for large language models (LLMs) due to the intensive knowledge required. Current solutions, like Retrieval-Augmented Generation, typically retrieve potential documents from an external corpus to read an answer. However, the performance of this retrieve-then-read paradigm is constrained by the retriever and the inevitable noise in the retrieved documents. To mitigate these challenges, we introduce a novel generate-then-ground (GenGround) framework, synergizing the parametric knowledge of LLMs and external documents to solve a multi-hop question. GenGround empowers LLMs to alternate two phases until the final answer is derived: (1) formulate a simpler, single-hop question and directly generate the answer; (2) ground the question-answer pair in retrieved documents, amending any wrong predictions in the answer. We also propose an instructional grounding distillation method to generalize our method into smaller models. Extensive experiments conducted on four datasets illustrate the superiority of our method.