 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Failure to Mastery: Generating Hard Samples for Tool-use Agents
Jan 04, 2026The advancement of LLM agents with tool-use capabilities requires diverse and complex training corpora. Existing data generation methods, which predominantly follow a paradigm of random sampling and shallow generation, often yield simple and homogeneous trajectories that fail to capture complex, implicit logical dependencies. To bridge this gap, we introduce HardGen, an automatic agentic pipeline designed to generate hard tool-use training samples with verifiable reasoning. Firstly, HardGen establishes a dynamic API Graph built upon agent failure cases, from which it samples to synthesize hard traces. Secondly, these traces serve as conditional priors to guide the instantiation of modular, abstract advanced tools, which are subsequently leveraged to formulate hard queries. Finally, the advanced tools and hard queries enable the generation of verifiable complex Chain-of-Thought (CoT), with a closed-loop evaluation feedback steering the continuous refinement of the process. Extensive evaluations demonstrate that a 4B parameter model trained with our curated dataset achieves superior performance compared to several leading open-source and closed-source competitors (e.g., GPT-5.2, Gemini-3-Pro and Claude-Opus-4.5). Our code, models, and dataset will be open-sourced to facilitate future research.
Beyond Superficial Forgetting: Thorough Unlearning through Knowledge Density Estimation and Block Re-insertion
Nov 11, 2025Machine unlearning, which selectively removes harmful knowledge from a pre-trained model without retraining from scratch, is crucial for addressing privacy, regulatory compliance, and ethical concerns in Large Language Models (LLMs). However, existing unlearning methods often struggle to thoroughly remove harmful knowledge, leaving residual harmful knowledge that can be easily recovered. To address these limitations, we propose Knowledge Density-Guided Unlearning via Blocks Reinsertion (KUnBR), a novel approach that first identifies layers with rich harmful knowledge and then thoroughly eliminates the harmful knowledge via re-insertion strategy. Our method introduces knowledge density estimation to quantify and locate layers containing the most harmful knowledge, enabling precise unlearning. Additionally, we design a layer re-insertion strategy that extracts and re-inserts harmful knowledge-rich layers into the original LLM, bypassing gradient obstruction caused by cover layers and ensuring effective gradient propagation during unlearning. Extensive experiments conducted on several unlearning and general capability benchmarks demonstrate that KUnBR achieves state-of-the-art forgetting performance while maintaining model utility.
What Affects the Stability of Tool Learning? An Empirical Study on the Robustness of Tool Learning Frameworks
Jul 03, 2024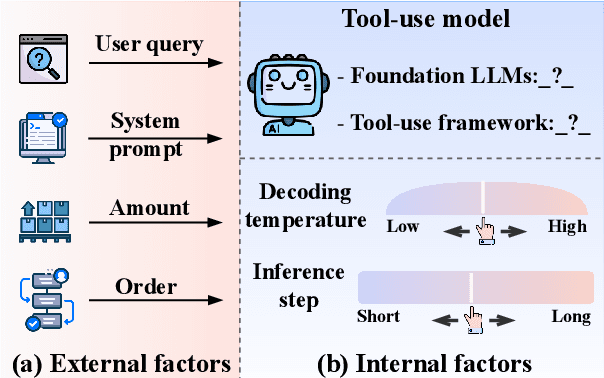

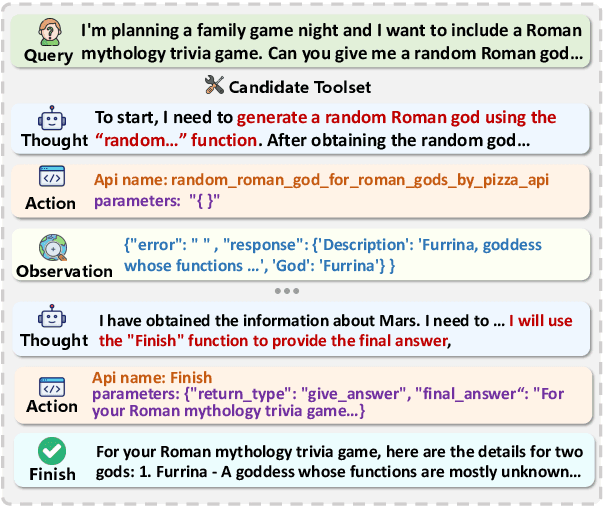
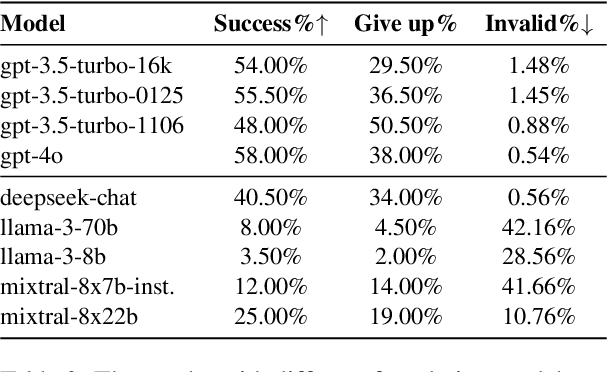
Tool learning methods have enhanced the ability of large language models (LLMs) to interact with real-world applications. Many existing works fine-tune LLMs or design prompts to enable LLMs to select appropriate tools and correctly invoke them to meet user requirements. However, it is observed in previous works that the performance of tool learning varies from tasks, datasets, training settings, and algorithms. Without understanding the impact of these factors, it can lead to inconsistent results, inefficient model deployment, and suboptimal tool utilization, ultimately hindering the practical integration and scalability of LLMs in real-world scenarios. Therefore, in this paper, we explore the impact of both internal and external factors on the performance of tool learning frameworks. Through extensive experiments on two benchmark datasets, we find several insightful conclusions for future work, including the observation that LLMs can benefit significantly from increased trial and exploration. We believe our empirical study provides a new perspective for future tool learning research.
Simulating Financial Market via Large Language Model based Agents
Jun 28, 2024



Most economic theories typically assume that financial market participants are fully rational individuals and use mathematical models to simulate human behavior in financial markets. However, human behavior is often not entirely rational and is challenging to predict accurately with mathematical models. In this paper, we propose \textbf{A}gent-based \textbf{S}imulated \textbf{F}inancial \textbf{M}arket (ASFM), which first constructs a simulated stock market with a real order matching system. Then, we propose a large language model based agent as the stock trader, which contains the profile, observation, and tool-learning based action module. The trading agent can comprehensively understand current market dynamics and financial policy information, and make decisions that align with their trading strategy. In the experiments, we first verify that the reactions of our ASFM are consistent with the real stock market in two controllable scenarios. In addition, we also conduct experiments in two popular economics research directions, and we find that conclusions drawn in our \model align with the preliminary findings in economics research. Based on these observations, we believe our proposed ASFM provides a new paradigm for economic research.