 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuMate-DeepResearch: An Auditable Multi-Agent System with Recursive Search and Rubric-Grounded Reasoning
Jun 05, 2026Deep Research (DR) has emerged as a new agentic paradigm to tackle complex, open-ended research tasks, demanding systems that can iteratively frame problems, acquire evidence, verify sources, and synthesize long-form reports. In practice, however, current DR systems are constrained by four interrelated limitations: long-horizon planning over an underspecified scope, the bottleneck of decomposing and scheduling such tasks within a single agent, hallucination risk in long-form synthesis, and limited process auditability. This technical report presents DuMate-DeepResearch, a multi-agent DR framework built on the Qianfan Agent Foundry. The framework decouples the Agent Core, which handles task understanding, planning, and scheduling, from an extensible Tool Ecosystem for retrieval, evidence acquisition, and report rendering, making every intermediate decision and tool invocation explicitly traceable. Building on this infrastructure, DuMate-DeepResearch further introduces three mechanisms: (i) a graph-based dynamic planning strategy expands the research roadmap coarse-to-fine and continuously revises it through reflection, re-planning, backtracking, and parallel branching; (ii) a recursive two-level execution design delegates each complex search sub-task to an inner Search Agent that runs its own planning loop, isolating noisy retrieval and stabilizing long-horizon execution; (iii) a rubric-based test-time optimization mechanism dynamically generates task-specific quality criteria and uses them as live reasoning scaffolds for evidence-grounded synthesis and adaptive stopping. Across two deep research benchmarks, DuMate-DeepResearch establishes new state-of-the-art results: the best overall score (58.03%) on DeepResearch Bench, and the best overall score (61.95%) on DeepResearch Bench II while ranking first in information recall and analysis.
ProCrit: Self-Elicited Multi-Perspective Reasoning with Critic-Guided Revision for Multimodal Sarcasm Detection
May 20, 2026Multimodal sarcasm detection requires reasoning over cross-modal incongruities between literal expression and intended meaning, yet the specific analytical perspectives needed vary across samples due to the diversity of sarcastic mechanisms. While recent methods make this analytical process explicit, they still rely on fixed, predefined perspectives that operate independently under hand-crafted routing rules. We argue that multimodal sarcasm detection instead calls for self-elicited multi-perspective reasoning, where a model autonomously generates the perspectives needed for each sample and progressively integrates them into a coherent analysis. To realize this goal, we propose ProCrit, a Proposal-Critic two-agent framework with a proposal agent for multi-perspective reasoning and a critic agent for external evaluation and targeted revision guidance. First, to overcome the lack of process-level supervision in existing sarcasm datasets, ProCrit synthesizes process-level reasoning annotations through a dynamic-role agentic rollout: a strong vision-language model sequentially spawns analytical roles within a shared context, and the resulting multi-role trajectories are flattened into sequences that preserve cross-perspective dependencies while enabling efficient autoregressive generation. Second, to improve reasoning reliability, ProCrit adopts a draft-critique-revise paradigm in which an independent critic identifies reasoning deficiencies and provides targeted natural-language feedback for directed revision. Finally, we develop a mutual-refinement training framework that jointly optimizes proposal drafting and feedback-guided revision via dual-stage reinforcement learning, while refining the critic agent according to the actual effectiveness of its feedback. Experiments on three widely used benchmarks demonstrate the effectiveness of ProCrit.
VISOR: Agentic Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning
Apr 10, 2026Visual Retrieval-Augmented Generation (VRAG) empowers Vision-Language Models to retrieve and reason over visually rich documents. To tackle complex queries requiring multi-step reasoning, agentic VRAG systems interleave reasoning with iterative retrieval.. However, existing agentic VRAG faces two critical bottlenecks. (1) Visual Evidence Sparsity: key evidence is scattered across pages yet processed in isolation, hindering cross-page reasoning; moreover, fine-grained intra-image evidence often requires precise visual actions, whose misuse degrades retrieval quality; (2) Search Drift in Long Horizons: the accumulation of visual tokens across retrieved pages dilutes context and causes cognitive overload, leading agents to deviate from their search objective. To address these challenges, we propose VISOR (Visual Retrieval-Augmented Generation via Iterative Search and Over-horizon Reasoning), a unified single-agent framework. VISOR features a structured Evidence Space for progressive cross-page reasoning, coupled with a Visual Action Evaluation and Correction mechanism to manage visual actions. Additionally, we introduce a Dynamic Trajectory with Sliding Window and Intent Injection to mitigate search drift. They anchor the evidence space while discarding earlier raw interactions, preventing context from being overwhelmed by visual tokens. We train VISOR using a Group Relative Policy Optimization-based Reinforcement Learning (GRPO-based RL) pipeline with state masking and credit assignment tailored for dynamic context reconstruction. Extensive experiments on ViDoSeek, SlideVQA, and MMLongBench demonstrate that VISOR achieves state-of-the-art performance with superior efficiency for long-horizon visual reasoning tasks.
Beyond End-to-End Video Models: An LLM-Based Multi-Agent System for Educational Video Generation
Feb 12, 2026Although recent end-to-end video generation models demonstrate impressive performance in visually oriented content creation, they remain limited in scenarios that require strict logical rigor and precise knowledge representation, such as instructional and educational media. To address this problem, we propose LAVES, a hierarchical LLM-based multi-agent system for generating high-quality instructional videos from educational problems. The LAVES formulates educational video generation as a multi-objective task that simultaneously demands correct step-by-step reasoning, pedagogically coherent narration, semantically faithful visual demonstrations, and precise audio--visual alignment. To address the limitations of prior approaches--including low procedural fidelity, high production cost, and limited controllability--LAVES decomposes the generation workflow into specialized agents coordinated by a central Orchestrating Agent with explicit quality gates and iterative critique mechanisms. Specifically, the Orchestrating Agent supervises a Solution Agent for rigorous problem solving, an Illustration Agent that produces executable visualization codes, and a Narration Agent for learner-oriented instructional scripts. In addition, all outputs from the working agents are subject to semantic critique, rule-based constraints, and tool-based compilation checks. Rather than directly synthesizing pixels, the system constructs a structured executable video script that is deterministically compiled into synchronized visuals and narration using template-driven assembly rules, enabling fully automated end-to-end production without manual editing. In large-scale deployments, LAVES achieves a throughput exceeding one million videos per day, delivering over a 95% reduction in cost compared to current industry-standard approaches while maintaining a high acceptance rate.
Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025
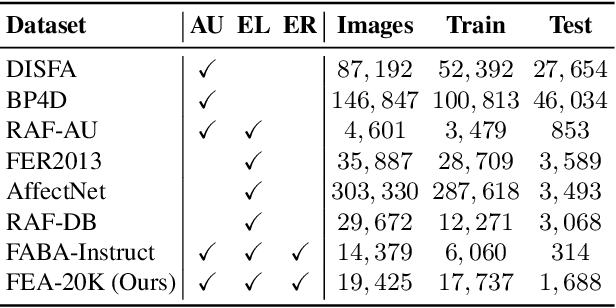
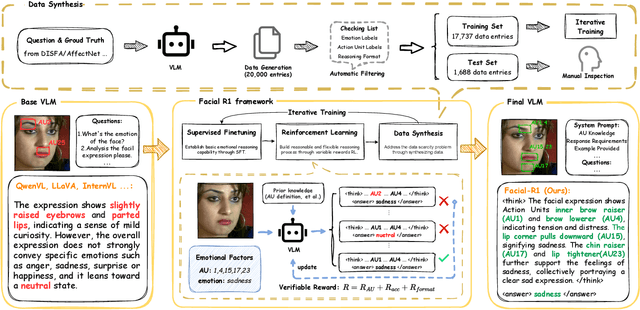
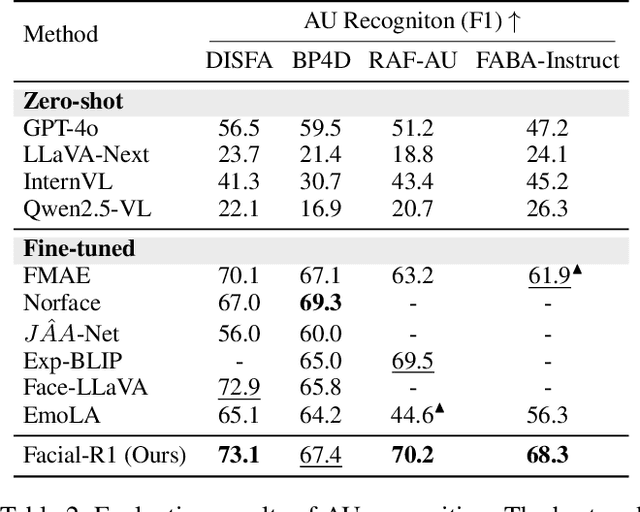
Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
MAIR: A Massive Benchmark for Evaluating Instructed Retrieval
Oct 14, 2024



Recent information retrieval (IR) models are pre-trained and instruction-tuned on massive datasets and tasks, enabling them to perform well on a wide range of tasks and potentially generalize to unseen tasks with instructions. However, existing IR benchmarks focus on a limited scope of tasks, making them insufficient for evaluating the latest IR models. In this paper, we propose MAIR (Massive Instructed Retrieval Benchmark), a heterogeneous IR benchmark that includes 126 distinct IR tasks across 6 domains, collected from existing datasets. We benchmark state-of-the-art instruction-tuned text embedding models and re-ranking models. Our experiments reveal that instruction-tuned models generally achieve superior performance compared to non-instruction-tuned models on MAIR. Additionally, our results suggest that current instruction-tuned text embedding models and re-ranking models still lack effectiveness in specific long-tail tasks. MAIR is publicly available at https://github.com/sunnweiwei/Mair.