 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting Misalignment: A Conflict-Aware Framework for Reward-Model-based LLM Alignment
Dec 10, 2025Reward-model-based fine-tuning is a central paradigm in aligning Large Language Models with human preferences. However, such approaches critically rely on the assumption that proxy reward models accurately reflect intended supervision, a condition often violated due to annotation noise, bias, or limited coverage. This misalignment can lead to undesirable behaviors, where models optimize for flawed signals rather than true human values. In this paper, we investigate a novel framework to identify and mitigate such misalignment by treating the fine-tuning process as a form of knowledge integration. We focus on detecting instances of proxy-policy conflicts, cases where the base model strongly disagrees with the proxy. We argue that such conflicts often signify areas of shared ignorance, where neither the policy nor the reward model possesses sufficient knowledge, making them especially susceptible to misalignment. To this end, we propose two complementary metrics for identifying these conflicts: a localized Proxy-Policy Alignment Conflict Score (PACS) and a global Kendall-Tau Distance measure. Building on this insight, we design an algorithm named Selective Human-in-the-loop Feedback via Conflict-Aware Sampling (SHF-CAS) that targets high-conflict QA pairs for additional feedback, refining both the reward model and policy efficiently. Experiments on two alignment tasks demonstrate that our approach enhances general alignment performance, even when trained with a biased proxy reward. Our work provides a new lens for interpreting alignment failures and offers a principled pathway for targeted refinement in LLM training.
On Cyclical MCMC Sampling
Mar 01, 2024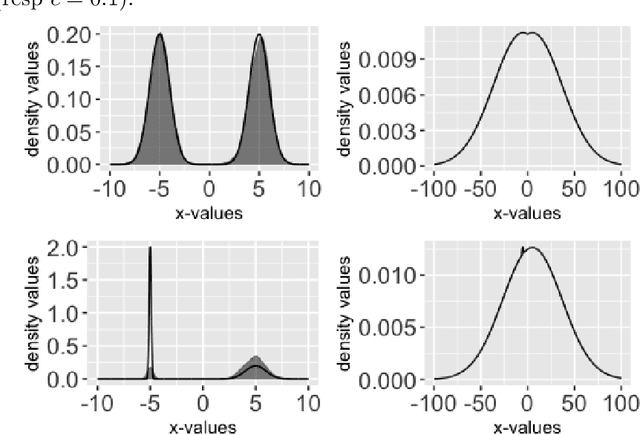
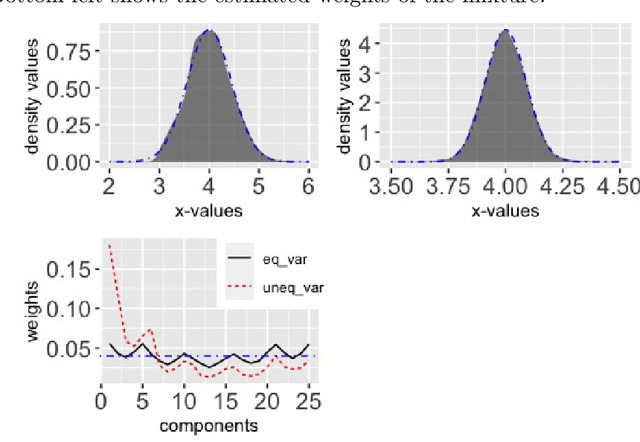
Cyclical MCMC is a novel MCMC framework recently proposed by Zhang et al. (2019) to address the challenge posed by high-dimensional multimodal posterior distributions like those arising in deep learning. The algorithm works by generating a nonhomogeneous Markov chain that tracks -- cyclically in time -- tempered versions of the target distribution. We show in this work that cyclical MCMC converges to the desired probability distribution in settings where the Markov kernels used are fast mixing, and sufficiently long cycles are employed. However in the far more common settings of slow mixing kernels, the algorithm may fail to produce samples from the desired distribution. In particular, in a simple mixture example with unequal variance, we show by simulation that cyclical MCMC fails to converge to the desired limit. Finally, we show that cyclical MCMC typically estimates well the local shape of the target distribution around each mode, even when we do not have convergence to the target.
Deep MSFOP: Multiple Spectral filter Operators Preservation in Deep Functional Maps for Unsupervised Shape Matching
Feb 06, 2024



We propose a novel constraint called Multiple Spectral filter Operators Preservation (MSFOR) to compute functional maps and based on it, develop an efficient deep functional map architecture called Deep MSFOP for shape matching. The core idea is that, instead of using the general descriptor preservation constraint, we require our maps to preserve multiple spectral filter operators. This allows us to incorporate more informative geometrical information, contained in different frequency bands of functions, into the functional map computing. This can be confirmed by that some previous techniques like wavelet preservation and LBO commutativity are actually our special cases. Moreover, we also develop a very efficient way to compute the maps with MSFOP constraint, which can be conveniently embedded into the deep learning, especially having learnable filter operators. Utilizing the above results, we finally design our Deep MSFOP pipeline, equipped with a suitable unsupervised loss jointly penalizing the functional map and the underlying pointwise map. Our deep functional map has notable advantages, including that the functional map is more geometrically informative and guaranteed to be proper, and the computing is numerically stable. Extensive experimental results on different datasets demonstrate that our approach outperforms the existing state-of-the-art methods, especially in challenging settings like non-isometric and inconsistent topology datasets.
TABSurfer: a Hybrid Deep Learning Architecture for Subcortical Segmentation
Dec 13, 2023Subcortical segmentation remains challenging despite its important applications in quantitative structural analysis of brain MRI scans. The most accurate method, manual segmentation, is highly labor intensive, so automated tools like FreeSurfer have been adopted to handle this task. However, these traditional pipelines are slow and inefficient for processing large datasets. In this study, we propose TABSurfer, a novel 3D patch-based CNN-Transformer hybrid deep learning model designed for superior subcortical segmentation compared to existing state-of-the-art tools. To evaluate, we first demonstrate TABSurfer's consistent performance across various T1w MRI datasets with significantly shorter processing times compared to FreeSurfer. Then, we validate against manual segmentations, where TABSurfer outperforms FreeSurfer based on the manual ground truth. In each test, we also establish TABSurfer's advantage over a leading deep learning benchmark, FastSurferVINN. Together, these studies highlight TABSurfer's utility as a powerful tool for fully automated subcortical segmentation with high fidelity.
A statistical perspective on algorithm unrolling models for inverse problems
Nov 10, 2023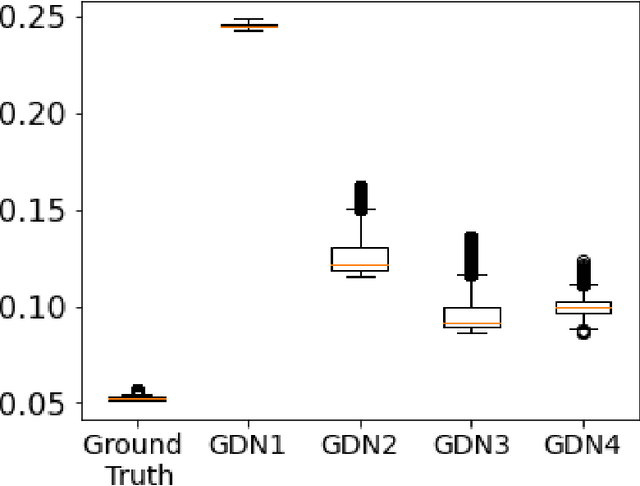
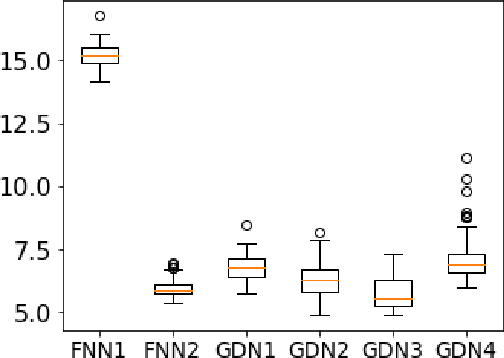
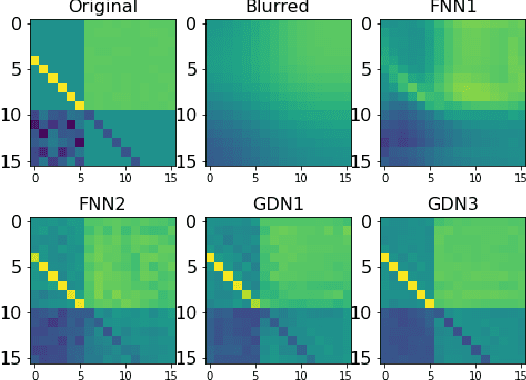
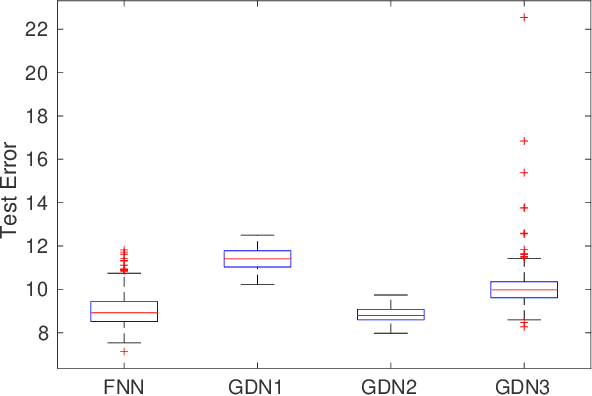
We consider inverse problems where the conditional distribution of the observation ${\bf y}$ given the latent variable of interest ${\bf x}$ (also known as the forward model) is known, and we have access to a data set in which multiple instances of ${\bf x}$ and ${\bf y}$ are both observed. In this context, algorithm unrolling has become a very popular approach for designing state-of-the-art deep neural network architectures that effectively exploit the forward model. We analyze the statistical complexity of the gradient descent network (GDN), an algorithm unrolling architecture driven by proximal gradient descent. We show that the unrolling depth needed for the optimal statistical performance of GDNs is of order $\log(n)/\log(\varrho_n^{-1})$, where $n$ is the sample size, and $\varrho_n$ is the convergence rate of the corresponding gradient descent algorithm. We also show that when the negative log-density of the latent variable ${\bf x}$ has a simple proximal operator, then a GDN unrolled at depth $D'$ can solve the inverse problem at the parametric rate $O(D'/\sqrt{n})$. Our results thus also suggest that algorithm unrolling models are prone to overfitting as the unrolling depth $D'$ increases. We provide several examples to illustrate these results.
Learning to predict crisp boundaries
Jul 26, 2018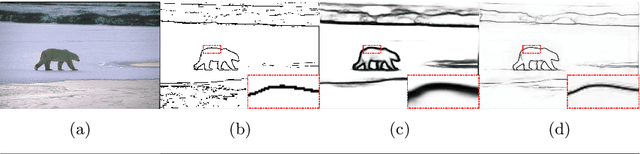



Recent methods for boundary or edge detection built on Deep Convolutional Neural Networks (CNNs) typically suffer from the issue of predicted edges being thick and need post-processing to obtain crisp boundaries. Highly imbalanced categories of boundary versus background in training data is one of main reasons for the above problem. In this work, the aim is to make CNNs produce sharp boundaries without post-processing. We introduce a novel loss for boundary detection, which is very effective for classifying imbalanced data and allows CNNs to produce crisp boundaries. Moreover, we propose an end-to-end network which adopts the bottom-up/top-down architecture to tackle the task. The proposed network effectively leverages hierarchical features and produces pixel-accurate boundary mask, which is critical to reconstruct the edge map. Our experiments illustrate that directly making crisp prediction not only promotes the visual results of CNNs, but also achieves better results against the state-of-the-art on the BSDS500 dataset (ODS F-score of .815) and the NYU Depth dataset (ODS F-score of .762).