Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Attack and Defense on Text
Paper and Code
Aug 07, 2020


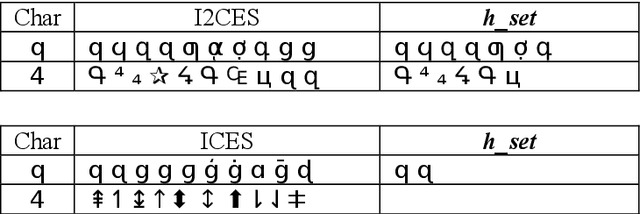
Modifying characters of a piece of text to their visual similar ones often ap-pear in spam in order to fool inspection systems and other conditions, which we regard as a kind of adversarial attack to neural models. We pro-pose a way of generating such visual text attack and show that the attacked text are readable by humans but mislead a neural classifier greatly. We ap-ply a vision-based model and adversarial training to defense the attack without losing the ability to understand normal text. Our results also show that visual attack is extremely sophisticated and diverse, more work needs to be done to solve this.
* 9 pages
View paper on