 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Apr 22, 2025Reinforcement learning (RL) has become the core post-training technique for large language models (LLMs). RL for LLMs involves two stages: generation and training. The LLM first generates samples online, which are then used to derive rewards for training. The conventional view holds that the colocated architecture, where the two stages share resources via temporal multiplexing, outperforms the disaggregated architecture, in which dedicated resources are assigned to each stage. However, in real-world deployments, we observe that the colocated architecture suffers from resource coupling, where the two stages are constrained to use the same resources. This coupling compromises the scalability and cost-efficiency of colocated RL in large-scale training. In contrast, the disaggregated architecture allows for flexible resource allocation, supports heterogeneous training setups, and facilitates cross-datacenter deployment. StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching and scheduling. Experiments show that StreamRL improves throughput by up to 2.66x compared to existing state-of-the-art systems, and improves cost-effectiveness by up to 1.33x in a heterogeneous, cross-datacenter setting.
PipeWeaver: Addressing Data Dynamicity in Large Multimodal Model Training with Dynamic Interleaved Pipeline
Apr 19, 2025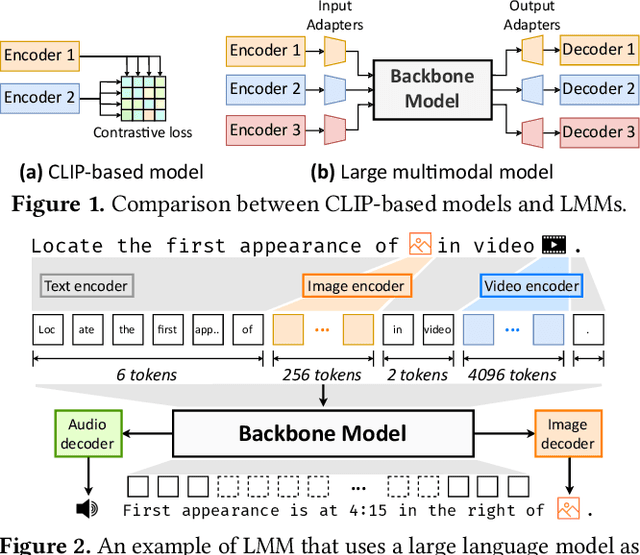
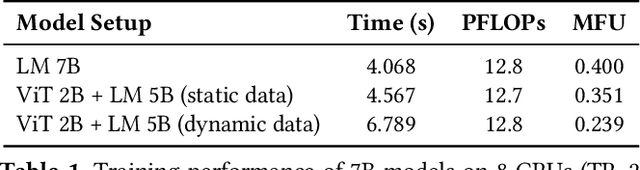


Large multimodal models (LMMs) have demonstrated excellent capabilities in both understanding and generation tasks with various modalities. While these models can accept flexible combinations of input data, their training efficiency suffers from two major issues: pipeline stage imbalance caused by heterogeneous model architectures, and training data dynamicity stemming from the diversity of multimodal data. In this paper, we present PipeWeaver, a dynamic pipeline scheduling framework designed for LMM training. The core of PipeWeaver is dynamic interleaved pipeline, which searches for pipeline schedules dynamically tailored to current training batches. PipeWeaver addresses issues of LMM training with two techniques: adaptive modality-aware partitioning and efficient pipeline schedule search within a hierarchical schedule space. Meanwhile, PipeWeaver utilizes SEMU (Step Emulator), a training simulator for multimodal models, for accurate performance estimations, accelerated by spatial-temporal subgraph reuse to improve search efficiency. Experiments show that PipeWeaver can enhance LMM training efficiency by up to 97.3% compared to state-of-the-art systems, and demonstrate excellent adaptivity to LMM training's data dynamicity.
DSV: Exploiting Dynamic Sparsity to Accelerate Large-Scale Video DiT Training
Feb 11, 2025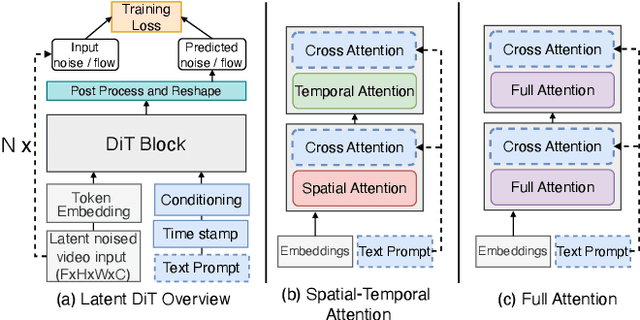

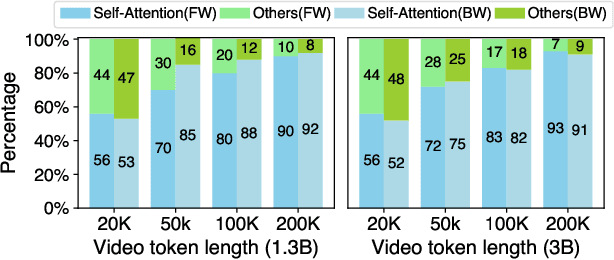
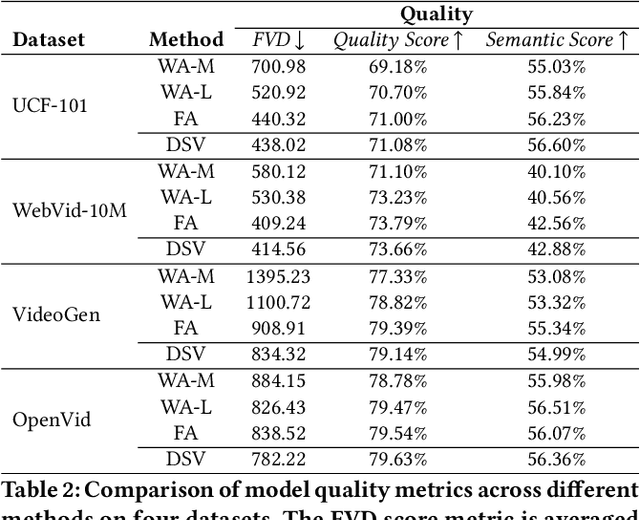
Diffusion Transformers (DiTs) have shown remarkable performance in modeling and generating high-quality videos. However, the quadratic computational complexity of 3D full attention mechanism presents significant challenges in scaling video DiT training, especially for high-definition and lengthy videos, where attention can dominate up to 95% of the end-to-end time and necessitate specialized communication paradigms to handle large input sizes. This paper introduces DSV, a novel framework designed to accelerate and scale the training of video DiTs by leveraging the inherent dynamic attention sparsity throughout the training process. DSV employs a two-stage training algorithm that exploits sparsity patterns, focusing on critical elements supported by efficient, tailored kernels. To accommodate the new sparsity dimension, we develop a hybrid sparsity-aware context parallelism that effectively scales to large inputs by addressing the heterogeneity of sparsity across attention heads and blocks, resulting in optimized sparse computation and communication. Extensive evaluations demonstrate that DSV achieves up to 3.02x gain in training throughput with nearly no quality degradation.
InfinitePOD: Building Datacenter-Scale High-Bandwidth Domain for LLM with Optical Circuit Switching Transceivers
Feb 07, 2025



Scaling Large Language Model (LLM) training relies on multi-dimensional parallelism, where High-Bandwidth Domains (HBDs) are critical for communication-intensive parallelism like Tensor Parallelism (TP) and Expert Parallelism (EP). However, existing HBD architectures face fundamental limitations in scalability, cost, and fault resiliency: switch-centric HBDs (e.g., NVL-72) incur prohibitive scaling costs, while GPU-centric HBDs (e.g., TPUv3/Dojo) suffer from severe fault propagation. Switch-GPU hybrid HBDs such as TPUv4 takes a middle-ground approach by leveraging Optical Circuit Switches, but the fault explosion radius remains large at the cube level (e.g., 64 TPUs). We propose InfinitePOD, a novel transceiver-centric HBD architecture that unifies connectivity and dynamic switching at the transceiver level using Optical Circuit Switching (OCS). By embedding OCS within each transceiver, InfinitePOD achieves reconfigurable point-to-multipoint connectivity, allowing the topology to adapt into variable-size rings. This design provides: i) datacenter-wide scalability without cost explosion; ii) fault resilience by isolating failures to a single node, and iii) full bandwidth utilization for fault-free GPUs. Key innovations include a Silicon Photonic (SiPh) based low-cost OCS transceiver (OCSTrx), a reconfigurable k-hop ring topology co-designed with intra-/inter-node communication, and an HBD-DCN orchestration algorithm maximizing GPU utilization while minimizing cross-ToR datacenter network traffic. The evaluation demonstrates that InfinitePOD achieves 31% of the cost of NVL-72, near-zero GPU waste ratio (over one order of magnitude lower than NVL-72 and TPUv4), near-zero cross-ToR traffic when node fault ratios under 7%, and improves Model FLOPs Utilization by 3.37x compared to NVIDIA DGX (8 GPUs per Node).
Teola: Towards End-to-End Optimization of LLM-based Applications
Jun 29, 2024



Large language model (LLM)-based applications consist of both LLM and non-LLM components, each contributing to the end-to-end latency. Despite great efforts to optimize LLM inference, end-to-end workflow optimization has been overlooked. Existing frameworks employ coarse-grained orchestration with task modules, which confines optimizations to within each module and yields suboptimal scheduling decisions. We propose fine-grained end-to-end orchestration, which utilizes task primitives as the basic units and represents each query's workflow as a primitive-level dataflow graph. This explicitly exposes a much larger design space, enables optimizations in parallelization and pipelining across primitives of different modules, and enhances scheduling to improve application-level performance. We build Teola, a novel orchestration framework for LLM-based applications that implements this scheme. Comprehensive experiments show that Teola can achieve up to 2.09x speedup over existing systems across various popular LLM applications.
Scene-Adaptive Person Search via Bilateral Modulations
May 05, 2024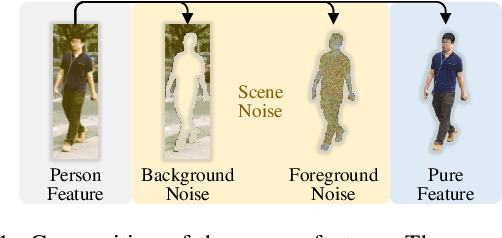
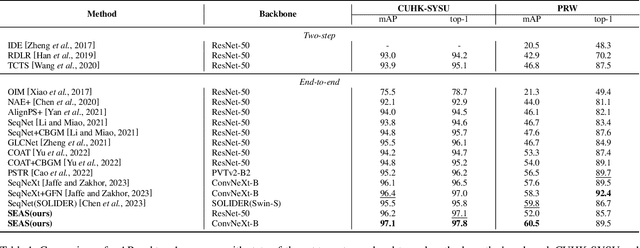
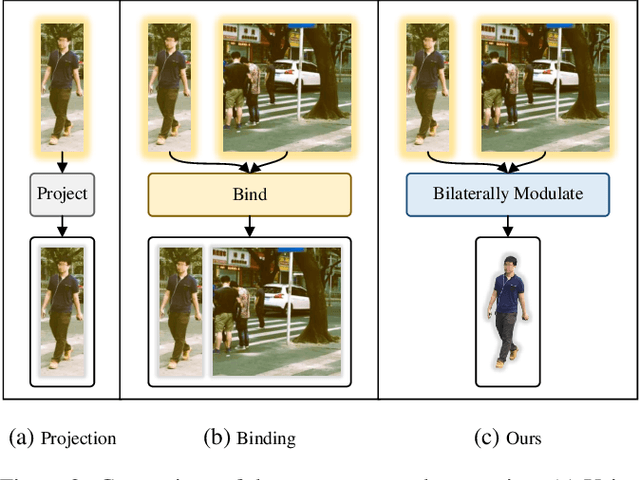

Person search aims to localize specific a target person from a gallery set of images with various scenes. As the scene of moving pedestrian changes, the captured person image inevitably bring in lots of background noise and foreground noise on the person feature, which are completely unrelated to the person identity, leading to severe performance degeneration. To address this issue, we present a Scene-Adaptive Person Search (SEAS) model by introducing bilateral modulations to simultaneously eliminate scene noise and maintain a consistent person representation to adapt to various scenes. In SEAS, a Background Modulation Network (BMN) is designed to encode the feature extracted from the detected bounding box into a multi-granularity embedding, which reduces the input of background noise from multiple levels with norm-aware. Additionally, to mitigate the effect of foreground noise on the person feature, SEAS introduces a Foreground Modulation Network (FMN) to compute the clutter reduction offset for the person embedding based on the feature map of the scene image. By bilateral modulations on both background and foreground within an end-to-end manner, SEAS obtains consistent feature representations without scene noise. SEAS can achieve state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU with 97.1\% mAP and PRW with 60.5\% mAP. The code is available at https://github.com/whbdmu/SEAS.
Adaptive Gating in Mixture-of-Experts based Language Models
Oct 11, 2023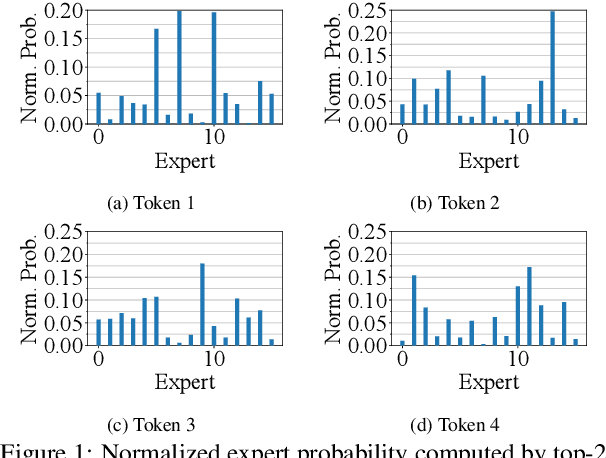


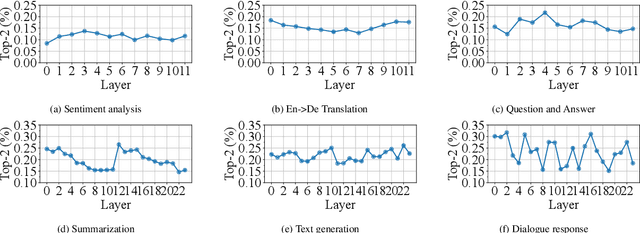
Large language models, such as OpenAI's ChatGPT, have demonstrated exceptional language understanding capabilities in various NLP tasks. Sparsely activated mixture-of-experts (MoE) has emerged as a promising solution for scaling models while maintaining a constant number of computational operations. Existing MoE model adopts a fixed gating network where each token is computed by the same number of experts. However, this approach contradicts our intuition that the tokens in each sequence vary in terms of their linguistic complexity and, consequently, require different computational costs. Little is discussed in prior research on the trade-off between computation per token and model performance. This paper introduces adaptive gating in MoE, a flexible training strategy that allows tokens to be processed by a variable number of experts based on expert probability distribution. The proposed framework preserves sparsity while improving training efficiency. Additionally, curriculum learning is leveraged to further reduce training time. Extensive experiments on diverse NLP tasks show that adaptive gating reduces at most 22.5% training time while maintaining inference quality. Moreover, we conduct a comprehensive analysis of the routing decisions and present our insights when adaptive gating is used.