 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeola: Towards End-to-End Optimization of LLM-based Applications
Jun 29, 2024



Large language model (LLM)-based applications consist of both LLM and non-LLM components, each contributing to the end-to-end latency. Despite great efforts to optimize LLM inference, end-to-end workflow optimization has been overlooked. Existing frameworks employ coarse-grained orchestration with task modules, which confines optimizations to within each module and yields suboptimal scheduling decisions. We propose fine-grained end-to-end orchestration, which utilizes task primitives as the basic units and represents each query's workflow as a primitive-level dataflow graph. This explicitly exposes a much larger design space, enables optimizations in parallelization and pipelining across primitives of different modules, and enhances scheduling to improve application-level performance. We build Teola, a novel orchestration framework for LLM-based applications that implements this scheme. Comprehensive experiments show that Teola can achieve up to 2.09x speedup over existing systems across various popular LLM applications.
Adaptive Gating in Mixture-of-Experts based Language Models
Oct 11, 2023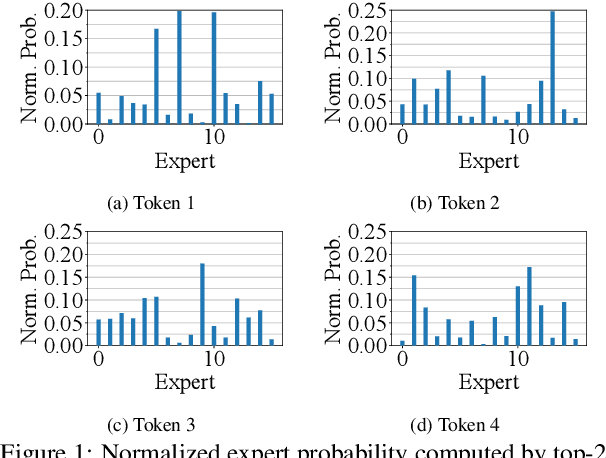


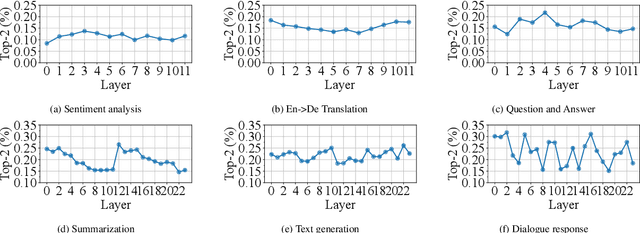
Large language models, such as OpenAI's ChatGPT, have demonstrated exceptional language understanding capabilities in various NLP tasks. Sparsely activated mixture-of-experts (MoE) has emerged as a promising solution for scaling models while maintaining a constant number of computational operations. Existing MoE model adopts a fixed gating network where each token is computed by the same number of experts. However, this approach contradicts our intuition that the tokens in each sequence vary in terms of their linguistic complexity and, consequently, require different computational costs. Little is discussed in prior research on the trade-off between computation per token and model performance. This paper introduces adaptive gating in MoE, a flexible training strategy that allows tokens to be processed by a variable number of experts based on expert probability distribution. The proposed framework preserves sparsity while improving training efficiency. Additionally, curriculum learning is leveraged to further reduce training time. Extensive experiments on diverse NLP tasks show that adaptive gating reduces at most 22.5% training time while maintaining inference quality. Moreover, we conduct a comprehensive analysis of the routing decisions and present our insights when adaptive gating is used.
ConvNext Based Neural Network for Anti-Spoofing
Sep 15, 2022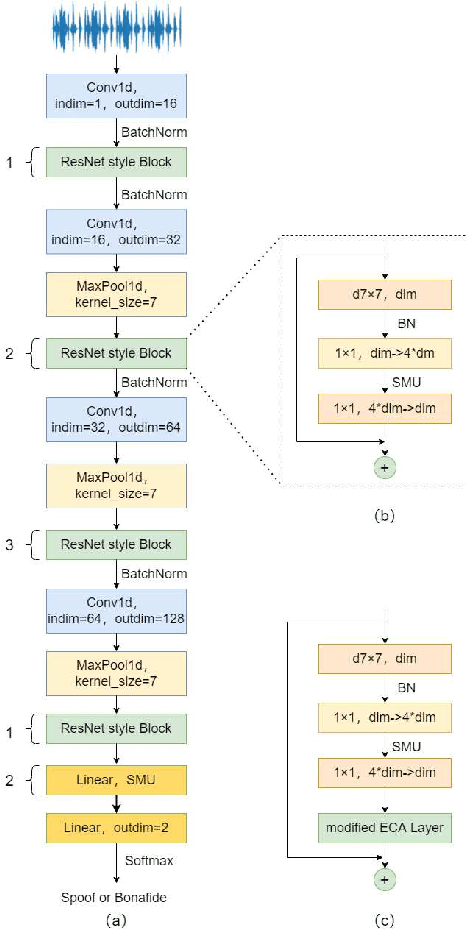
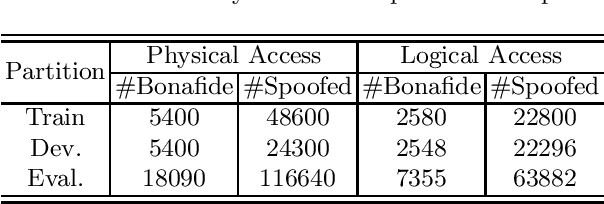
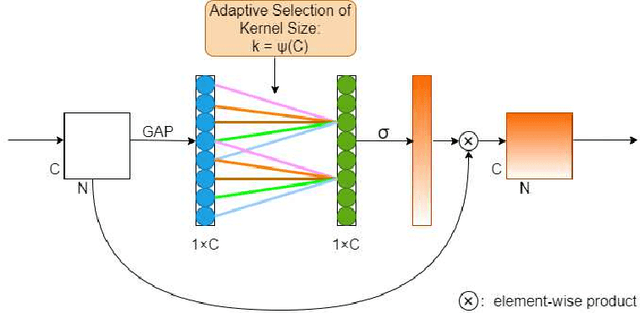
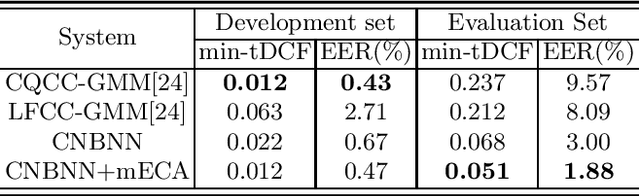
Automatic speaker verification (ASV) has been widely used in the real life for identity authentication. However, with the rapid development of speech conversion, speech synthesis algorithms and the improvement of the quality of recording devices, ASV systems are vulnerable for spoof attacks. In recent years, there have many works about synthetic and replay speech detection, researchers had proposed a number of anti-spoofing methods based on hand-crafted features to improve the accuracy and robustness of synthetic and replay speech detection system. However, using hand-crafted features rather than raw waveform would lose certain information for anti-spoofing, which will reduce the detection performance of the system. Inspired by the promising performance of ConvNext in image classification tasks, we extend the ConvNext network architecture accordingly for spoof attacks detection task and propose an end-to-end anti-spoofing model. By integrating the extended architecture with the channel attention block, the proposed model can focus on the most informative sub-bands of speech representations to improve the anti-spoofing performance. Experiments show that our proposed best single system could achieve an equal error rate of 1.88% and 2.79% for the ASVSpoof 2019 LA evaluation dataset and PA evaluation dataset respectively, which demonstrate the model's capacity for anti-spoofing.