 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvNext Based Neural Network for Anti-Spoofing
Sep 15, 2022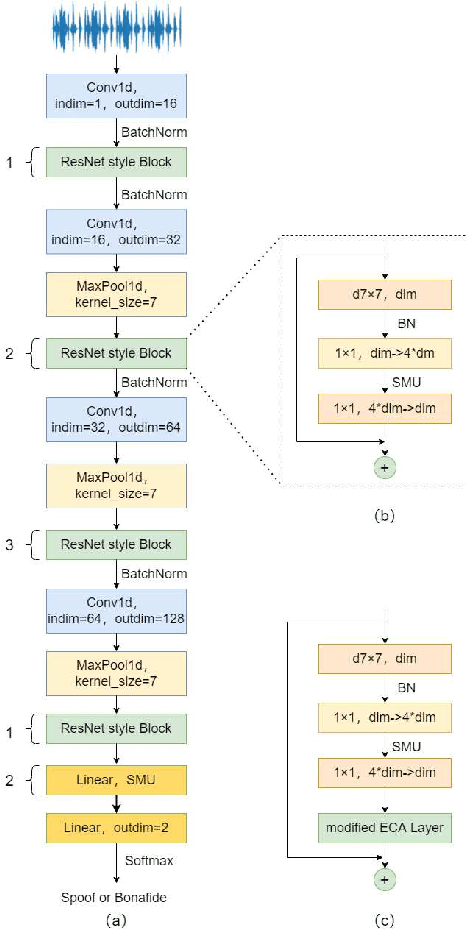
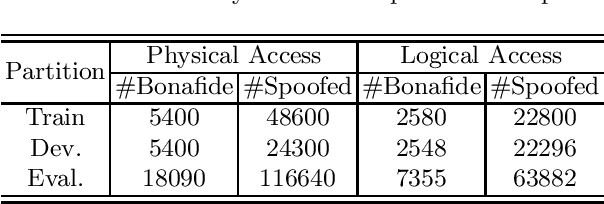
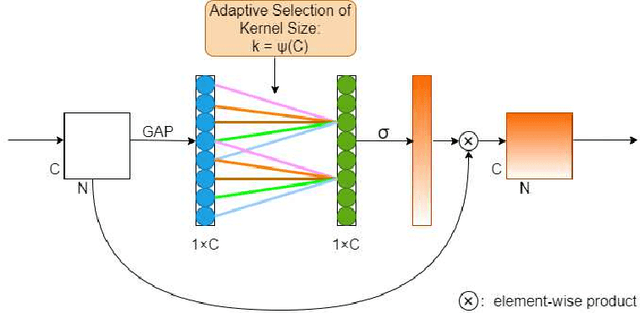
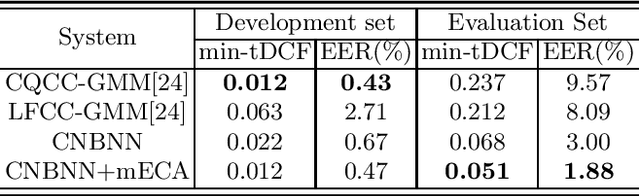
Automatic speaker verification (ASV) has been widely used in the real life for identity authentication. However, with the rapid development of speech conversion, speech synthesis algorithms and the improvement of the quality of recording devices, ASV systems are vulnerable for spoof attacks. In recent years, there have many works about synthetic and replay speech detection, researchers had proposed a number of anti-spoofing methods based on hand-crafted features to improve the accuracy and robustness of synthetic and replay speech detection system. However, using hand-crafted features rather than raw waveform would lose certain information for anti-spoofing, which will reduce the detection performance of the system. Inspired by the promising performance of ConvNext in image classification tasks, we extend the ConvNext network architecture accordingly for spoof attacks detection task and propose an end-to-end anti-spoofing model. By integrating the extended architecture with the channel attention block, the proposed model can focus on the most informative sub-bands of speech representations to improve the anti-spoofing performance. Experiments show that our proposed best single system could achieve an equal error rate of 1.88% and 2.79% for the ASVSpoof 2019 LA evaluation dataset and PA evaluation dataset respectively, which demonstrate the model's capacity for anti-spoofing.