 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-guided Style Transfer Network for Purifying Real Images
Mar 19, 2019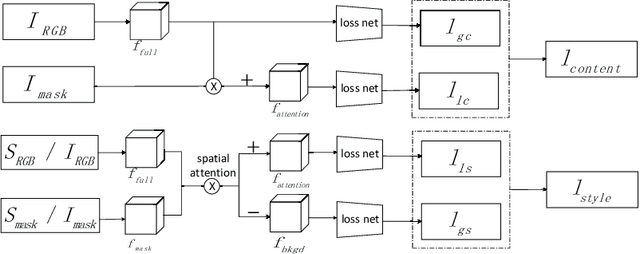

Recently, the progress of learning-by-synthesis has proposed a training model for synthetic images, which can effectively reduce the cost of human and material resources. However, due to the different distribution of synthetic images compared with real images, the desired performance cannot be achieved. To solve this problem, the previous method learned a model to improve the realism of the synthetic images. Different from the previous methods, this paper try to purify real image by extracting discriminative and robust features to convert outdoor real images to indoor synthetic images. In this paper, we first introduce the segmentation masks to construct RGB-mask pairs as inputs, then we design a mask-guided style transfer network to learn style features separately from the attention and bkgd(background) regions and learn content features from full and attention region. Moreover, we propose a novel region-level task-guided loss to restrain the features learnt from style and content. Experiments were performed using mixed studies (qualitative and quantitative) methods to demonstrate the possibility of purifying real images in complex directions. We evaluate the proposed method on various public datasets, including LPW, COCO and MPIIGaze. Experimental results show that the proposed method is effective and achieves the state-of-the-art results.
Purifying Naturalistic Images through a Real-time Style Transfer Semantics Network
Mar 14, 2019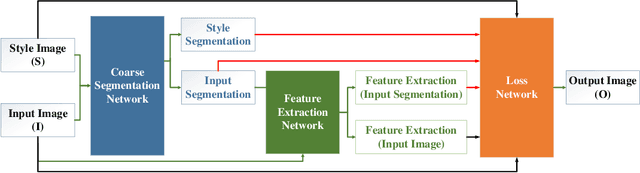

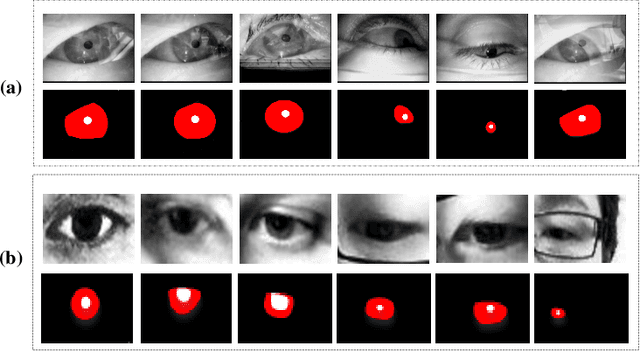
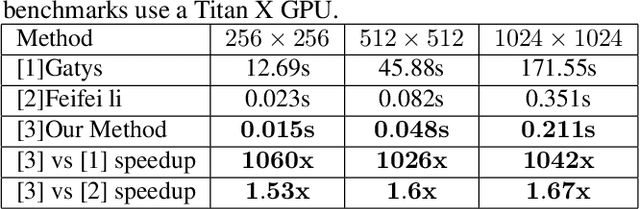
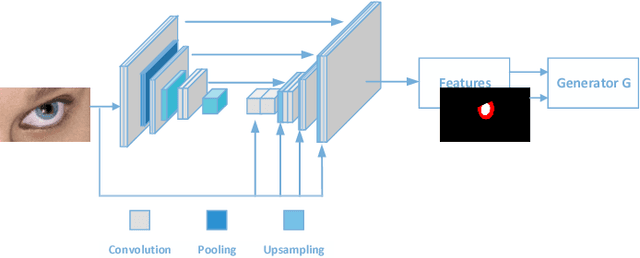
Recently, the progress of learning-by-synthesis has proposed a training model for synthetic images, which can effectively reduce the cost of human and material resources. However, due to the different distribution of synthetic images compared to real images, the desired performance cannot still be achieved. Real images consist of multiple forms of light orientation, while synthetic images consist of a uniform light orientation. These features are considered to be characteristic of outdoor and indoor scenes, respectively. To solve this problem, the previous method learned a model to improve the realism of the synthetic image. Different from the previous methods, this paper takes the first step to purify real images. Through the style transfer task, the distribution of outdoor real images is converted into indoor synthetic images, thereby reducing the influence of light. Therefore, this paper proposes a real-time style transfer network that preserves image content information (eg, gaze direction, pupil center position) of an input image (real image) while inferring style information (eg, image color structure, semantic features) of style image (synthetic image). In addition, the network accelerates the convergence speed of the model and adapts to multi-scale images. Experiments were performed using mixed studies (qualitative and quantitative) methods to demonstrate the possibility of purifying real images in complex directions. Qualitatively, it compares the proposed method with the available methods in a series of indoor and outdoor scenarios of the LPW dataset. In quantitative terms, it evaluates the purified image by training a gaze estimation model on the cross data set. The results show a significant improvement over the baseline method compared to the raw real image.
Guiding Intelligent Surveillance System by learning-by-synthesis gaze estimation
Oct 08, 2018
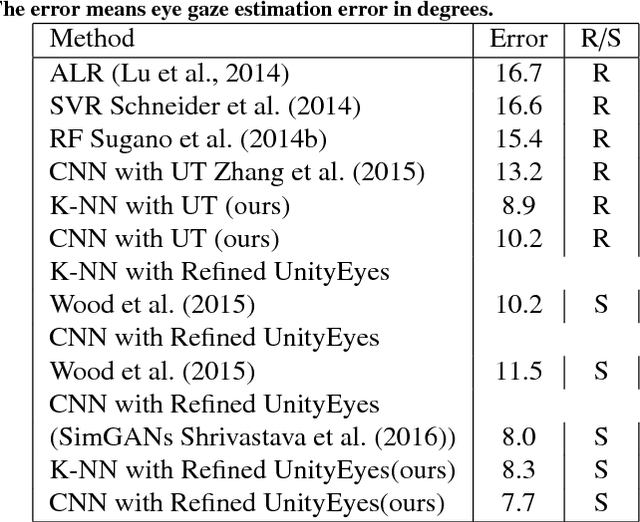

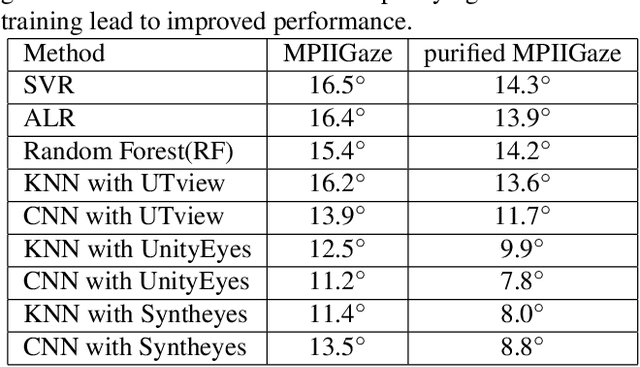
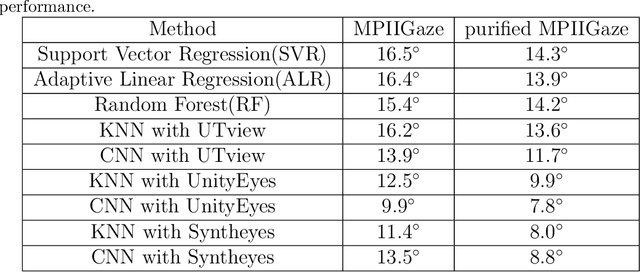
We describe a novel learning-by-synthesis method for estimating gaze direction of an automated intelligent surveillance system. Recently, progress in learning-by-synthesis has proposed training models on synthetic images, which can effectively reduce the cost of manpower and material resources. However, learning from synthetic images still fails to achieve the desired performance compared to naturalistic images due to the different distribution of synthetic images. In an attempt to address this issue, previous method is to improve the realism of synthetic images by learning a model. However, the disadvantage of the method is that the distortion has not been improved and the authenticity level is unstable. To solve this problem, we put forward a new structure to improve synthetic images, via the reference to the idea of style transformation, through which we can efficiently reduce the distortion of pictures and minimize the need of real data annotation. We estimate that this enables generation of highly realistic images, which we demonstrate both qualitatively and with a user study. We quantitatively evaluate the generated images by training models for gaze estimation. We show a significant improvement over using synthetic images, and achieve state-of-the-art results on various datasets including MPIIGaze dataset.