 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCvFormer: Cross-view transFormers with Pre-training for fMRI Analysis of Human Brain
Sep 14, 2023In recent years, functional magnetic resonance imaging (fMRI) has been widely utilized to diagnose neurological disease, by exploiting the region of interest (RoI) nodes as well as their connectivities in human brain. However, most of existing works only rely on either RoIs or connectivities, neglecting the potential for complementary information between them. To address this issue, we study how to discover the rich cross-view information in fMRI data of human brain. This paper presents a novel method for cross-view analysis of fMRI data of the human brain, called Cross-view transFormers (CvFormer). CvFormer employs RoI and connectivity encoder modules to generate two separate views of the human brain, represented as RoI and sub-connectivity tokens. Then, basic transformer modules can be used to process the RoI and sub-connectivity tokens, and cross-view modules integrate the complement information across two views. Furthermore, CvFormer uses a global token for each branch as a query to exchange information with other branches in cross-view modules, which only requires linear time for both computational and memory complexity instead of quadratic time. To enhance the robustness of the proposed CvFormer, we propose a two-stage strategy to train its parameters. To be specific, RoI and connectivity views can be firstly utilized as self-supervised information to pre-train the CvFormer by combining it with contrastive learning and then fused to finetune the CvFormer using label information. Experiment results on two public ABIDE and ADNI datasets can show clear improvements by the proposed CvFormer, which can validate its effectiveness and superiority.
TiBGL: Template-induced Brain Graph Learning for Functional Neuroimaging Analysis
Sep 14, 2023In recent years, functional magnetic resonance imaging has emerged as a powerful tool for investigating the human brain's functional connectivity networks. Related studies demonstrate that functional connectivity networks in the human brain can help to improve the efficiency of diagnosing neurological disorders. However, there still exist two challenges that limit the progress of functional neuroimaging. Firstly, there exists an abundance of noise and redundant information in functional connectivity data, resulting in poor performance. Secondly, existing brain network models have tended to prioritize either classification performance or the interpretation of neuroscience findings behind the learned models. To deal with these challenges, this paper proposes a novel brain graph learning framework called Template-induced Brain Graph Learning (TiBGL), which has both discriminative and interpretable abilities. Motivated by the related medical findings on functional connectivites, TiBGL proposes template-induced brain graph learning to extract template brain graphs for all groups. The template graph can be regarded as an augmentation process on brain networks that removes noise information and highlights important connectivity patterns. To simultaneously support the tasks of discrimination and interpretation, TiBGL further develops template-induced convolutional neural network and template-induced brain interpretation analysis. Especially, the former fuses rich information from brain graphs and template brain graphs for brain disorder tasks, and the latter can provide insightful connectivity patterns related to brain disorders based on template brain graphs. Experimental results on three real-world datasets show that the proposed TiBGL can achieve superior performance compared with nine state-of-the-art methods and keep coherent with neuroscience findings in recent literatures.
TCGF: A unified tensorized consensus graph framework for multi-view representation learning
Sep 14, 2023



Multi-view learning techniques have recently gained significant attention in the machine learning domain for their ability to leverage consistency and complementary information across multiple views. However, there remains a lack of sufficient research on generalized multi-view frameworks that unify existing works into a scalable and robust learning framework, as most current works focus on specific styles of multi-view models. Additionally, most multi-view learning works rely heavily on specific-scale scenarios and fail to effectively comprehend multiple scales holistically. These limitations hinder the effective fusion of essential information from multiple views, resulting in poor generalization. To address these limitations, this paper proposes a universal multi-view representation learning framework named Tensorized Consensus Graph Framework (TCGF). Specifically, it first provides a unified framework for existing multi-view works to exploit the representations for individual view, which aims to be suitable for arbitrary assumptions and different-scales datasets. Then, stacks them into a tensor under alignment basics as a high-order representation, allowing for the smooth propagation of consistency and complementary information across all views. Moreover, TCGF proposes learning a consensus embedding shared by adaptively collaborating all views to uncover the essential structure of the multi-view data, which utilizes view-consensus grouping effect to regularize the view-consensus representation. To further facilitate related research, we provide a specific implementation of TCGF for large-scale datasets, which can be efficiently solved by applying the alternating optimization strategy. Experimental results conducted on seven different-scales datasets indicate the superiority of the proposed TCGF against existing state-of-the-art multi-view learning methods.
Locality Relationship Constrained Multi-view Clustering Framework
Jul 11, 2021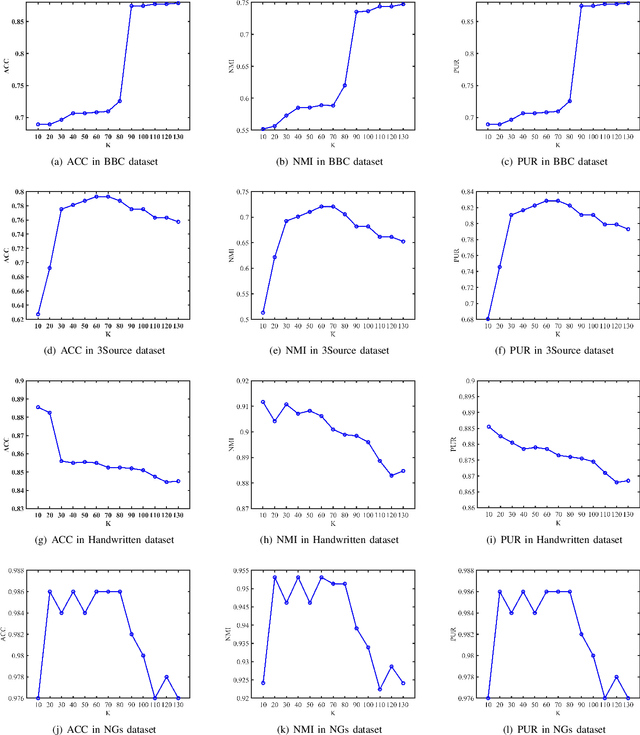



In most practical applications, it's common to utilize multiple features from different views to represent one object. Among these works, multi-view subspace-based clustering has gained extensive attention from many researchers, which aims to provide clustering solutions to multi-view data. However, most existing methods fail to take full use of the locality geometric structure and similarity relationship among samples under the multi-view scenario. To solve these issues, we propose a novel multi-view learning method with locality relationship constraint to explore the problem of multi-view clustering, called Locality Relationship Constrained Multi-view Clustering Framework (LRC-MCF). LRC-MCF aims to explore the diversity, geometric, consensus and complementary information among different views, by capturing the locality relationship information and the common similarity relationships among multiple views. Moreover, LRC-MCF takes sufficient consideration to weights of different views in finding the common-view locality structure and straightforwardly produce the final clusters. To effectually reduce the redundancy of the learned representations, the low-rank constraint on the common similarity matrix is considered additionally. To solve the minimization problem of LRC-MCF, an Alternating Direction Minimization (ADM) method is provided to iteratively calculate all variables LRC-MCF. Extensive experimental results on seven benchmark multi-view datasets validate the effectiveness of the LRC-MCF method.
A unified framework based on graph consensus term for multi-view learning
May 25, 2021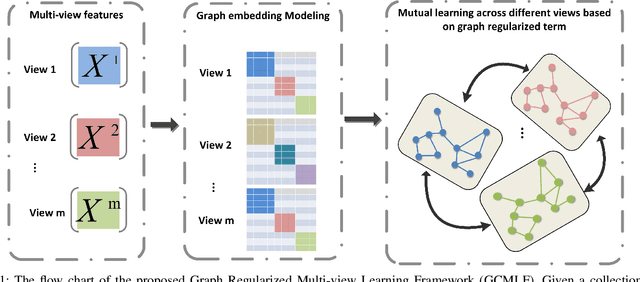
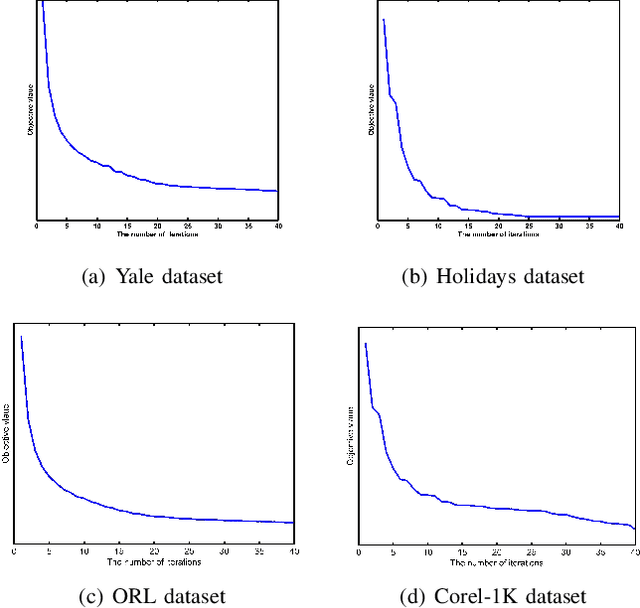

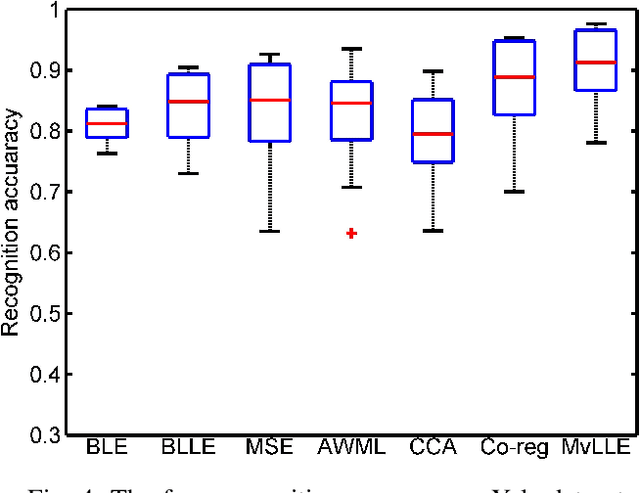
In recent years, multi-view learning technologies for various applications have attracted a surge of interest. Due to more compatible and complementary information from multiple views, existing multi-view methods could achieve more promising performance than conventional single-view methods in most situations. However, there are still no sufficient researches on the unified framework in existing multi-view works. Meanwhile, how to efficiently integrate multi-view information is still full of challenges. In this paper, we propose a novel multi-view learning framework, which aims to leverage most existing graph embedding works into a unified formula via introducing the graph consensus term. In particular, our method explores the graph structure in each view independently to preserve the diversity property of graph embedding methods. Meanwhile, we choose heterogeneous graphs to construct the graph consensus term to explore the correlations among multiple views jointly. To this end, the diversity and complementary information among different views could be simultaneously considered. Furthermore, the proposed framework is utilized to implement the multi-view extension of Locality Linear Embedding, named Multi-view Locality Linear Embedding (MvLLE), which could be efficiently solved by applying the alternating optimization strategy. Empirical validations conducted on six benchmark datasets can show the effectiveness of our proposed method.
Multimodal-Aware Weakly Supervised Metric Learning with Self-weighting Triplet Loss
Feb 03, 2021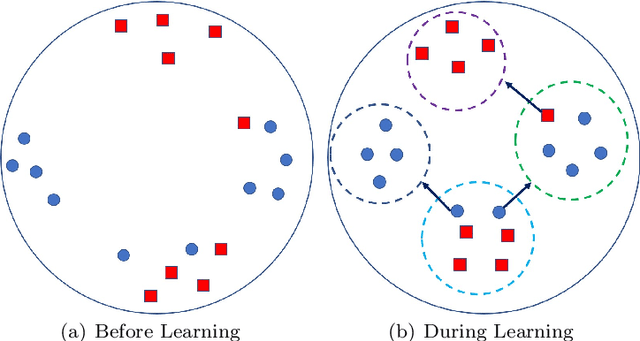

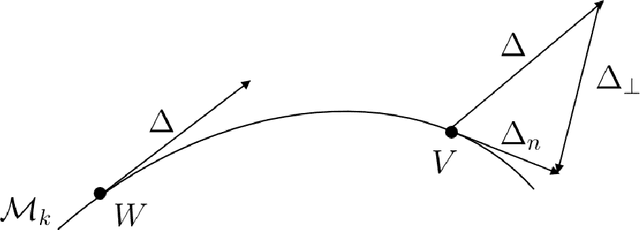
In recent years, we have witnessed a surge of interests in learning a suitable distance metric from weakly supervised data. Most existing methods aim to pull all the similar samples closer while push the dissimilar ones as far as possible. However, when some classes of the dataset exhibit multimodal distribution, these goals conflict and thus can hardly be concurrently satisfied. Additionally, to ensure a valid metric, many methods require a repeated eigenvalue decomposition process, which is expensive and numerically unstable. Therefore, how to learn an appropriate distance metric from weakly supervised data remains an open but challenging problem. To address this issue, in this paper, we propose a novel weakly supervised metric learning algorithm, named MultimoDal Aware weakly supervised Metric Learning (MDaML). MDaML partitions the data space into several clusters and allocates the local cluster centers and weight for each sample. Then, combining it with the weighted triplet loss can further enhance the local separability, which encourages the local dissimilar samples to keep a large distance from the local similar samples. Meanwhile, MDaML casts the metric learning problem into an unconstrained optimization on the SPD manifold, which can be efficiently solved by Riemannian Conjugate Gradient Descent (RCGD). Extensive experiments conducted on 13 datasets validate the superiority of the proposed MDaML.
Multi-view Low-rank Preserving Embedding: A Novel Method for Multi-view Representation
Jun 14, 2020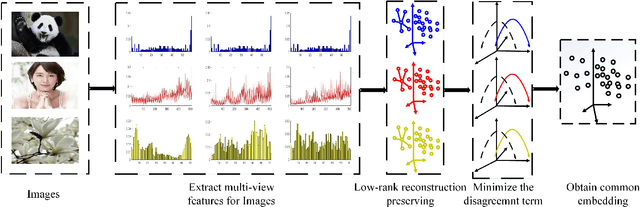
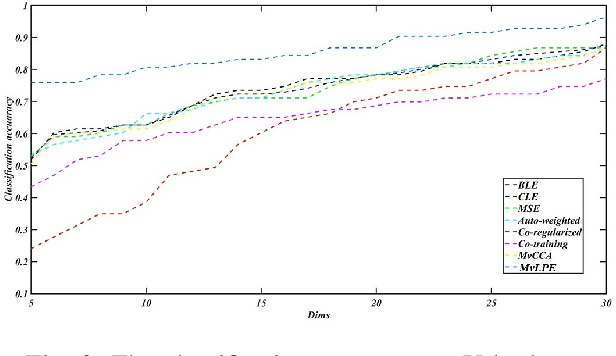
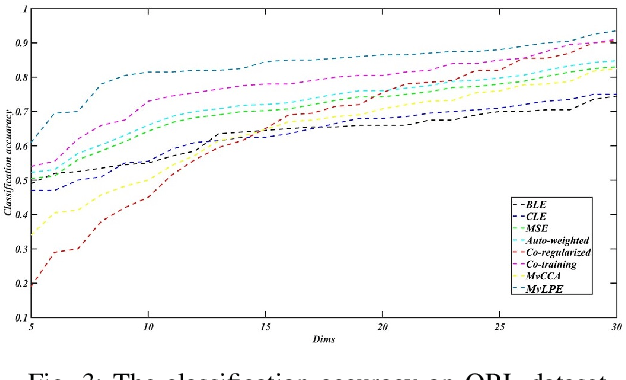
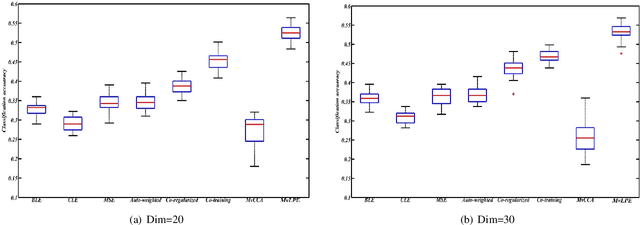
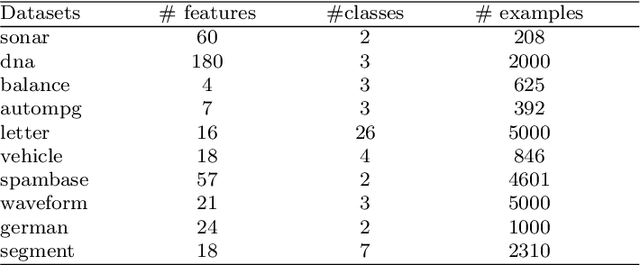
In recent years, we have witnessed a surge of interest in multi-view representation learning, which is concerned with the problem of learning representations of multi-view data. When facing multiple views that are highly related but sightly different from each other, most of existing multi-view methods might fail to fully integrate multi-view information. Besides, correlations between features from multiple views always vary seriously, which makes multi-view representation challenging. Therefore, how to learn appropriate embedding from multi-view information is still an open problem but challenging. To handle this issue, this paper proposes a novel multi-view learning method, named Multi-view Low-rank Preserving Embedding (MvLPE). It integrates different views into one centroid view by minimizing the disagreement term, based on distance or similarity matrix among instances, between the centroid view and each view meanwhile maintaining low-rank reconstruction relations among samples for each view, which could make more full use of compatible and complementary information from multi-view features. Unlike existing methods with additive parameters, the proposed method could automatically allocate a suitable weight for each view in multi-view information fusion. However, MvLPE couldn't be directly solved, which makes the proposed MvLPE difficult to obtain an analytic solution. To this end, we approximate this solution based on stationary hypothesis and normalization post-processing to efficiently obtain the optimal solution. Furthermore, an iterative alternating strategy is provided to solve this multi-view representation problem. The experiments on six benchmark datasets demonstrate that the proposed method outperforms its counterparts while achieving very competitive performance.
The Similarity-Consensus Regularized Multi-view Learning for Dimension Reduction
Nov 15, 2019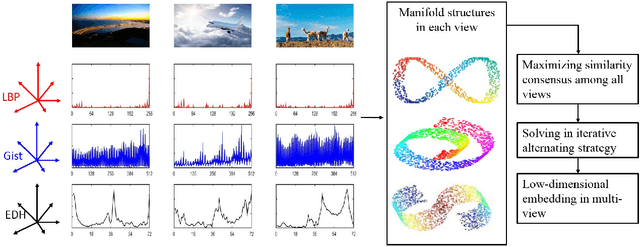
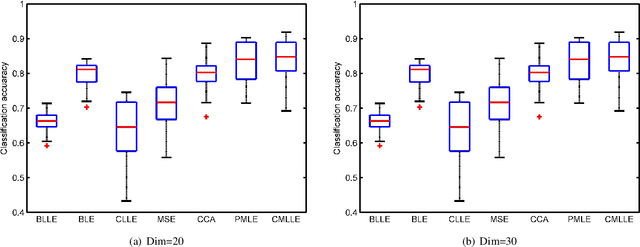
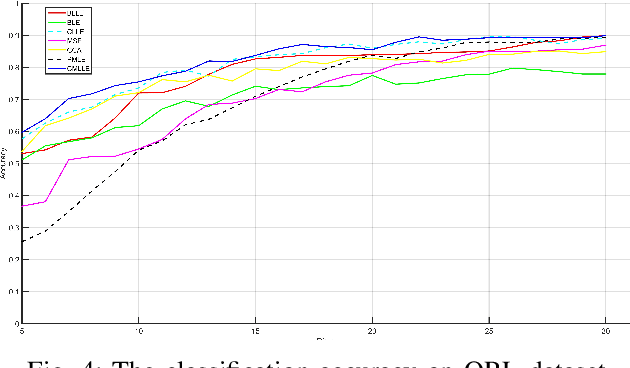
During the last decades, learning a low-dimensional space with discriminative information for dimension reduction (DR) has gained a surge of interest. However, it's not accessible for these DR methods to achieve satisfactory performance when facing the features from multiple views. In multi-view learning problems, one instance can be represented by multiple heterogeneous features, which are highly related but sometimes look different from each other. In addition, correlations between features from multiple views always vary greatly, which challenges the capability of multi-view learning methods. Consequently, constructing a multi-view learning framework with generalization and scalability, which could take advantage of multi-view information as much as possible, is extremely necessary but challenging. To implement the above target, this paper proposes a novel multi-view learning framework based on similarity consensus, which makes full use of correlations among multi-view features while considering the scalability and robustness of the framework. It aims to straightforwardly extend those existing DR methods into multi-view learning domain by preserving the similarity between different views to capture the low-dimensional embedding. Two schemes based on pairwise-consensus and centroid-consensus are separately proposed to force multiple views to learn from each other and then an iterative alternating strategy is developed to obtain the optimal solution. The proposed method is evaluated on 5 benchmark datasets and comprehensive experiments show that our proposed multi-view framework can yield comparable and promising performance with previous approaches proposed in recent literatures.
Multi-view Locality Low-rank Embedding for Dimension Reduction
May 20, 2019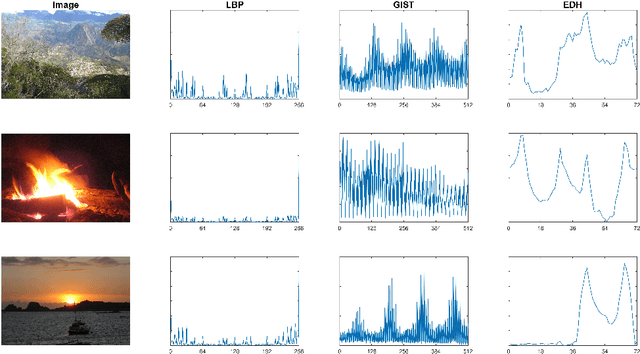


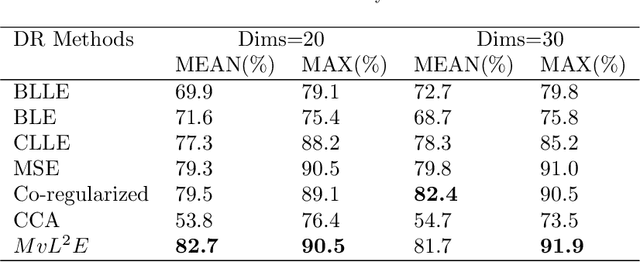
During the last decades, we have witnessed a surge of interests of learning a low-dimensional space with discriminative information from one single view. Even though most of them can achieve satisfactory performance in some certain situations, they fail to fully consider the information from multiple views which are highly relevant but sometimes look different from each other. Besides, correlations between features from multiple views always vary greatly, which challenges multi-view subspace learning. Therefore, how to learn an appropriate subspace which can maintain valuable information from multi-view features is of vital importance but challenging. To tackle this problem, this paper proposes a novel multi-view dimension reduction method named Multi-view Locality Low-rank Embedding for Dimension Reduction (MvL2E). MvL2E makes full use of correlations between multi-view features by adopting low-rank representations. Meanwhile, it aims to maintain the correlations and construct a suitable manifold space to capture the low-dimensional embedding for multi-view features. A centroid based scheme is designed to force multiple views to learn from each other. And an iterative alternating strategy is developed to obtain the optimal solution of MvL2E. The proposed method is evaluated on 5 benchmark datasets. Comprehensive experiments show that our proposed MvL2E can achieve comparable performance with previous approaches proposed in recent literatures.