 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMFORT: A Continual Fine-Tuning Framework for Foundation Models Targeted at Consumer Healthcare
Sep 14, 2024



Wearable medical sensors (WMSs) are revolutionizing smart healthcare by enabling continuous, real-time monitoring of user physiological signals, especially in the field of consumer healthcare. The integration of WMSs and modern machine learning (ML) enables unprecedented solutions to efficient early-stage disease detection. Despite the success of Transformers in various fields, their application to sensitive domains, such as smart healthcare, remains underexplored due to limited data accessibility and privacy concerns. To bridge the gap between Transformer-based foundation models and WMS-based disease detection, we propose COMFORT, a continual fine-tuning framework for foundation models targeted at consumer healthcare. COMFORT introduces a novel approach for pre-training a Transformer-based foundation model on a large dataset of physiological signals exclusively collected from healthy individuals with commercially available WMSs. We adopt a masked data modeling (MDM) objective to pre-train this health foundation model. We then fine-tune the model using various parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, to adapt it to various downstream disease detection tasks that rely on WMS data. In addition, COMFORT continually stores the low-rank decomposition matrices obtained from the PEFT algorithms to construct a library for multi-disease detection. The COMFORT library enables scalable and memory-efficient disease detection on edge devices. Our experimental results demonstrate that COMFORT achieves highly competitive performance while reducing memory overhead by up to 52% relative to conventional methods. Thus, COMFORT paves the way for personalized and proactive solutions to efficient and effective early-stage disease detection for consumer healthcare.
PAGE: Domain-Incremental Adaptation with Past-Agnostic Generative Replay for Smart Healthcare
Mar 13, 2024
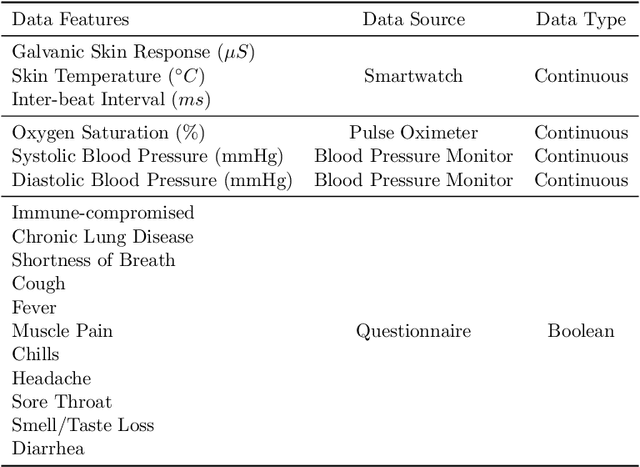

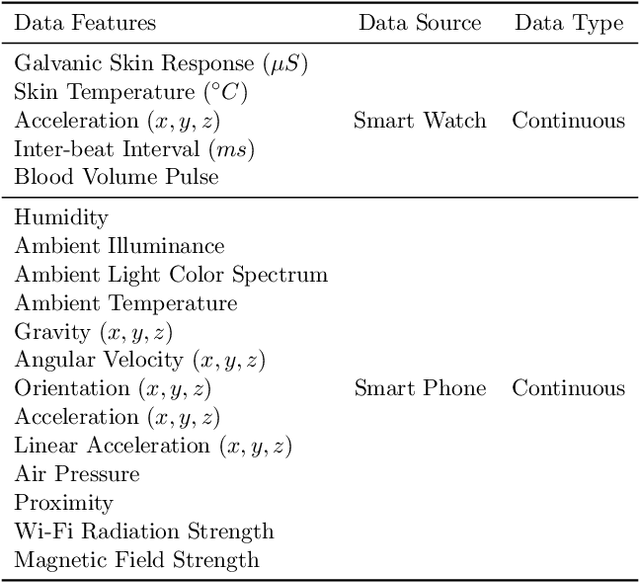
We propose PAGE, a domain-incremental adaptation strategy with past-agnostic generative replay for smart healthcare. PAGE enables generative replay without the aid of any preserved data or information from prior domains. When adapting to a new domain, it exploits real data from the new distribution and the current model to generate synthetic data that retain the learned knowledge of previous domains. By replaying the synthetic data with the new real data during training, PAGE achieves a good balance between domain adaptation and knowledge retention. In addition, we incorporate an extended inductive conformal prediction (EICP) method into PAGE to produce a confidence score and a credibility value for each detection result. This makes the predictions interpretable and provides statistical guarantees for disease detection in smart healthcare applications. We demonstrate PAGE's effectiveness in domain-incremental disease detection with three distinct disease datasets collected from commercially available WMSs. PAGE achieves highly competitive performance against state-of-the-art with superior scalability, data privacy, and feasibility. Furthermore, PAGE can enable up to 75% reduction in clinical workload with the help of EICP.
DOCTOR: A Multi-Disease Detection Continual Learning Framework Based on Wearable Medical Sensors
May 09, 2023Modern advances in machine learning (ML) and wearable medical sensors (WMSs) in edge devices have enabled ML-driven disease detection for smart healthcare. Conventional ML-driven disease detection methods rely on customizing individual models for each disease and its corresponding WMS data. However, such methods lack adaptability to distribution shifts and new task classification classes. Also, they need to be rearchitected and retrained from scratch for each new disease. Moreover, installing multiple ML models in an edge device consumes excessive memory, drains the battery faster, and complicates the detection process. To address these challenges, we propose DOCTOR, a multi-disease detection continual learning (CL) framework based on WMSs. It employs a multi-headed deep neural network (DNN) and an exemplar-replay-style CL algorithm. The CL algorithm enables the framework to continually learn new missions where different data distributions, classification classes, and disease detection tasks are introduced sequentially. It counteracts catastrophic forgetting with a data preservation method and a synthetic data generation module. The data preservation method efficiently preserves the most informative subset of training data from previous missions based on the average training loss of each data instance. The synthetic data generation module models the probability distribution of the real training data and then generates as much synthetic data as needed for replays while maintaining data privacy. The multi-headed DNN enables DOCTOR to detect multiple diseases simultaneously based on user WMS data. We demonstrate DOCTOR's efficacy in maintaining high multi-disease classification accuracy with a single DNN model in various CL experiments. DOCTOR achieves very competitive performance across all CL scenarios relative to the ideal joint-training framework while maintaining a small model size.
CODEBench: A Neural Architecture and Hardware Accelerator Co-Design Framework
Dec 07, 2022Recently, automated co-design of machine learning (ML) models and accelerator architectures has attracted significant attention from both the industry and academia. However, most co-design frameworks either explore a limited search space or employ suboptimal exploration techniques for simultaneous design decision investigations of the ML model and the accelerator. Furthermore, training the ML model and simulating the accelerator performance is computationally expensive. To address these limitations, this work proposes a novel neural architecture and hardware accelerator co-design framework, called CODEBench. It is composed of two new benchmarking sub-frameworks, CNNBench and AccelBench, which explore expanded design spaces of convolutional neural networks (CNNs) and CNN accelerators. CNNBench leverages an advanced search technique, BOSHNAS, to efficiently train a neural heteroscedastic surrogate model to converge to an optimal CNN architecture by employing second-order gradients. AccelBench performs cycle-accurate simulations for a diverse set of accelerator architectures in a vast design space. With the proposed co-design method, called BOSHCODE, our best CNN-accelerator pair achieves 1.4% higher accuracy on the CIFAR-10 dataset compared to the state-of-the-art pair, while enabling 59.1% lower latency and 60.8% lower energy consumption. On the ImageNet dataset, it achieves 3.7% higher Top1 accuracy at 43.8% lower latency and 11.2% lower energy consumption. CODEBench outperforms the state-of-the-art framework, i.e., Auto-NBA, by achieving 1.5% higher accuracy and 34.7x higher throughput, while enabling 11.0x lower energy-delay product (EDP) and 4.0x lower chip area on CIFAR-10.