 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexiBERT: Are Current Transformer Architectures too Homogeneous and Rigid?
Paper and Code
May 23, 2022
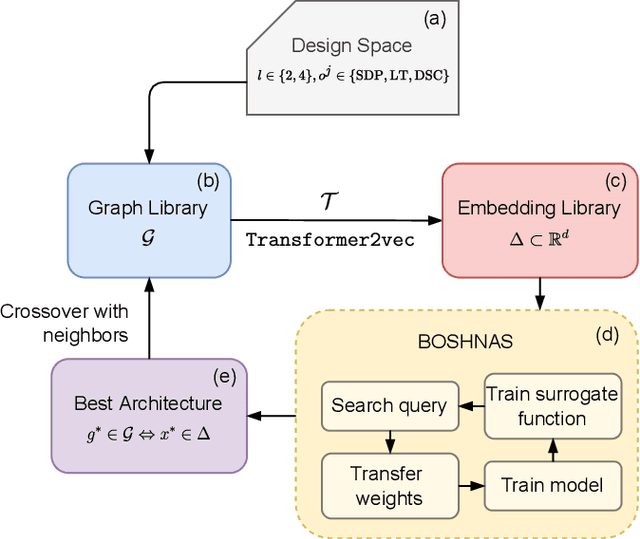
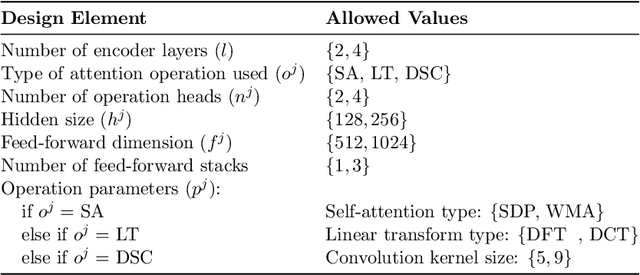
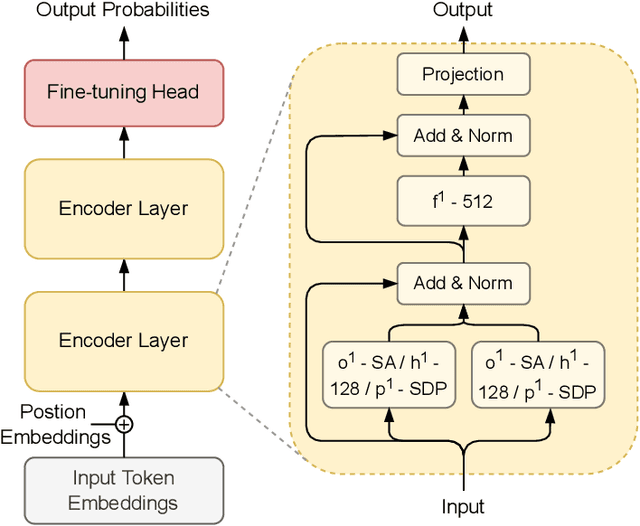
The existence of a plethora of language models makes the problem of selecting the best one for a custom task challenging. Most state-of-the-art methods leverage transformer-based models (e.g., BERT) or their variants. Training such models and exploring their hyperparameter space, however, is computationally expensive. Prior work proposes several neural architecture search (NAS) methods that employ performance predictors (e.g., surrogate models) to address this issue; however, analysis has been limited to homogeneous models that use fixed dimensionality throughout the network. This leads to sub-optimal architectures. To address this limitation, we propose a suite of heterogeneous and flexible models, namely FlexiBERT, that have varied encoder layers with a diverse set of possible operations and different hidden dimensions. For better-posed surrogate modeling in this expanded design space, we propose a new graph-similarity-based embedding scheme. We also propose a novel NAS policy, called BOSHNAS, that leverages this new scheme, Bayesian modeling, and second-order optimization, to quickly train and use a neural surrogate model to converge to the optimal architecture. A comprehensive set of experiments shows that the proposed policy, when applied to the FlexiBERT design space, pushes the performance frontier upwards compared to traditional models. FlexiBERT-Mini, one of our proposed models, has 3% fewer parameters than BERT-Mini and achieves 8.9% higher GLUE score. A FlexiBERT model with equivalent performance as the best homogeneous model achieves 2.6x smaller size. FlexiBERT-Large, another proposed model, achieves state-of-the-art results, outperforming the baseline models by at least 5.7% on the GLUE benchmark.