 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering
Paper and Code
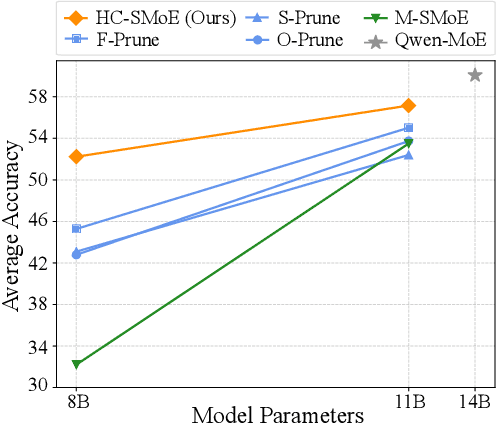

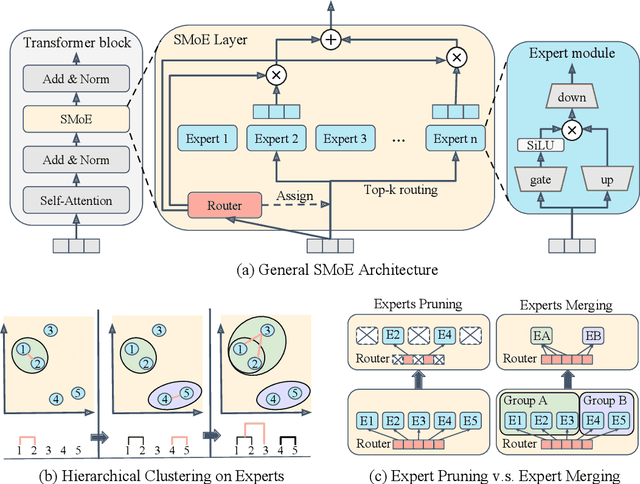
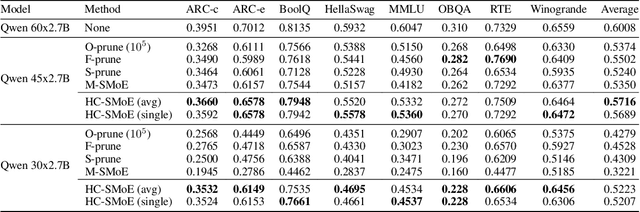
Sparse Mixture-of-Experts (SMoE) models represent a significant breakthrough in large language model development. These models enable performance improvements without a proportional increase in inference costs. By selectively activating a small set of parameters during task execution, SMoEs enhance model capacity. However, their deployment remains challenging due to the substantial memory footprint required to accommodate the growing number of experts. This constraint renders them less feasible in environments with limited hardware resources. To address this challenge, we propose Hierarchical Clustering for Sparsely activated Mixture of Experts (HC-SMoE), a task-agnostic expert merging framework that reduces SMoE model parameters without retraining. Unlike previous methods, HC-SMoE employs hierarchical clustering based on expert outputs. This approach ensures that the merging process remains unaffected by routing decisions. The output-based clustering strategy captures functional similarities between experts, offering an adaptable solution for models with numerous experts. We validate our approach through extensive experiments on eight zero-shot language tasks and demonstrate its effectiveness in large-scale SMoE models such as Qwen and Mixtral. Our comprehensive results demonstrate that HC-SMoE consistently achieves strong performance, which highlights its potential for real-world deployment.