 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDM-Prime-v2: Binary Encoding and Index Shuffling Enable Compute-optimal Scaling of Diffusion Language Models
Mar 17, 2026Masked diffusion models (MDM) exhibit superior generalization when learned using a Partial masking scheme (Prime). This approach converts tokens into sub-tokens and models the diffusion process at the sub-token level. We identify two limitations of the MDM-Prime framework. First, we lack tools to guide the hyperparameter choice of the token granularity in the subtokenizer. Second, we find that the function form of the subtokenizer significantly degrades likelihood estimation when paired with commonly used Byte-Pair-Encoding (BPE) tokenizers. To address these limitations, we study the tightness of the variational bound in MDM-Prime and develop MDM-Prime-v2, a masked diffusion language model which incorporates Binary Encoding and Index Shuffling. Our scaling analysis reveals that MDM-Prime-v2 is 21.8$\times$ more compute-efficient than autoregressive models (ARM). In compute-optimal comparisons, MDM-Prime-v2 achieves 7.77 perplexity on OpenWebText, outperforming ARM (12.99), MDM (18.94), and MDM-Prime (13.41). When extending the model size to 1.1B parameters, our model further demonstrates superior zero-shot accuracy on various commonsense reasoning tasks.
Beyond Masked and Unmasked: Discrete Diffusion Models via Partial Masking
May 24, 2025Masked diffusion models (MDM) are powerful generative models for discrete data that generate samples by progressively unmasking tokens in a sequence. Each token can take one of two states: masked or unmasked. We observe that token sequences often remain unchanged between consecutive sampling steps; consequently, the model repeatedly processes identical inputs, leading to redundant computation. To address this inefficiency, we propose the Partial masking scheme (Prime), which augments MDM by allowing tokens to take intermediate states interpolated between the masked and unmasked states. This design enables the model to make predictions based on partially observed token information, and facilitates a fine-grained denoising process. We derive a variational training objective and introduce a simple architectural design to accommodate intermediate-state inputs. Our method demonstrates superior performance across a diverse set of generative modeling tasks. On text data, it achieves a perplexity of 15.36 on OpenWebText, outperforming previous MDM (21.52), autoregressive models (17.54), and their hybrid variants (17.58), without relying on an autoregressive formulation. On image data, it attains competitive FID scores of 3.26 on CIFAR-10 and 6.98 on ImageNet-32, comparable to leading continuous generative models.
Retraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering
Oct 11, 2024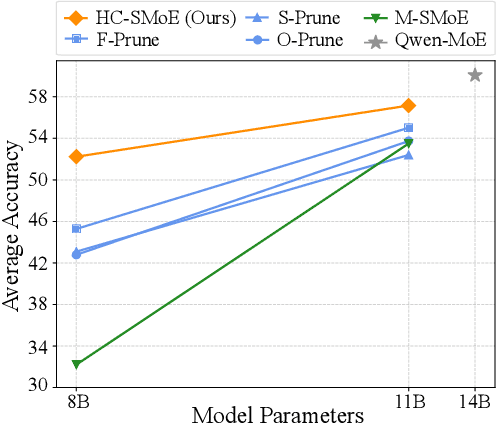

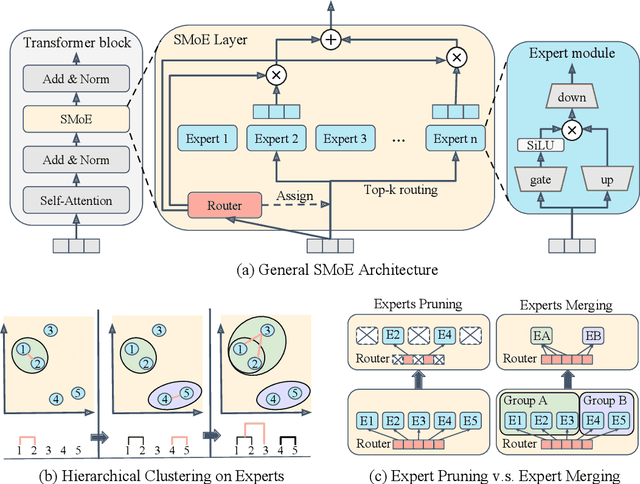
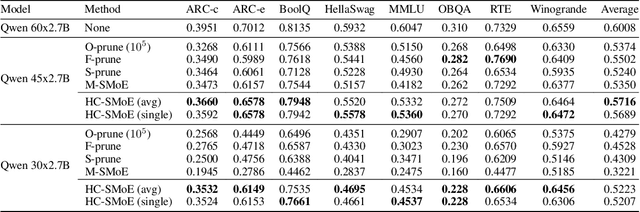
Sparse Mixture-of-Experts (SMoE) models represent a significant breakthrough in large language model development. These models enable performance improvements without a proportional increase in inference costs. By selectively activating a small set of parameters during task execution, SMoEs enhance model capacity. However, their deployment remains challenging due to the substantial memory footprint required to accommodate the growing number of experts. This constraint renders them less feasible in environments with limited hardware resources. To address this challenge, we propose Hierarchical Clustering for Sparsely activated Mixture of Experts (HC-SMoE), a task-agnostic expert merging framework that reduces SMoE model parameters without retraining. Unlike previous methods, HC-SMoE employs hierarchical clustering based on expert outputs. This approach ensures that the merging process remains unaffected by routing decisions. The output-based clustering strategy captures functional similarities between experts, offering an adaptable solution for models with numerous experts. We validate our approach through extensive experiments on eight zero-shot language tasks and demonstrate its effectiveness in large-scale SMoE models such as Qwen and Mixtral. Our comprehensive results demonstrate that HC-SMoE consistently achieves strong performance, which highlights its potential for real-world deployment.
Maximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
May 22, 2024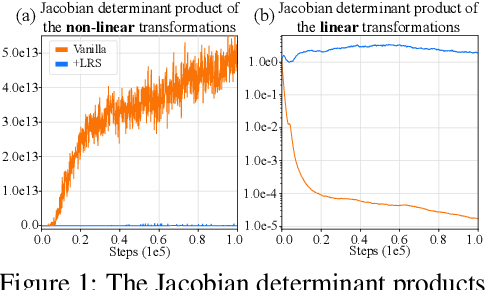
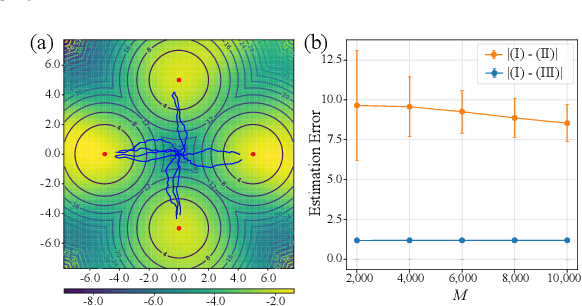
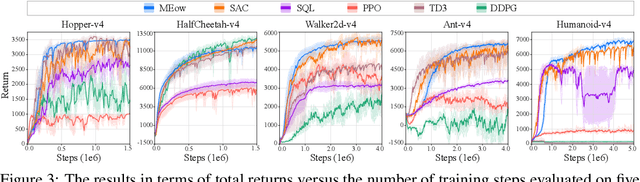
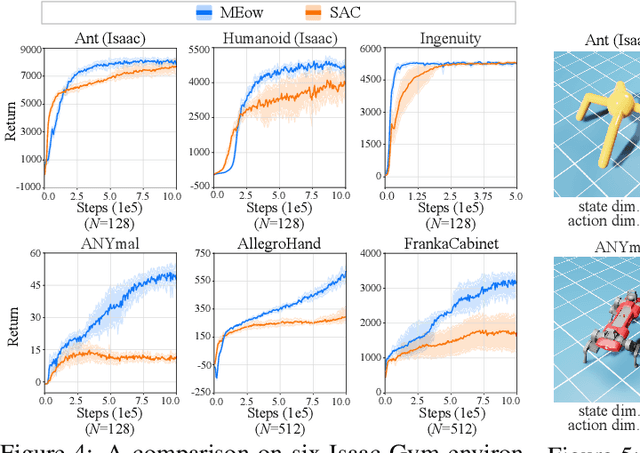
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
Training Energy-Based Normalizing Flow with Score-Matching Objectives
May 24, 2023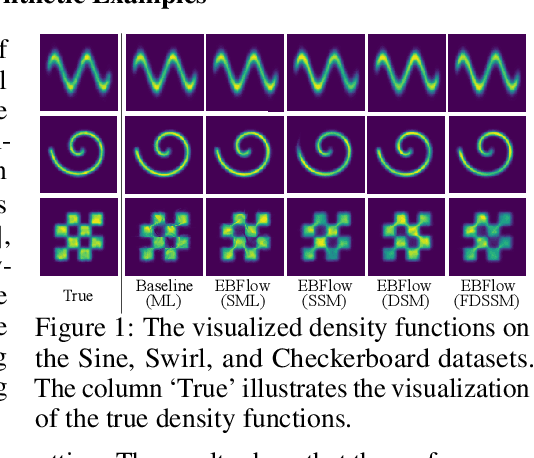

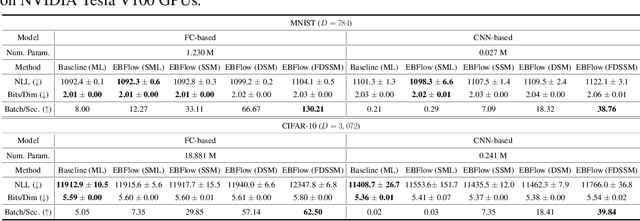
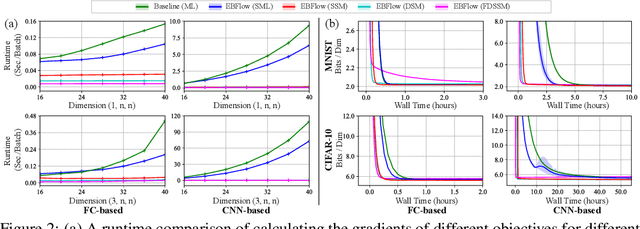
In this paper, we establish a connection between the parameterization of flow-based and energy-based generative models, and present a new flow-based modeling approach called energy-based normalizing flow (EBFlow). We demonstrate that by optimizing EBFlow with score-matching objectives, the computation of Jacobian determinants for linear transformations can be entirely bypassed. This feature enables the use of arbitrary linear layers in the construction of flow-based models without increasing the computational time complexity of each training iteration from $\mathcal{O}(D^2L)$ to $\mathcal{O}(D^3L)$ for an $L$-layered model that accepts $D$-dimensional inputs. This makes the training of EBFlow more efficient than the commonly-adopted maximum likelihood training method. In addition to the reduction in runtime, we enhance the training stability and empirical performance of EBFlow through a number of techniques developed based on our analysis on the score-matching methods. The experimental results demonstrate that our approach achieves a significant speedup compared to maximum likelihood estimation, while outperforming prior efficient training techniques with a noticeable margin in terms of negative log-likelihood (NLL).
ELDA: Using Edges to Have an Edge on Semantic Segmentation Based UDA
Nov 16, 2022



Many unsupervised domain adaptation (UDA) methods have been proposed to bridge the domain gap by utilizing domain invariant information. Most approaches have chosen depth as such information and achieved remarkable success. Despite their effectiveness, using depth as domain invariant information in UDA tasks may lead to multiple issues, such as excessively high extraction costs and difficulties in achieving a reliable prediction quality. As a result, we introduce Edge Learning based Domain Adaptation (ELDA), a framework which incorporates edge information into its training process to serve as a type of domain invariant information. In our experiments, we quantitatively and qualitatively demonstrate that the incorporation of edge information is indeed beneficial and effective and enables ELDA to outperform the contemporary state-of-the-art methods on two commonly adopted benchmarks for semantic segmentation based UDA tasks. In addition, we show that ELDA is able to better separate the feature distributions of different classes. We further provide an ablation analysis to justify our design decisions.
Quasi-Conservative Score-based Generative Models
Sep 26, 2022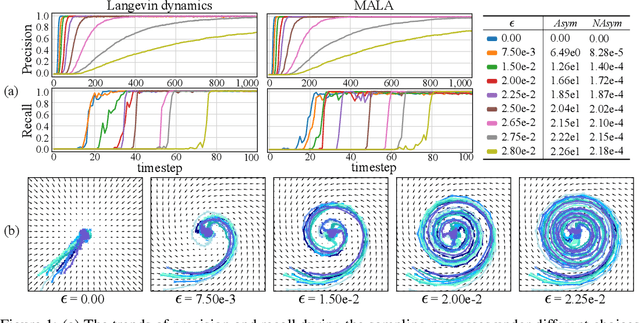
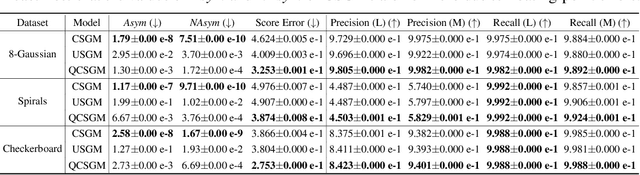
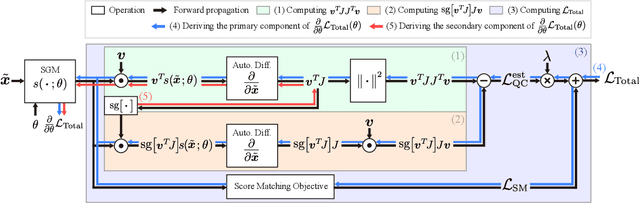
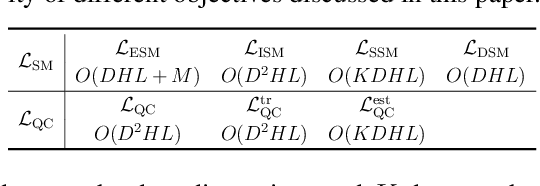
Existing Score-based Generative Models (SGMs) can be categorized into constrained SGMs (CSGMs) or unconstrained SGMs (USGMs) according to their parameterization approaches. CSGMs model the probability density functions as Boltzmann distributions, and assign their predictions as the negative gradients of some scalar-valued energy functions. On the other hand, USGMs employ flexible architectures capable of directly estimating scores without the need to explicitly model energy functions. In this paper, we demonstrate that the architectural constraints of CSGMs may limit their score-matching ability. In addition, we show that USGMs' inability to preserve the property of conservativeness may lead to serious sampling inefficiency and degraded sampling performance in practice. To address the above issues, we propose Quasi-Conservative Score-based Generative Models (QCSGMs) for keeping the advantages of both CSGMs and USGMs. Our theoretical derivations demonstrate that the training objective of QCSGMs can be efficiently integrated into the training processes by leveraging the Hutchinson trace estimator. In addition, our experimental results on the Cifar-10, Cifar-100, ImageNet, and SVHN datasets validate the effectiveness of QCSGMs. Finally, we justify the advantage of QCSGMs using an example of a one-layered autoencoder.
Denoising Likelihood Score Matching for Conditional Score-based Data Generation
Mar 27, 2022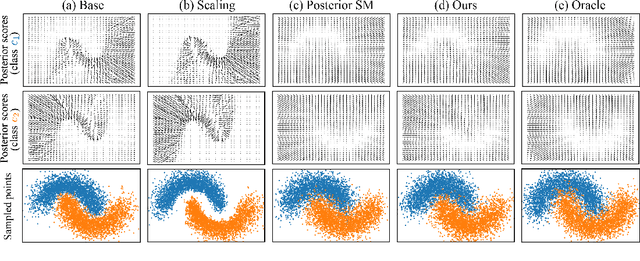
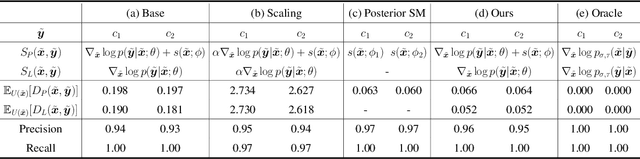

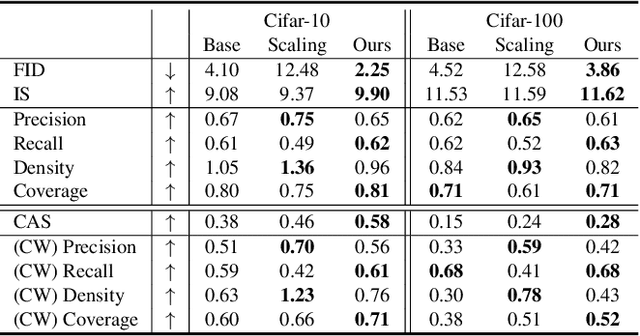
Many existing conditional score-based data generation methods utilize Bayes' theorem to decompose the gradients of a log posterior density into a mixture of scores. These methods facilitate the training procedure of conditional score models, as a mixture of scores can be separately estimated using a score model and a classifier. However, our analysis indicates that the training objectives for the classifier in these methods may lead to a serious score mismatch issue, which corresponds to the situation that the estimated scores deviate from the true ones. Such an issue causes the samples to be misled by the deviated scores during the diffusion process, resulting in a degraded sampling quality. To resolve it, we formulate a novel training objective, called Denoising Likelihood Score Matching (DLSM) loss, for the classifier to match the gradients of the true log likelihood density. Our experimental evidence shows that the proposed method outperforms the previous methods on both Cifar-10 and Cifar-100 benchmarks noticeably in terms of several key evaluation metrics. We thus conclude that, by adopting DLSM, the conditional scores can be accurately modeled, and the effect of the score mismatch issue is alleviated.
Rethinking Ensemble-Distillation for Semantic Segmentation Based Unsupervised Domain Adaptation
Apr 29, 2021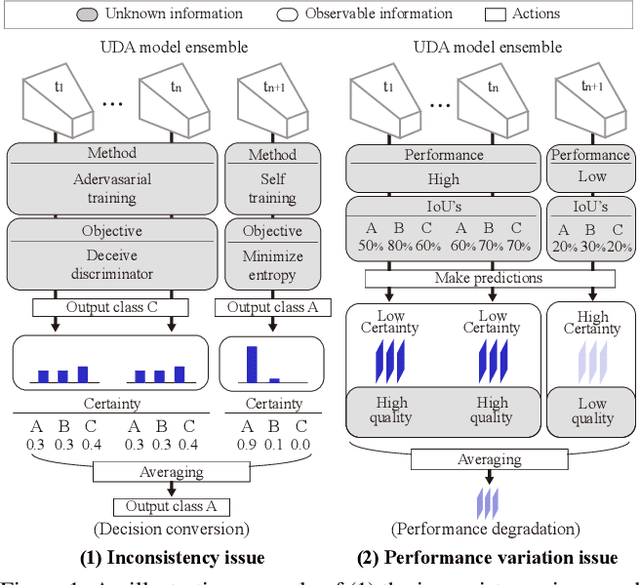
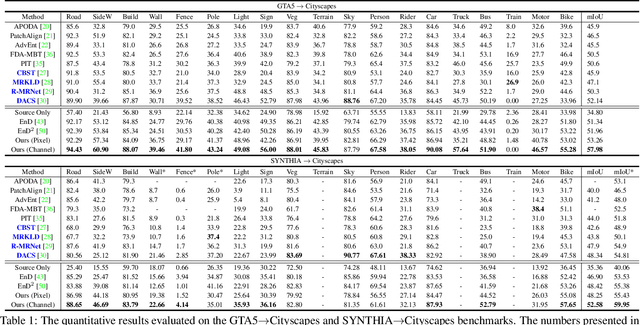
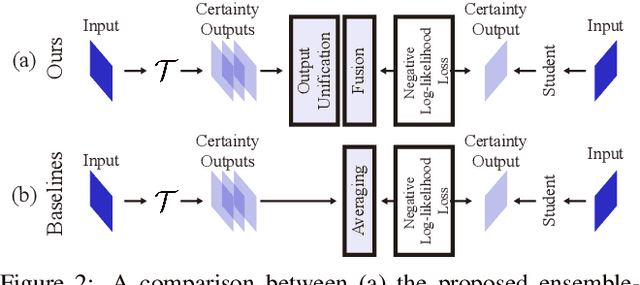
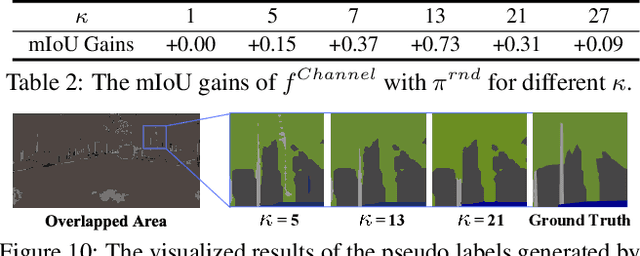
Recent researches on unsupervised domain adaptation (UDA) have demonstrated that end-to-end ensemble learning frameworks serve as a compelling option for UDA tasks. Nevertheless, these end-to-end ensemble learning methods often lack flexibility as any modification to the ensemble requires retraining of their frameworks. To address this problem, we propose a flexible ensemble-distillation framework for performing semantic segmentation based UDA, allowing any arbitrary composition of the members in the ensemble while still maintaining its superior performance. To achieve such flexibility, our framework is designed to be robust against the output inconsistency and the performance variation of the members within the ensemble. To examine the effectiveness and the robustness of our method, we perform an extensive set of experiments on both GTA5 to Cityscapes and SYNTHIA to Cityscapes benchmarks to quantitatively inspect the improvements achievable by our method. We further provide detailed analyses to validate that our design choices are practical and beneficial. The experimental evidence validates that the proposed method indeed offer superior performance, robustness and flexibility in semantic segmentation based UDA tasks against contemporary baseline methods.