 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy Reinforcement Learning via Energy-Based Normalizing Flow
May 22, 2024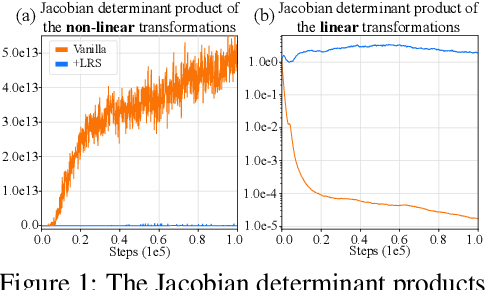
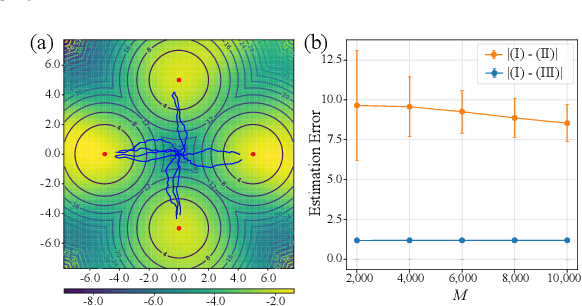
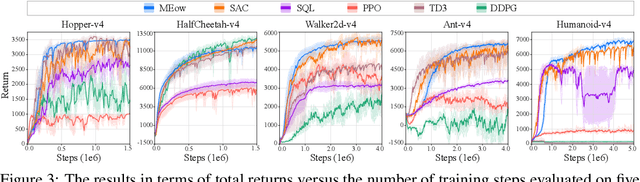
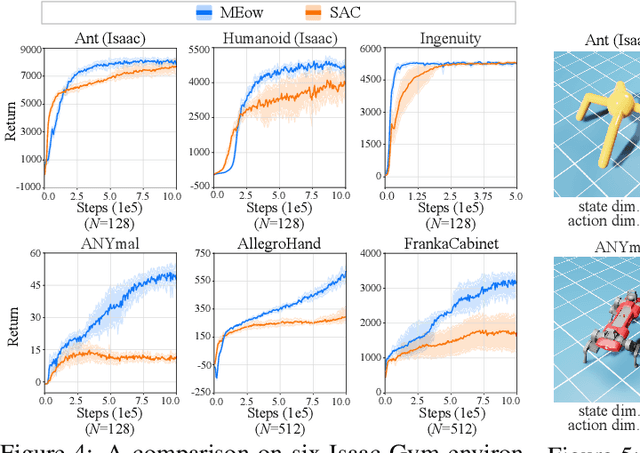
Existing Maximum-Entropy (MaxEnt) Reinforcement Learning (RL) methods for continuous action spaces are typically formulated based on actor-critic frameworks and optimized through alternating steps of policy evaluation and policy improvement. In the policy evaluation steps, the critic is updated to capture the soft Q-function. In the policy improvement steps, the actor is adjusted in accordance with the updated soft Q-function. In this paper, we introduce a new MaxEnt RL framework modeled using Energy-Based Normalizing Flows (EBFlow). This framework integrates the policy evaluation steps and the policy improvement steps, resulting in a single objective training process. Our method enables the calculation of the soft value function used in the policy evaluation target without Monte Carlo approximation. Moreover, this design supports the modeling of multi-modal action distributions while facilitating efficient action sampling. To evaluate the performance of our method, we conducted experiments on the MuJoCo benchmark suite and a number of high-dimensional robotic tasks simulated by Omniverse Isaac Gym. The evaluation results demonstrate that our method achieves superior performance compared to widely-adopted representative baselines.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 30, 2024



Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP
Expert Proximity as Surrogate Rewards for Single Demonstration Imitation Learning
Feb 01, 2024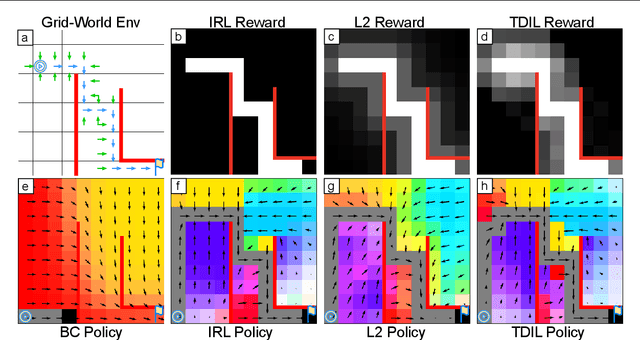
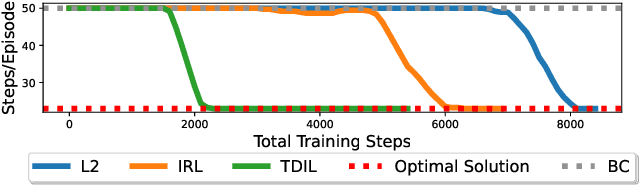
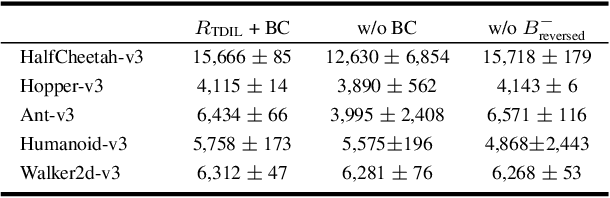
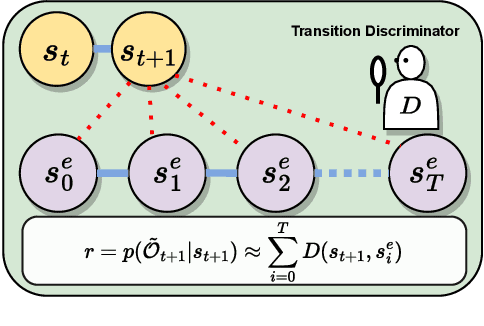
In this paper, we focus on single-demonstration imitation learning (IL), a practical approach for real-world applications where obtaining numerous expert demonstrations is costly or infeasible. In contrast to typical IL settings with multiple demonstrations, single-demonstration IL involves an agent having access to only one expert trajectory. We highlight the issue of sparse reward signals in this setting and propose to mitigate this issue through our proposed Transition Discriminator-based IL (TDIL) method. TDIL is an IRL method designed to address reward sparsity by introducing a denser surrogate reward function that considers environmental dynamics. This surrogate reward function encourages the agent to navigate towards states that are proximal to expert states. In practice, TDIL trains a transition discriminator to differentiate between valid and non-valid transitions in a given environment to compute the surrogate rewards. The experiments demonstrate that TDIL outperforms existing IL approaches and achieves expert-level performance in the single-demonstration IL setting across five widely adopted MuJoCo benchmarks as well as the "Adroit Door" environment.