 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Auxiliary Energy Consumption for Electric Heavy-Duty Vehicles
Nov 27, 2023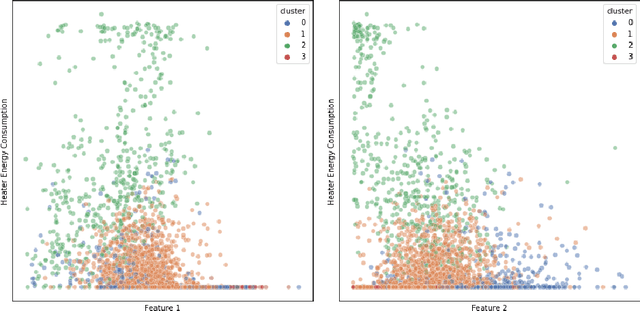
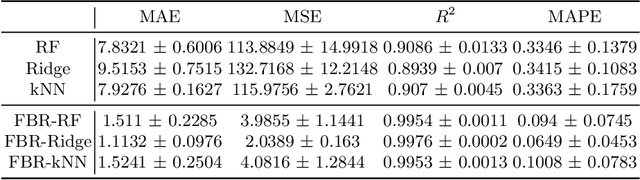
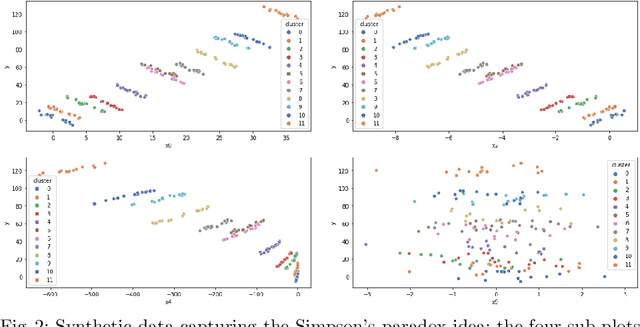
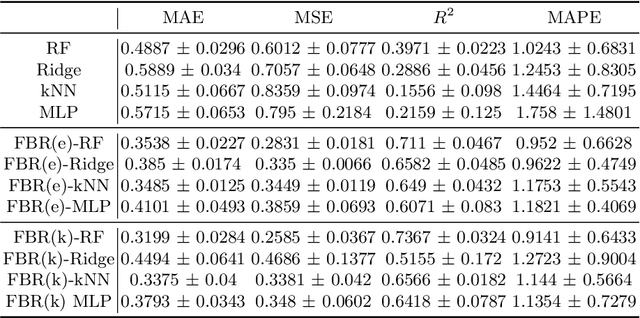
Accurate energy consumption prediction is crucial for optimizing the operation of electric commercial heavy-duty vehicles, e.g., route planning for charging. Moreover, understanding why certain predictions are cast is paramount for such a predictive model to gain user trust and be deployed in practice. Since commercial vehicles operate differently as transportation tasks, ambient, and drivers vary, a heterogeneous population is expected when building an AI system for forecasting energy consumption. The dependencies between the input features and the target values are expected to also differ across sub-populations. One well-known example of such a statistical phenomenon is the Simpson paradox. In this paper, we illustrate that such a setting poses a challenge for existing XAI methods that produce global feature statistics, e.g. LIME or SHAP, causing them to yield misleading results. We demonstrate a potential solution by training multiple regression models on subsets of data. It not only leads to superior regression performance but also more relevant and consistent LIME explanations. Given that the employed groupings correspond to relevant sub-populations, the associations between the input features and the target values are consistent within each cluster but different across clusters. Experiments on both synthetic and real-world datasets show that such splitting of a complex problem into simpler ones yields better regression performance and interpretability.