 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Log-based Anomaly Detection Using Machine Learning
Jul 31, 2023The growth of systems complexity increases the need of automated techniques dedicated to different log analysis tasks such as Log-based Anomaly Detection (LAD). The latter has been widely addressed in the literature, mostly by means of different deep learning techniques. Nevertheless, the focus on deep learning techniques results in less attention being paid to traditional Machine Learning (ML) techniques, which may perform well in many cases, depending on the context and the used datasets. Further, the evaluation of different ML techniques is mostly based on the assessment of their detection accuracy. However, this is is not enough to decide whether or not a specific ML technique is suitable to address the LAD problem. Other aspects to consider include the training and prediction time as well as the sensitivity to hyperparameter tuning. In this paper, we present a comprehensive empirical study, in which we evaluate different supervised and semi-supervised, traditional and deep ML techniques w.r.t. four evaluation criteria: detection accuracy, time performance, sensitivity of detection accuracy as well as time performance to hyperparameter tuning. The experimental results show that supervised traditional and deep ML techniques perform very closely in terms of their detection accuracy and prediction time. Moreover, the overall evaluation of the sensitivity of the detection accuracy of the different ML techniques to hyperparameter tuning shows that supervised traditional ML techniques are less sensitive to hyperparameter tuning than deep learning techniques. Further, semi-supervised techniques yield significantly worse detection accuracy than supervised techniques.
An AI-based Approach for Tracing Content Requirements in Financial Documents
Oct 28, 2021

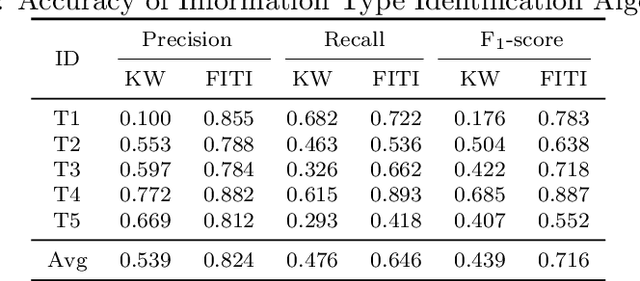
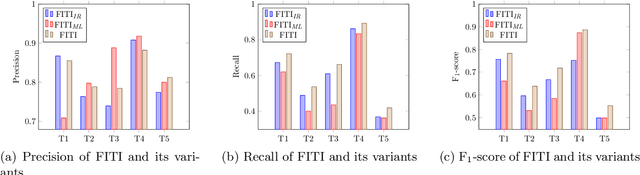
The completeness (in terms of content) of financial documents is a fundamental requirement for investment funds. To ensure completeness, financial regulators spend a huge amount of time for carefully checking every financial document based on the relevant content requirements, which prescribe the information types to be included in financial documents (e.g., the description of shares' issue conditions). Although several techniques have been proposed to automatically detect certain types of information in documents in various application domains, they provide limited support to help regulators automatically identify the text chunks related to financial information types, due to the complexity of financial documents and the diversity of the sentences characterizing an information type. In this paper, we propose FITI, an artificial intelligence (AI)-based method for tracing content requirements in financial documents. Given a new financial document, FITI selects a set of candidate sentences for efficient information type identification. Then, FITI uses a combination of rule-based and data-centric approaches, by leveraging information retrieval (IR) and machine learning (ML) techniques that analyze the words, sentences, and contexts related to an information type, to rank candidate sentences. Finally, using a list of indicator phrases related to each information type, a heuristic-based selector, which considers both the sentence ranking and the domain-specific phrases, determines a list of sentences corresponding to each information type. We evaluated FITI by assessing its effectiveness in tracing financial content requirements in 100 financial documents. Experimental results show that FITI provides accurate identification with average precision and recall values of 0.824 and 0.646, respectively. Furthermore, FITI can detect about 80% of missing information types in financial documents.