Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaba Is AI: Break the Rules to Beat the Benchmark
Jul 18, 2024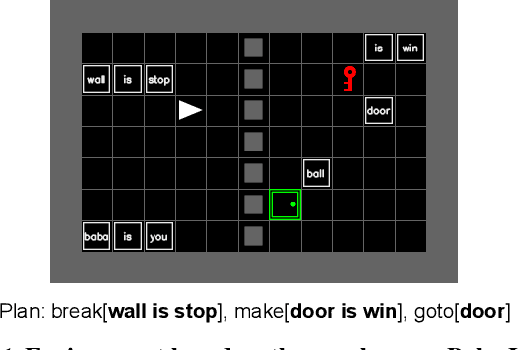

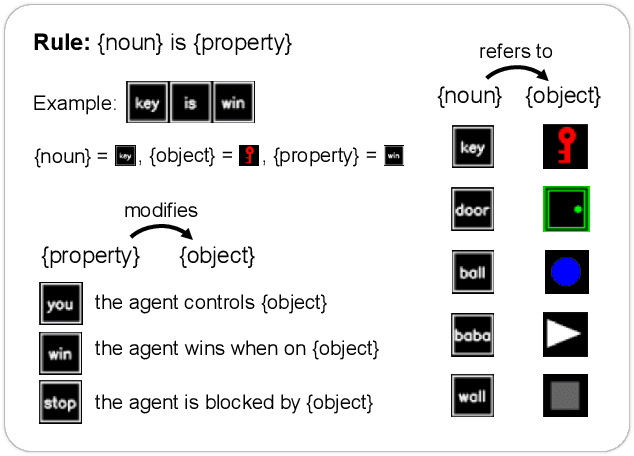
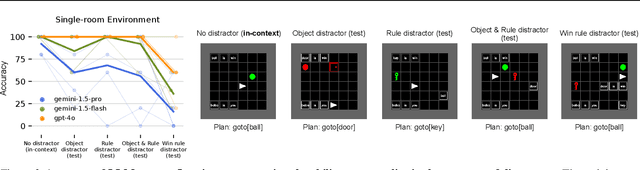
Humans solve problems by following existing rules and procedures, and also by leaps of creativity to redefine those rules and objectives. To probe these abilities, we developed a new benchmark based on the game Baba Is You where an agent manipulates both objects in the environment and rules, represented by movable tiles with words written on them, to reach a specified goal and win the game. We test three state-of-the-art multi-modal large language models (OpenAI GPT-4o, Google Gemini-1.5-Pro and Gemini-1.5-Flash) and find that they fail dramatically when generalization requires that the rules of the game must be manipulated and combined.
* 8 pages, 8 figures
Via