 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Algorithms for Exact Enumeration of Deep Neural Network Activation Regions
Feb 29, 2024



A feedforward neural network using rectified linear units constructs a mapping from inputs to outputs by partitioning its input space into a set of convex regions where points within a region share a single affine transformation. In order to understand how neural networks work, when and why they fail, and how they compare to biological intelligence, we need to understand the organization and formation of these regions. Step one is to design and implement algorithms for exact region enumeration in networks beyond toy examples. In this work, we present parallel algorithms for exact enumeration in deep (and shallow) neural networks. Our work has three main contributions: (1) we present a novel algorithm framework and parallel algorithms for region enumeration; (2) we implement one of our algorithms on a variety of network architectures and experimentally show how the number of regions dictates runtime; and (3) we show, using our algorithm's output, how the dimension of a region's affine transformation impacts further partitioning of the region by deeper layers. To our knowledge, we run our implemented algorithm on networks larger than all of the networks used in the existing region enumeration literature. Further, we experimentally demonstrate the importance of parallelism for region enumeration of any reasonably sized network.
Continual Learning with Self-Organizing Maps
Apr 19, 2019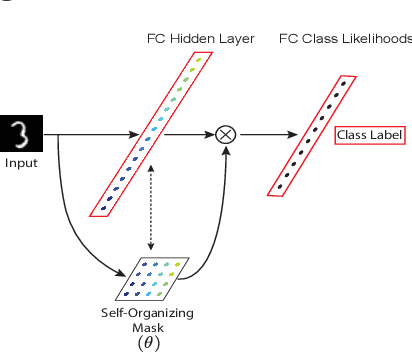
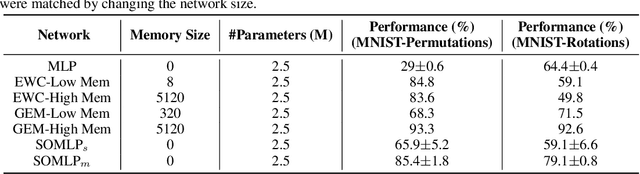
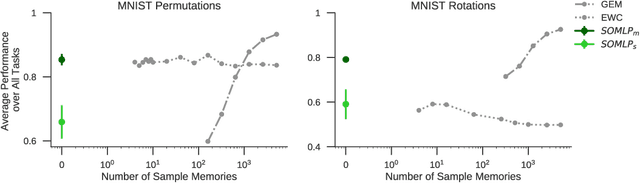

Despite remarkable successes achieved by modern neural networks in a wide range of applications, these networks perform best in domain-specific stationary environments where they are trained only once on large-scale controlled data repositories. When exposed to non-stationary learning environments, current neural networks tend to forget what they had previously learned, a phenomena known as catastrophic forgetting. Most previous approaches to this problem rely on memory replay buffers which store samples from previously learned tasks, and use them to regularize the learning on new ones. This approach suffers from the important disadvantage of not scaling well to real-life problems in which the memory requirements become enormous. We propose a memoryless method that combines standard supervised neural networks with self-organizing maps to solve the continual learning problem. The role of the self-organizing map is to adaptively cluster the inputs into appropriate task contexts - without explicit labels - and allocate network resources accordingly. Thus, it selectively routes the inputs in accord with previous experience, ensuring that past learning is maintained and does not interfere with current learning. Out method is intuitive, memoryless, and performs on par with current state-of-the-art approaches on standard benchmarks.
Learning to Learn without Forgetting By Maximizing Transfer and Minimizing Interference
Oct 29, 2018
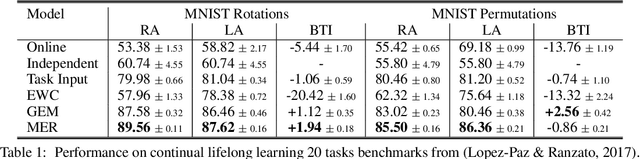
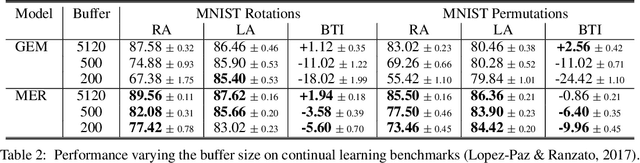

Lack of performance when it comes to continual learning over non-stationary distributions of data remains a major challenge in scaling neural network learning to more human realistic settings. In this work we propose a new conceptualization of the continual learning problem in terms of a trade-off between transfer and interference. We then propose a new algorithm, Meta-Experience Replay (MER), that directly exploits this view by combining experience replay with optimization based meta-learning. This method learns parameters that make interference based on future gradients less likely and transfer based on future gradients more likely. We conduct experiments across continual lifelong supervised learning benchmarks and non-stationary reinforcement learning environments demonstrating that our approach consistently outperforms recently proposed baselines for continual learning. Our experiments show that the gap between the performance of MER and baseline algorithms grows both as the environment gets more non-stationary and as the fraction of the total experiences stored gets smaller.