 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGistScore: Learning Better Representations for In-Context Example Selection with Gist Bottlenecks
Nov 16, 2023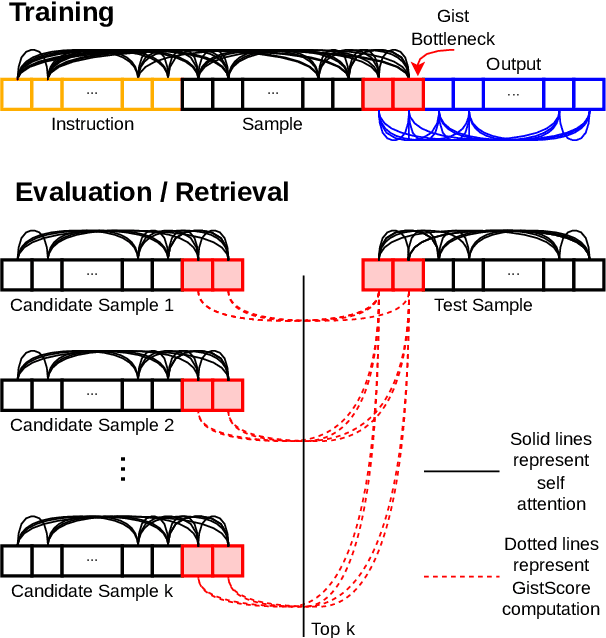
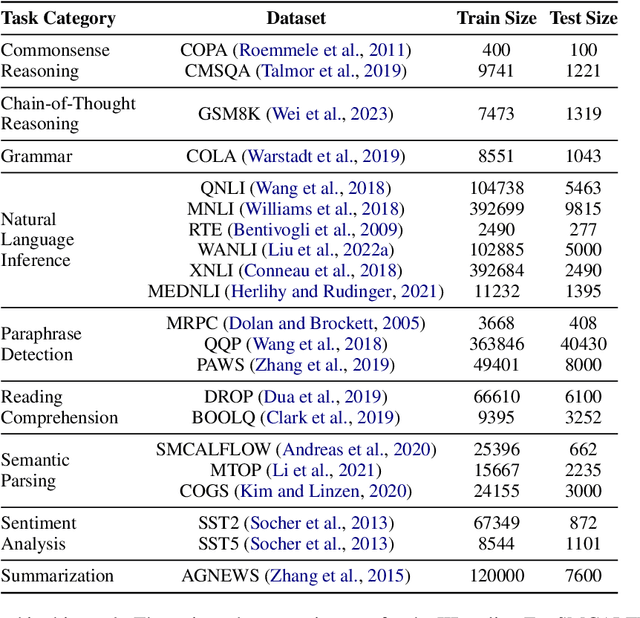
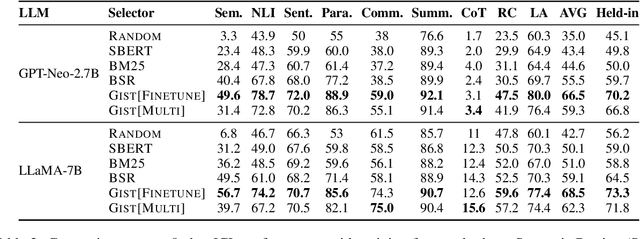
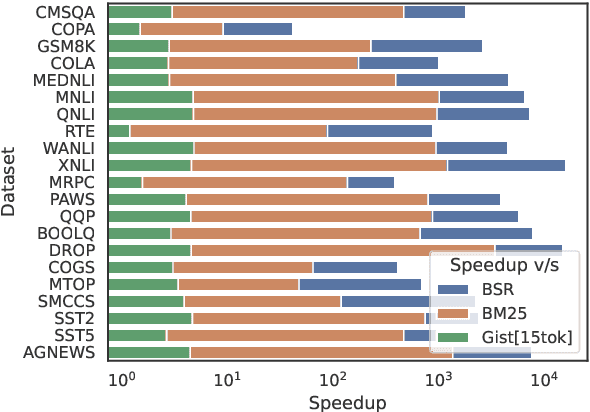
Large language models (LLMs) have the ability to perform in-context learning (ICL) of new tasks by conditioning on prompts comprising a few task examples. This work studies the problem of selecting the best examples given a candidate pool to improve ICL performance on given a test input. Existing approaches either require training with feedback from a much larger LLM or are computationally expensive. We propose a novel metric, GistScore, based on Example Gisting, a novel approach for training example retrievers for ICL using an attention bottleneck via Gisting, a recent technique for compressing task instructions. To tradeoff performance with ease of use, we experiment with both fine-tuning gist models on each dataset and multi-task training a single model on a large collection of datasets. On 21 diverse datasets spanning 9 tasks, we show that our fine-tuned models get state-of-the-art ICL performance with 20% absolute average gain over off-the-shelf retrievers and 7% over the best prior methods. Our multi-task model generalizes well out-of-the-box to new task categories, datasets, and prompt templates with retrieval speeds that are consistently thousands of times faster than the best prior training-free method.
CEREAL: Few-Sample Clustering Evaluation
Sep 30, 2022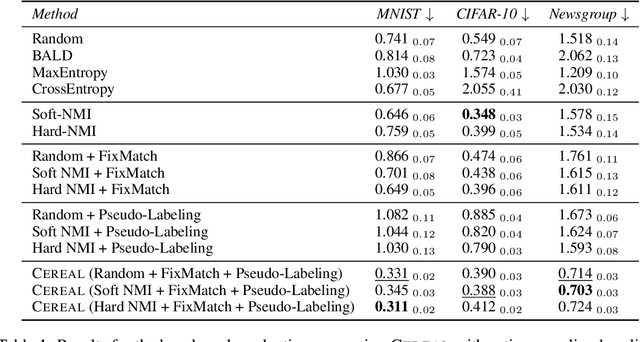



Evaluating clustering quality with reliable evaluation metrics like normalized mutual information (NMI) requires labeled data that can be expensive to annotate. We focus on the underexplored problem of estimating clustering quality with limited labels. We adapt existing approaches from the few-sample model evaluation literature to actively sub-sample, with a learned surrogate model, the most informative data points for annotation to estimate the evaluation metric. However, we find that their estimation can be biased and only relies on the labeled data. To that end, we introduce CEREAL, a comprehensive framework for few-sample clustering evaluation that extends active sampling approaches in three key ways. First, we propose novel NMI-based acquisition functions that account for the distinctive properties of clustering and uncertainties from a learned surrogate model. Next, we use ideas from semi-supervised learning and train the surrogate model with both the labeled and unlabeled data. Finally, we pseudo-label the unlabeled data with the surrogate model. We run experiments to estimate NMI in an active sampling pipeline on three datasets across vision and language. Our results show that CEREAL reduces the area under the absolute error curve by up to 57% compared to the best sampling baseline. We perform an extensive ablation study to show that our framework is agnostic to the choice of clustering algorithm and evaluation metric. We also extend CEREAL from clusterwise annotations to pairwise annotations. Overall, CEREAL can efficiently evaluate clustering with limited human annotations.
On the Role of Weight Sharing During Deep Option Learning
Feb 06, 2020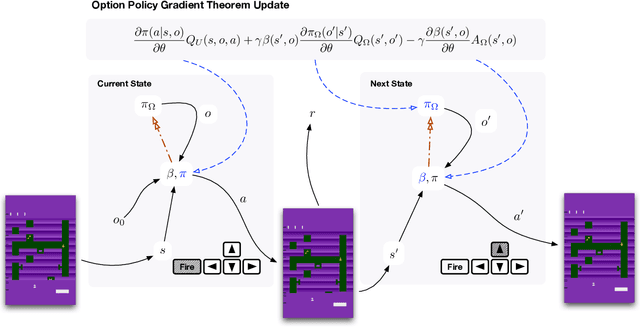
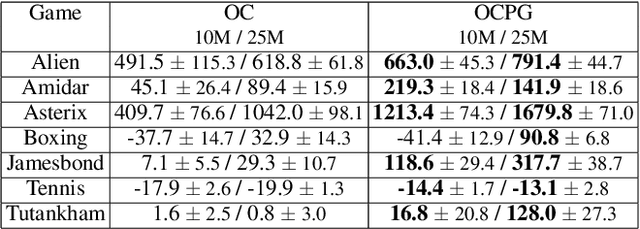


The options framework is a popular approach for building temporally extended actions in reinforcement learning. In particular, the option-critic architecture provides general purpose policy gradient theorems for learning actions from scratch that are extended in time. However, past work makes the key assumption that each of the components of option-critic has independent parameters. In this work we note that while this key assumption of the policy gradient theorems of option-critic holds in the tabular case, it is always violated in practice for the deep function approximation setting. We thus reconsider this assumption and consider more general extensions of option-critic and hierarchical option-critic training that optimize for the full architecture with each update. It turns out that not assuming parameter independence challenges a belief in prior work that training the policy over options can be disentangled from the dynamics of the underlying options. In fact, learning can be sped up by focusing the policy over options on states where options are actually likely to terminate. We put our new algorithms to the test in application to sample efficient learning of Atari games, and demonstrate significantly improved stability and faster convergence when learning long options.
Routing Networks and the Challenges of Modular and Compositional Computation
Apr 29, 2019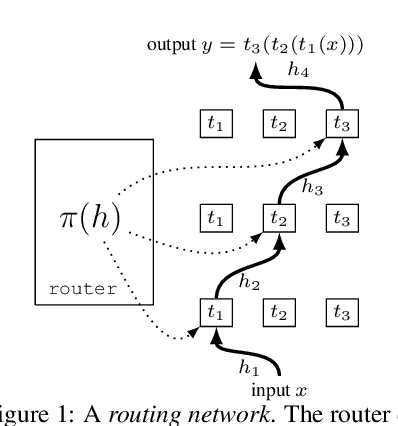
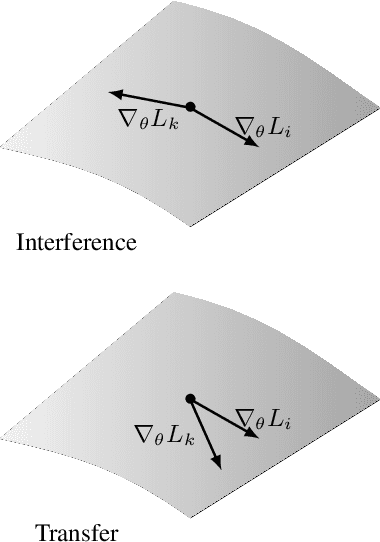
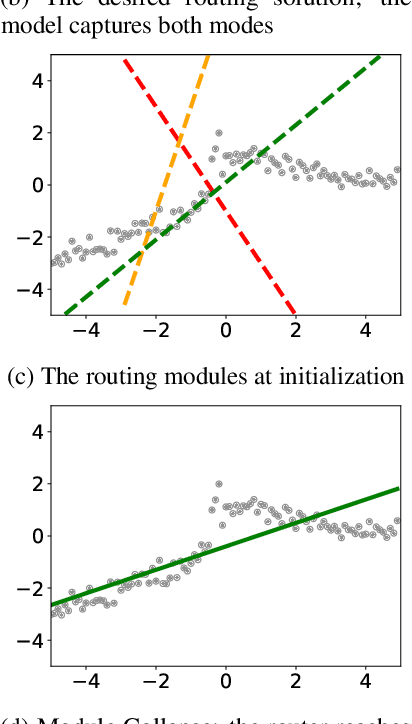
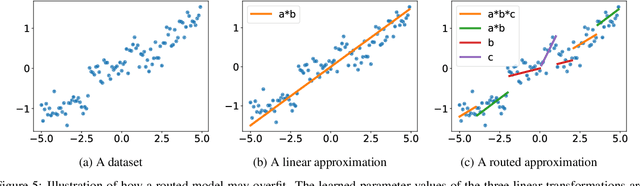
Compositionality is a key strategy for addressing combinatorial complexity and the curse of dimensionality. Recent work has shown that compositional solutions can be learned and offer substantial gains across a variety of domains, including multi-task learning, language modeling, visual question answering, machine comprehension, and others. However, such models present unique challenges during training when both the module parameters and their composition must be learned jointly. In this paper, we identify several of these issues and analyze their underlying causes. Our discussion focuses on routing networks, a general approach to this problem, and examines empirically the interplay of these challenges and a variety of design decisions. In particular, we consider the effect of how the algorithm decides on module composition, how the algorithm updates the modules, and if the algorithm uses regularization.
Eigenoption Discovery through the Deep Successor Representation
Feb 23, 2018
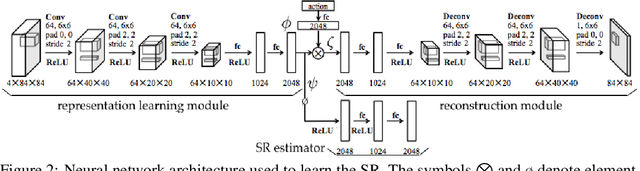


Options in reinforcement learning allow agents to hierarchically decompose a task into subtasks, having the potential to speed up learning and planning. However, autonomously learning effective sets of options is still a major challenge in the field. In this paper we focus on the recently introduced idea of using representation learning methods to guide the option discovery process. Specifically, we look at eigenoptions, options obtained from representations that encode diffusive information flow in the environment. We extend the existing algorithms for eigenoption discovery to settings with stochastic transitions and in which handcrafted features are not available. We propose an algorithm that discovers eigenoptions while learning non-linear state representations from raw pixels. It exploits recent successes in the deep reinforcement learning literature and the equivalence between proto-value functions and the successor representation. We use traditional tabular domains to provide intuition about our approach and Atari 2600 games to demonstrate its potential.
Routing Networks: Adaptive Selection of Non-linear Functions for Multi-Task Learning
Dec 31, 2017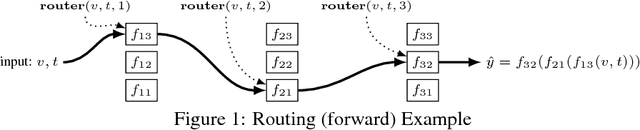

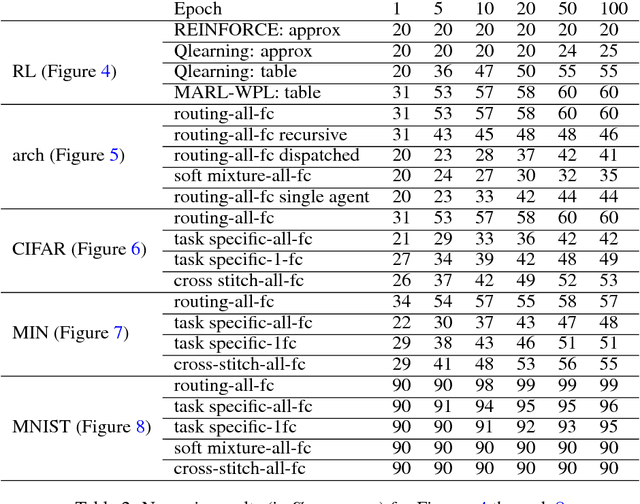
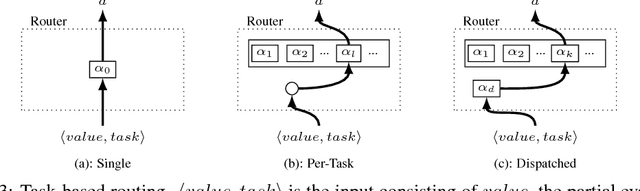
Multi-task learning (MTL) with neural networks leverages commonalities in tasks to improve performance, but often suffers from task interference which reduces the benefits of transfer. To address this issue we introduce the routing network paradigm, a novel neural network and training algorithm. A routing network is a kind of self-organizing neural network consisting of two components: a router and a set of one or more function blocks. A function block may be any neural network - for example a fully-connected or a convolutional layer. Given an input the router makes a routing decision, choosing a function block to apply and passing the output back to the router recursively, terminating when a fixed recursion depth is reached. In this way the routing network dynamically composes different function blocks for each input. We employ a collaborative multi-agent reinforcement learning (MARL) approach to jointly train the router and function blocks. We evaluate our model against cross-stitch networks and shared-layer baselines on multi-task settings of the MNIST, mini-imagenet, and CIFAR-100 datasets. Our experiments demonstrate a significant improvement in accuracy, with sharper convergence. In addition, routing networks have nearly constant per-task training cost while cross-stitch networks scale linearly with the number of tasks. On CIFAR-100 (20 tasks) we obtain cross-stitch performance levels with an 85% reduction in training time.
e-QRAQ: A Multi-turn Reasoning Dataset and Simulator with Explanations
Aug 05, 2017
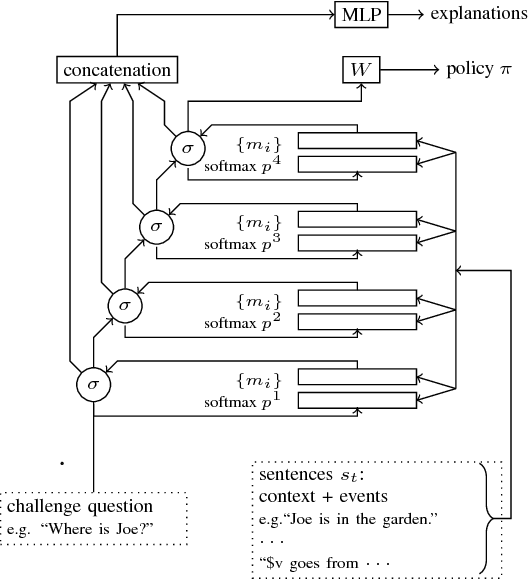
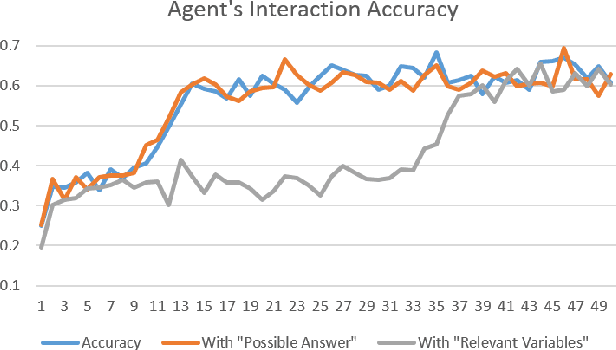
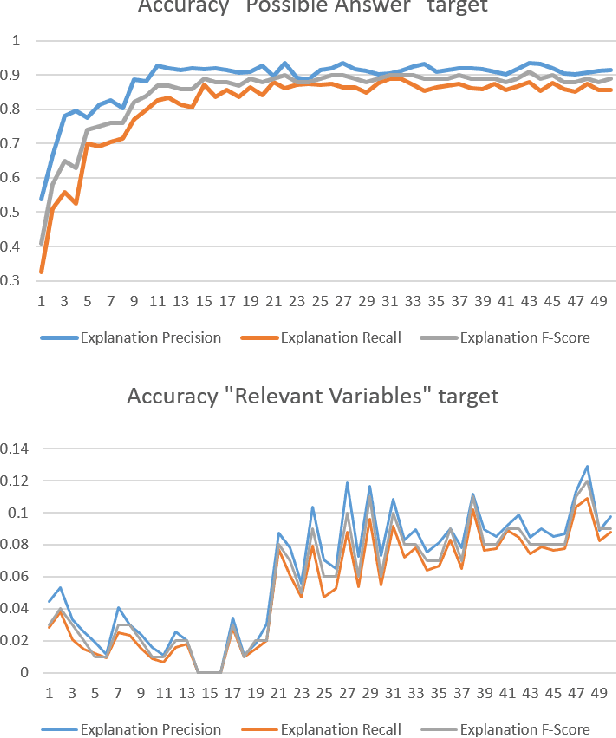
In this paper we present a new dataset and user simulator e-QRAQ (explainable Query, Reason, and Answer Question) which tests an Agent's ability to read an ambiguous text; ask questions until it can answer a challenge question; and explain the reasoning behind its questions and answer. The User simulator provides the Agent with a short, ambiguous story and a challenge question about the story. The story is ambiguous because some of the entities have been replaced by variables. At each turn the Agent may ask for the value of a variable or try to answer the challenge question. In response the User simulator provides a natural language explanation of why the Agent's query or answer was useful in narrowing down the set of possible answers, or not. To demonstrate one potential application of the e-QRAQ dataset, we train a new neural architecture based on End-to-End Memory Networks to successfully generate both predictions and partial explanations of its current understanding of the problem. We observe a strong correlation between the quality of the prediction and explanation.
Deep Reinforcement Learning With Macro-Actions
Jun 15, 2016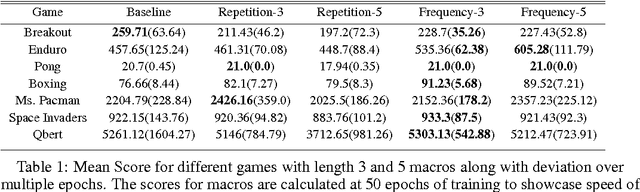
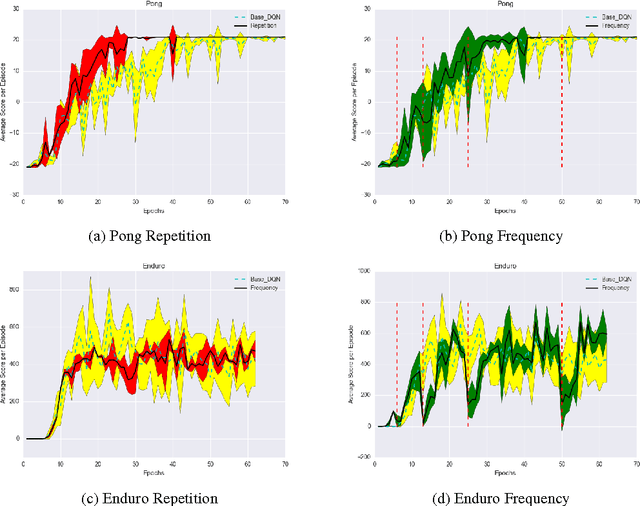
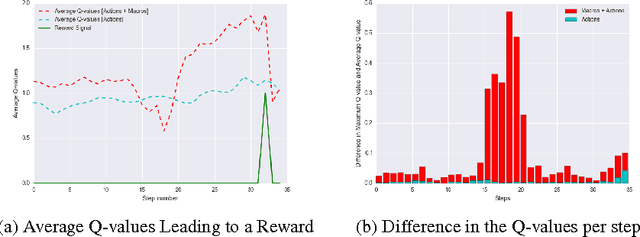
Deep reinforcement learning has been shown to be a powerful framework for learning policies from complex high-dimensional sensory inputs to actions in complex tasks, such as the Atari domain. In this paper, we explore output representation modeling in the form of temporal abstraction to improve convergence and reliability of deep reinforcement learning approaches. We concentrate on macro-actions, and evaluate these on different Atari 2600 games, where we show that they yield significant improvements in learning speed. Additionally, we show that they can even achieve better scores than DQN. We offer analysis and explanation for both convergence and final results, revealing a problem deep RL approaches have with sparse reward signals.