 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Fast and Laterally: Multi-Agentic Approach for Reasoning about Uncertain Emerging Events
Dec 10, 2024This paper introduces lateral thinking to implement System-2 reasoning capabilities in AI systems, focusing on anticipatory and causal reasoning under uncertainty. We present a framework for systematic generation and modeling of lateral thinking queries and evaluation datasets. We introduce Streaming Agentic Lateral Thinking (SALT), a multi-agent framework designed to process complex, low-specificity queries in streaming data environments. SALT implements lateral thinking-inspired System-2 reasoning through a dynamic communication structure between specialized agents. Our key insight is that lateral information flow across long-distance agent interactions, combined with fine-grained belief management, yields richer information contexts and enhanced reasoning. Preliminary quantitative and qualitative evaluations indicate SALT's potential to outperform single-agent systems in handling complex lateral reasoning tasks in a streaming environment.
GLaM: Fine-Tuning Large Language Models for Domain Knowledge Graph Alignment via Neighborhood Partitioning and Generative Subgraph Encoding
Feb 16, 2024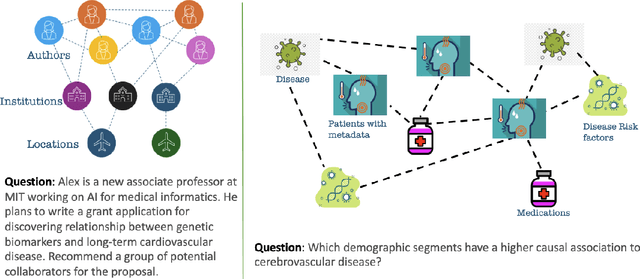
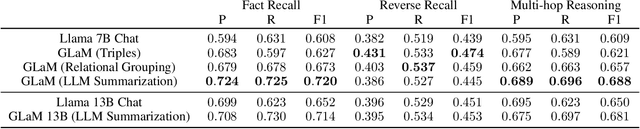
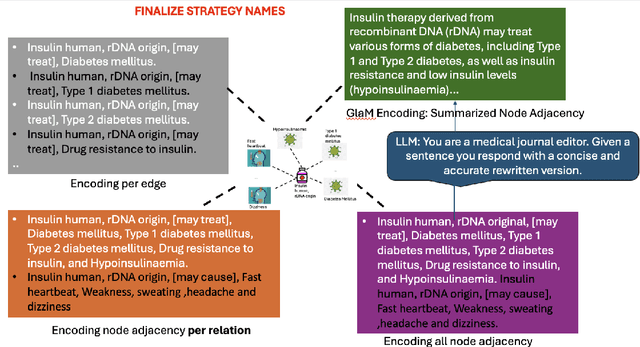
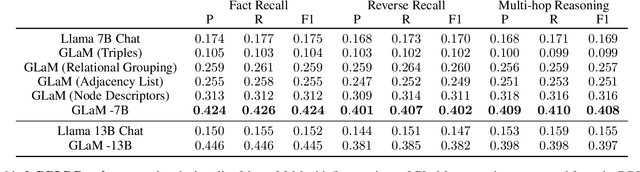
Integrating large language models (LLMs) with knowledge graphs derived from domain-specific data represents an important advancement towards more powerful and factual reasoning. As these models grow more capable, it is crucial to enable them to perform multi-step inferences over real-world knowledge graphs while minimizing hallucination. While large language models excel at conversation and text generation, their ability to reason over domain-specialized graphs of interconnected entities remains limited. For example, can we query a LLM to identify the optimal contact in a professional network for a specific goal, based on relationships and attributes in a private database? The answer is no--such capabilities lie beyond current methods. However, this question underscores a critical technical gap that must be addressed. Many high-value applications in areas such as science, security, and e-commerce rely on proprietary knowledge graphs encoding unique structures, relationships, and logical constraints. We introduce a fine-tuning framework for developing Graph-aligned LAnguage Models (GLaM) that transforms a knowledge graph into an alternate text representation with labeled question-answer pairs. We demonstrate that grounding the models in specific graph-based knowledge expands the models' capacity for structure-based reasoning. Our methodology leverages the large-language model's generative capabilities to create the dataset and proposes an efficient alternate to retrieval-augmented generation styled methods.
Filtered Manifold Alignment
Nov 11, 2020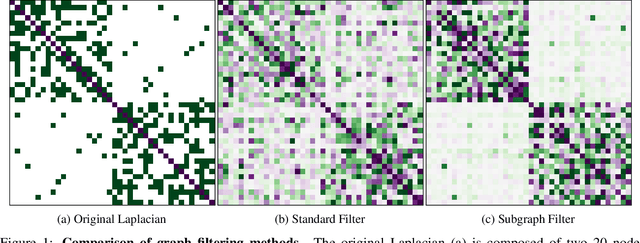
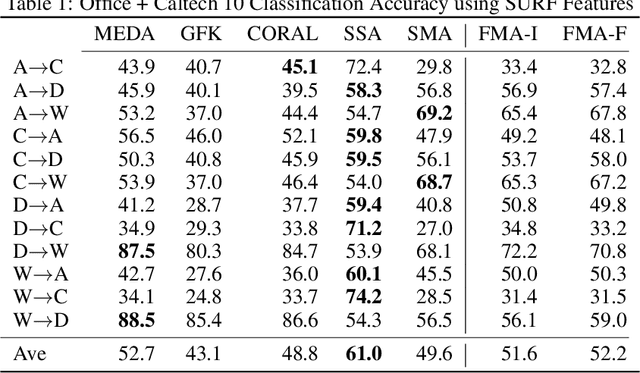
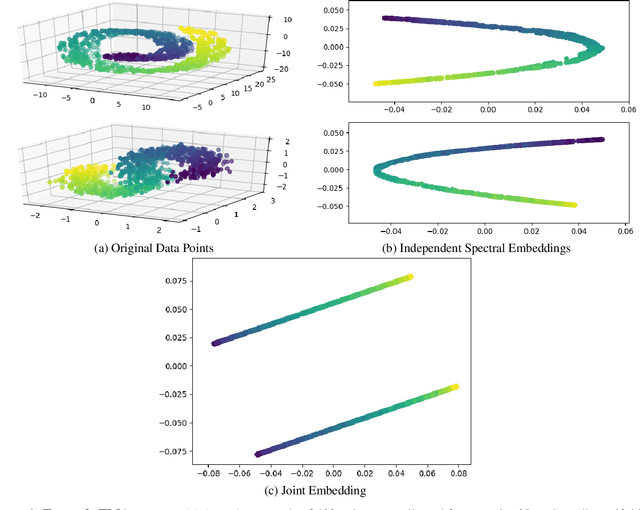

Domain adaptation is an essential task in transfer learning to leverage data in one domain to bolster learning in another domain. In this paper, we present a new semi-supervised manifold alignment technique based on a two-step approach of projecting and filtering the source and target domains to low dimensional spaces followed by joining the two spaces. Our proposed approach, filtered manifold alignment (FMA), reduces the computational complexity of previous manifold alignment techniques, is flexible enough to align domains with completely disparate sets of feature and demonstrates state-of-the-art classification accuracy on multiple benchmark domain adaptation tasks composed of classifying real world image datasets.
Deep Reinforcement Learning With Macro-Actions
Jun 15, 2016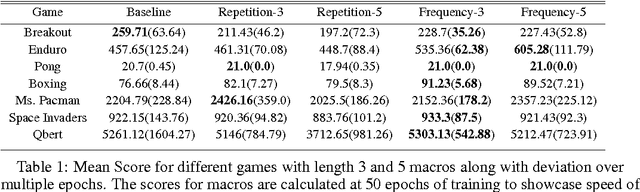
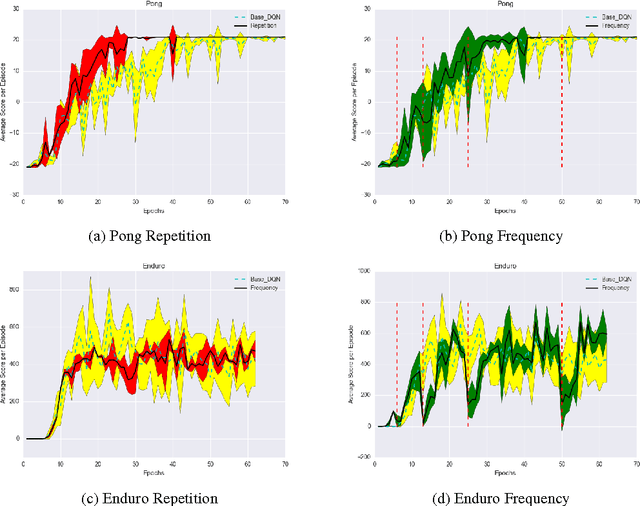
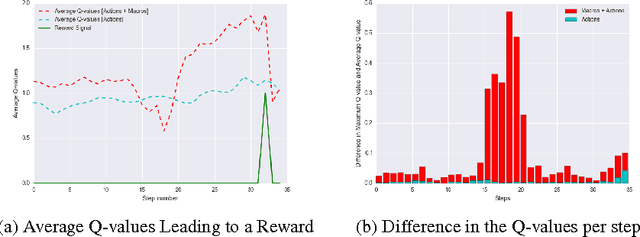
Deep reinforcement learning has been shown to be a powerful framework for learning policies from complex high-dimensional sensory inputs to actions in complex tasks, such as the Atari domain. In this paper, we explore output representation modeling in the form of temporal abstraction to improve convergence and reliability of deep reinforcement learning approaches. We concentrate on macro-actions, and evaluate these on different Atari 2600 games, where we show that they yield significant improvements in learning speed. Additionally, we show that they can even achieve better scores than DQN. We offer analysis and explanation for both convergence and final results, revealing a problem deep RL approaches have with sparse reward signals.