Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning With Macro-Actions
Paper and Code
Jun 15, 2016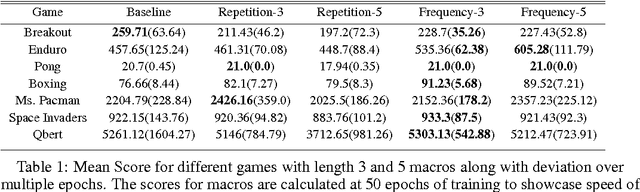
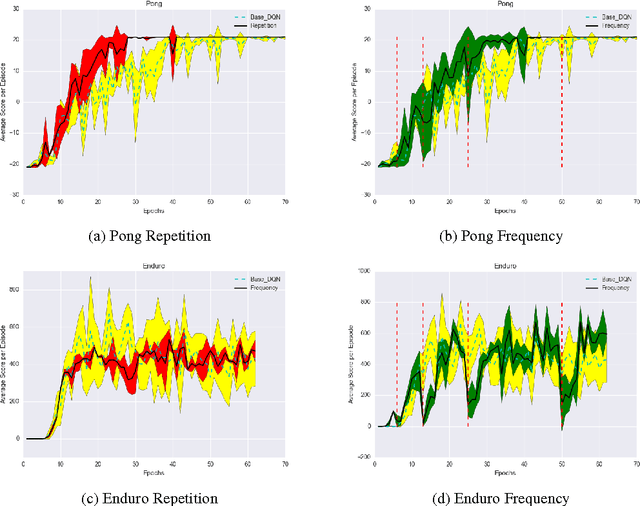
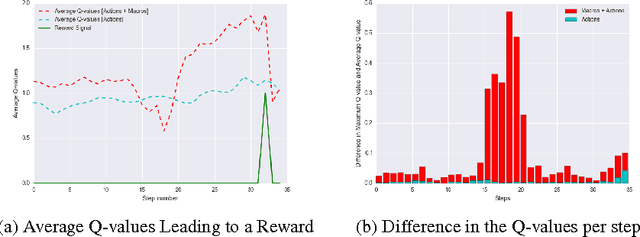
Deep reinforcement learning has been shown to be a powerful framework for learning policies from complex high-dimensional sensory inputs to actions in complex tasks, such as the Atari domain. In this paper, we explore output representation modeling in the form of temporal abstraction to improve convergence and reliability of deep reinforcement learning approaches. We concentrate on macro-actions, and evaluate these on different Atari 2600 games, where we show that they yield significant improvements in learning speed. Additionally, we show that they can even achieve better scores than DQN. We offer analysis and explanation for both convergence and final results, revealing a problem deep RL approaches have with sparse reward signals.
View paper on