 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosing Fair Generalization Tasks for Natural Language Inference
Paper and Code
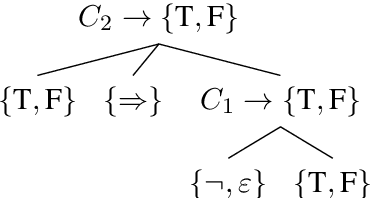
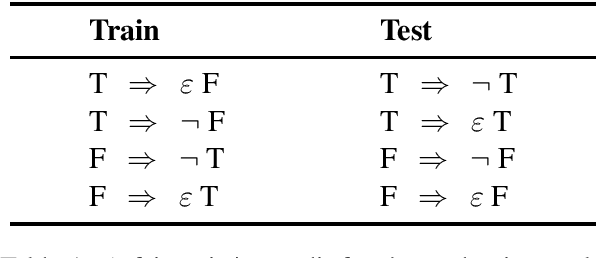

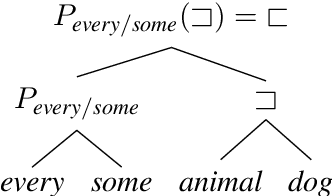
Deep learning models for semantics are generally evaluated using naturalistic corpora. Adversarial methods, in which models are evaluated on new examples with known semantic properties, have begun to reveal that good performance at these naturalistic tasks can hide serious shortcomings. However, we should insist that these evaluations be fair -that the models are given data sufficient to support the requisite kinds of generalization. In this paper, we define and motivate a formal notion of fairness in this sense. We then apply these ideas to natural language inference by constructing very challenging but provably fair artificial datasets and showing that standard neural models fail to generalize in the required ways; only task-specific models that jointly compose the premise and hypothesis are able to achieve high performance, and even these models do not solve the task perfectly.