 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for weighted multi-tape automata
Jun 02, 2004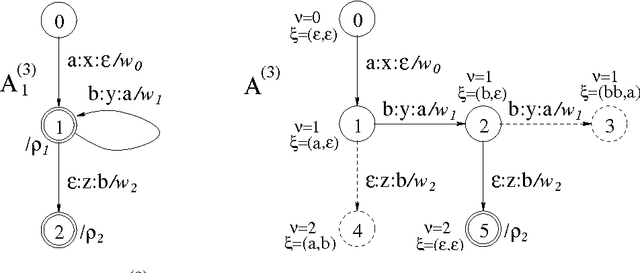
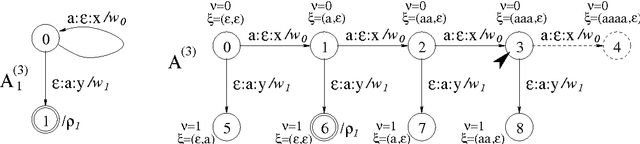
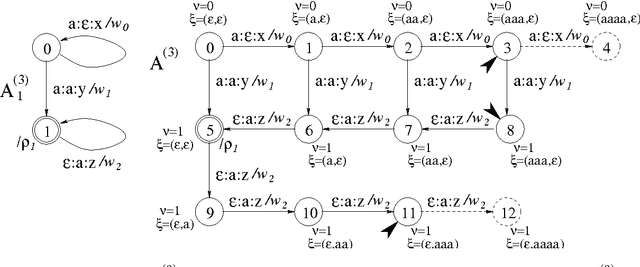
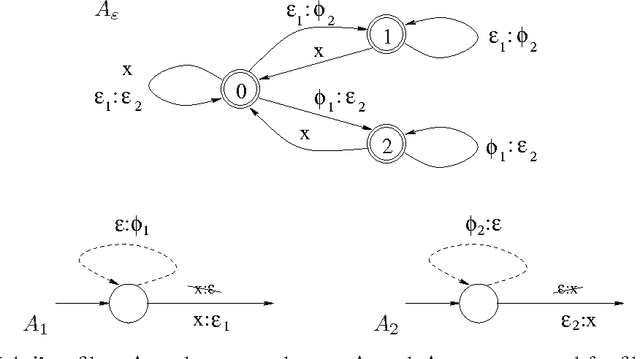
This report defines various operations for weighted multi-tape automata (WMTAs) and describes algorithms that have been implemented for those operations in the WFSC toolkit. Some algorithms are new, others are known or similar to known algorithms. The latter will be recalled to make this report more complete and self-standing. We present a new approach to multi-tape intersection, meaning the intersection of a number of tapes of one WMTA with the same number of tapes of another WMTA. In our approach, multi-tape intersection is not considered as an atomic operation but rather as a sequence of more elementary ones, which facilitates its implementation. We show an example of multi-tape intersection, actually transducer intersection, that can be compiled with our approach but not with several other methods that we analysed. To show the practical relavance of our work, we include an example of application: the preservation of intermediate results in transduction cascades.
Part-of-Speech Tagging with Two Sequential Transducers
Oct 11, 2001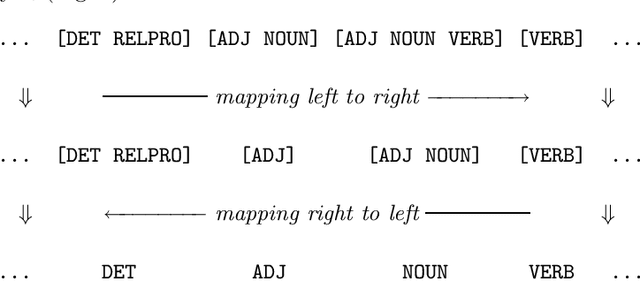


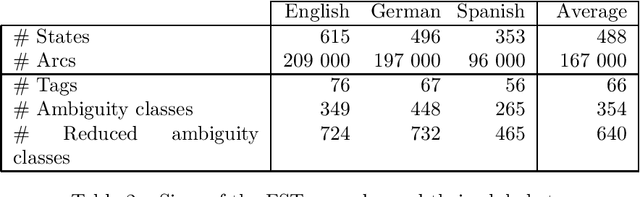
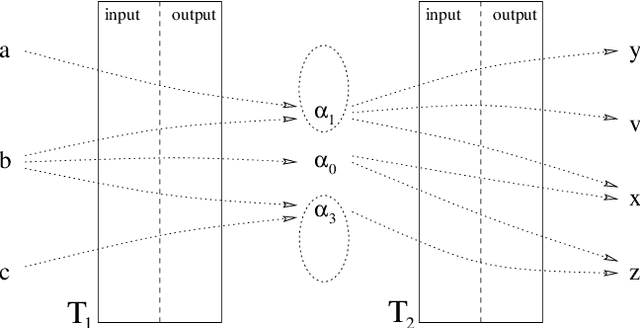
We present a method of constructing and using a cascade consisting of a left- and a right-sequential finite-state transducer (FST), T1 and T2, for part-of-speech (POS) disambiguation. Compared to an HMM, this FST cascade has the advantage of significantly higher processing speed, but at the cost of slightly lower accuracy. Applications such as Information Retrieval, where the speed can be more important than accuracy, could benefit from this approach. In the process of tagging, we first assign every word a unique ambiguity class c_i that can be looked up in a lexicon encoded by a sequential FST. Every c_i is denoted by a single symbol, e.g. [ADJ_NOUN], although it represents a set of alternative tags that a given word can occur with. The sequence of the c_i of all words of one sentence is the input to our FST cascade. It is mapped by T1, from left to right, to a sequence of reduced ambiguity classes r_i. Every r_i is denoted by a single symbol, although it represents a set of alternative tags. Intuitively, T1 eliminates the less likely tags from c_i, thus creating r_i. Finally, T2 maps the sequence of r_i, from right to left, to a sequence of single POS tags t_i. Intuitively, T2 selects the most likely t_i from every r_i. The probabilities of all t_i, r_i, and c_i are used only at compile time, not at run time. They do not (directly) occur in the FSTs, but are "implicitly contained" in their structure.
* 7 pages, 4 figures, LaTeX (+ eps)
Reduction of Intermediate Alphabets in Finite-State Transducer Cascades
Oct 23, 2000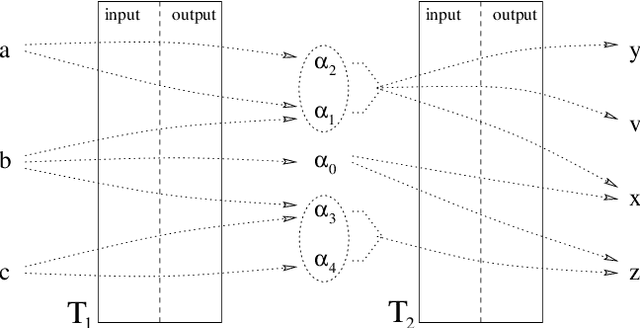
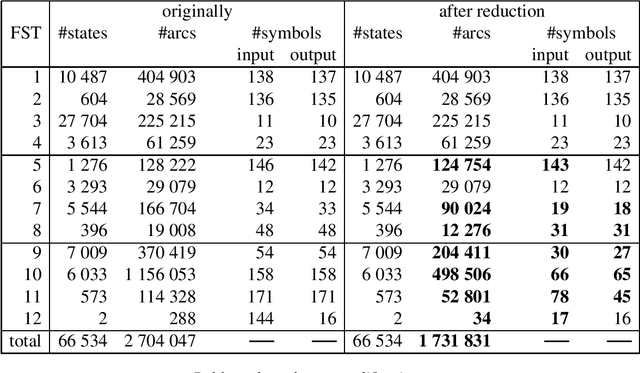
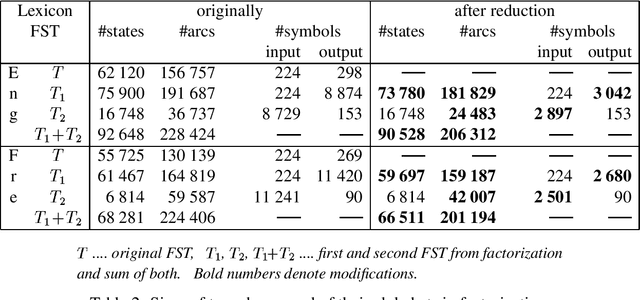
This article describes an algorithm for reducing the intermediate alphabets in cascades of finite-state transducers (FSTs). Although the method modifies the component FSTs, there is no change in the overall relation described by the whole cascade. No additional information or special algorithm, that could decelerate the processing of input, is required at runtime. Two examples from Natural Language Processing are used to illustrate the effect of the algorithm on the sizes of the FSTs and their alphabets. With some FSTs the number of arcs and symbols shrank considerably.
* 9 pages, 7 figures, LaTeX (+ eps)
Look-Back and Look-Ahead in the Conversion of Hidden Markov Models into Finite State Transducers
Feb 02, 1998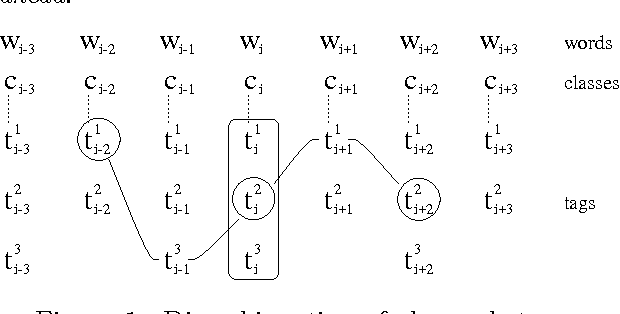
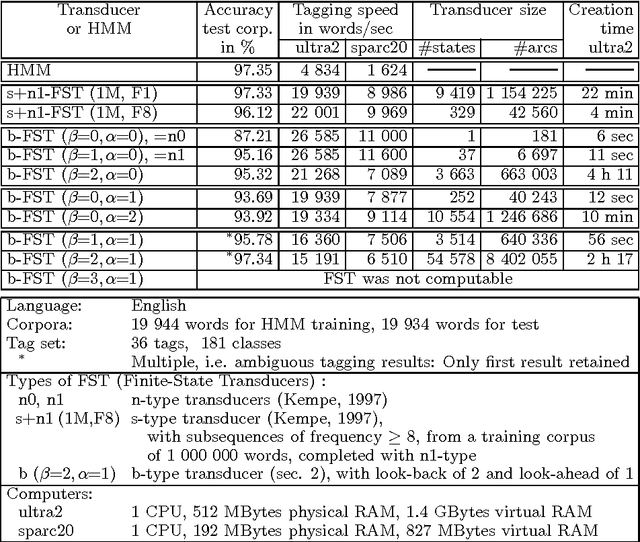
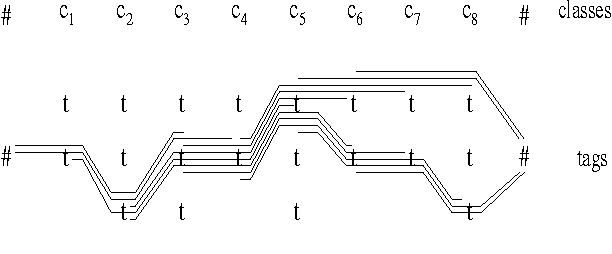
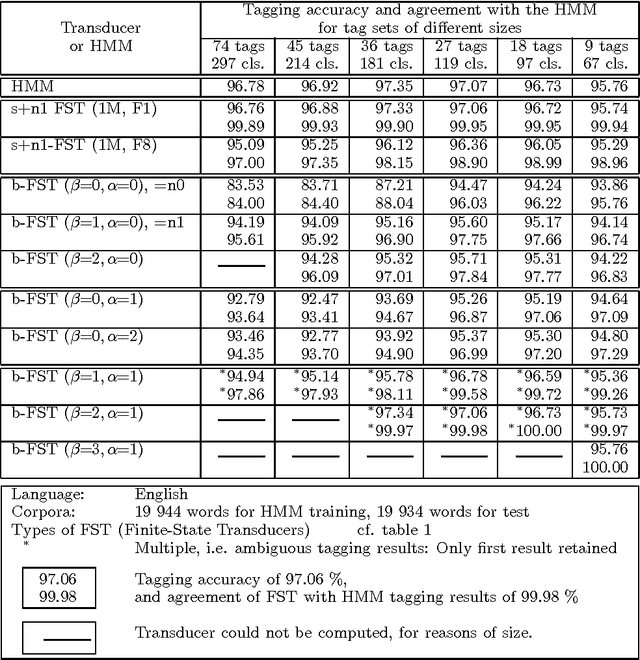
This paper describes the conversion of a Hidden Markov Model into a finite state transducer that closely approximates the behavior of the stochastic model. In some cases the transducer is equivalent to the HMM. This conversion is especially advantageous for part-of-speech tagging because the resulting transducer can be composed with other transducers that encode correction rules for the most frequent tagging errors. The speed of tagging is also improved. The described methods have been implemented and successfully tested.
* 9 pages, A4, LaTeX (+4x eps) gzip tar gzip uuencode
Finite State Transducers Approximating Hidden Markov Models
Jul 17, 1997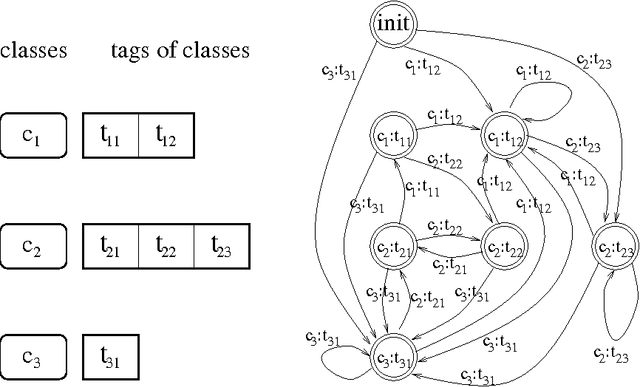
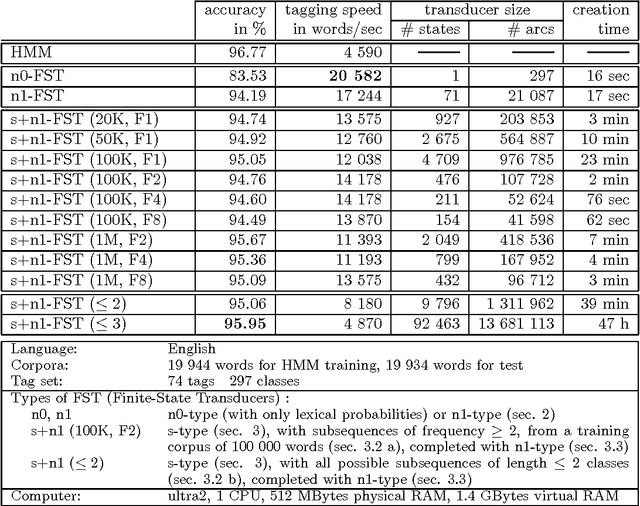

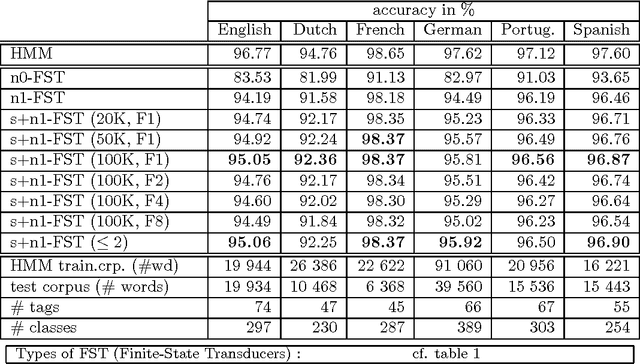
This paper describes the conversion of a Hidden Markov Model into a sequential transducer that closely approximates the behavior of the stochastic model. This transformation is especially advantageous for part-of-speech tagging because the resulting transducer can be composed with other transducers that encode correction rules for the most frequent tagging errors. The speed of tagging is also improved. The described methods have been implemented and successfully tested on six languages.
* 8 pages, A4, LaTeX (+1x eps)
Parallel Replacement in Finite State Calculus
Aug 12, 1996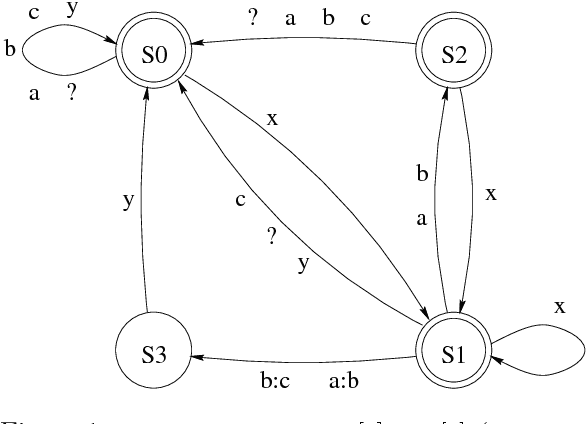
This paper extends the calculus of regular expressions with new types of replacement expressions that enhance the expressiveness of the simple replace operator defined in Karttunen (1995). Parallel replacement allows multiple replacements to apply simultaneously to the same input without interfering with each other. We also allow a replacement to be constrained by any number of alternative contexts. With these enhancements, the general replacement expressions are more versatile than two-level rules for the description of complex morphological alternations.
* 6 pages, dvi (+ 1x eps) tar gzip uuencode
Probabilistic Tagging with Feature Structures
Oct 25, 1994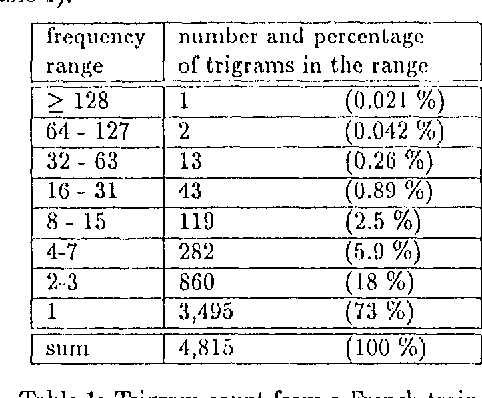
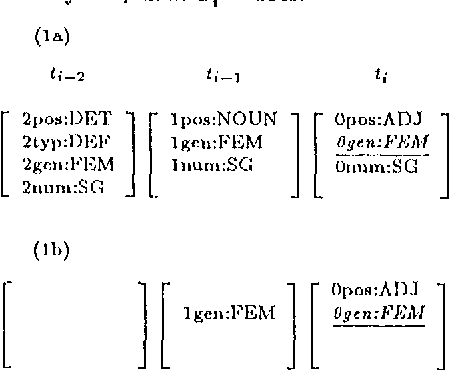
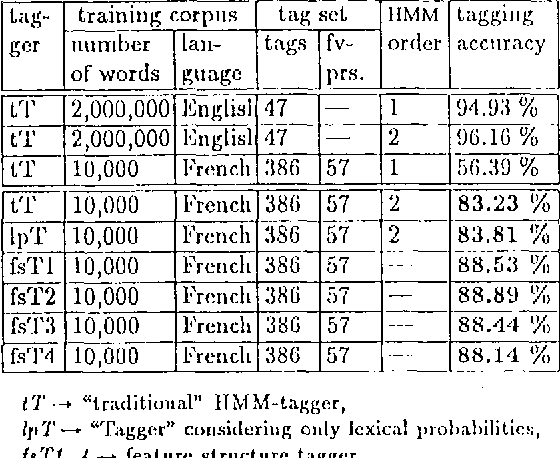
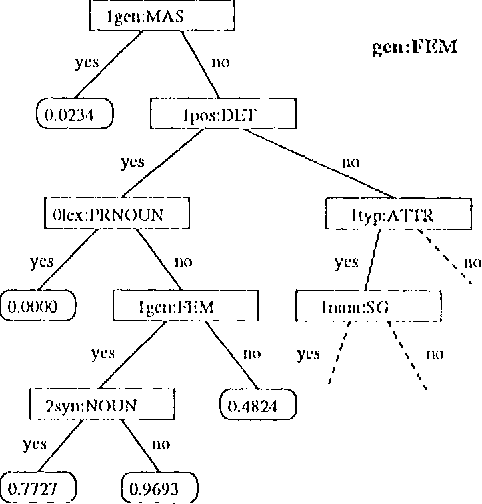
The described tagger is based on a hidden Markov model and uses tags composed of features such as part-of-speech, gender, etc. The contextual probability of a tag (state transition probability) is deduced from the contextual probabilities of its feature-value-pairs. This approach is advantageous when the available training corpus is small and the tag set large, which can be the case with morphologically rich languages.
* Coling-94, 85 KB, 5 pages