Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Tagging with Feature Structures
Paper and Code
Oct 25, 1994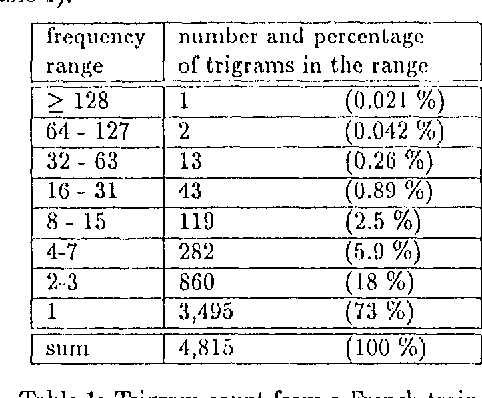
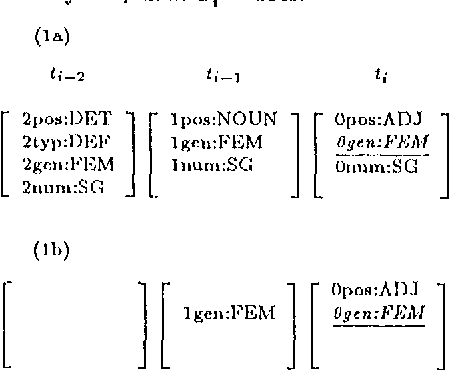
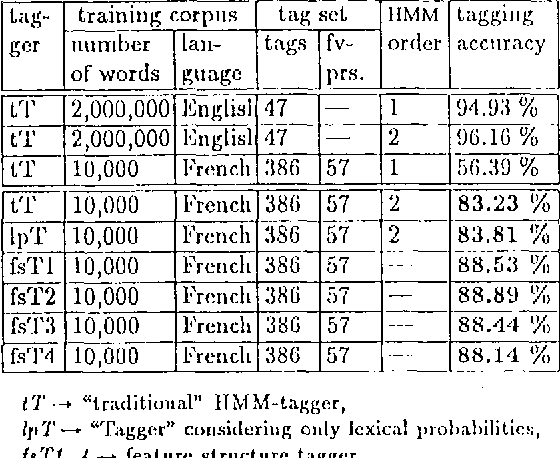
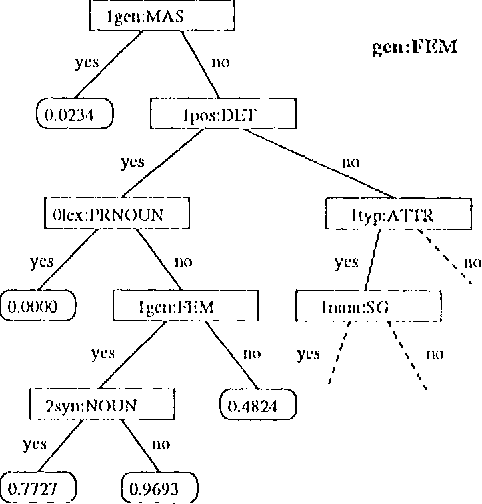
The described tagger is based on a hidden Markov model and uses tags composed of features such as part-of-speech, gender, etc. The contextual probability of a tag (state transition probability) is deduced from the contextual probabilities of its feature-value-pairs. This approach is advantageous when the available training corpus is small and the tag set large, which can be the case with morphologically rich languages.
* COLING-94, vol.1, pp.161-165, Kyoto, Japan. August 5-9, 1994. * Coling-94, 85 KB, 5 pages
View paper on