 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Distillation for Language Models
Dec 05, 2021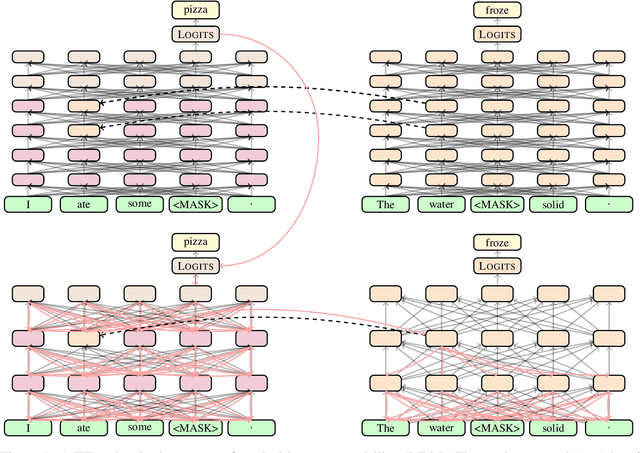

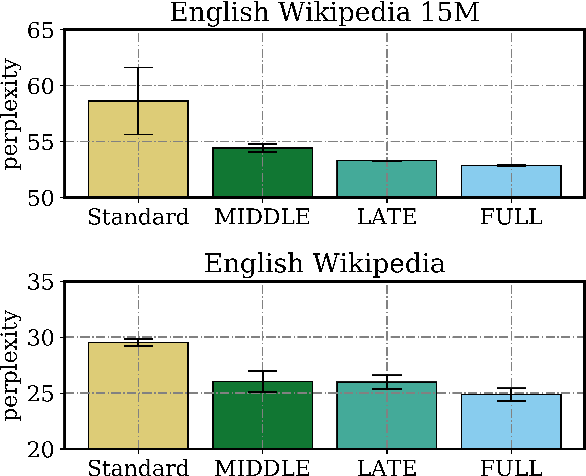
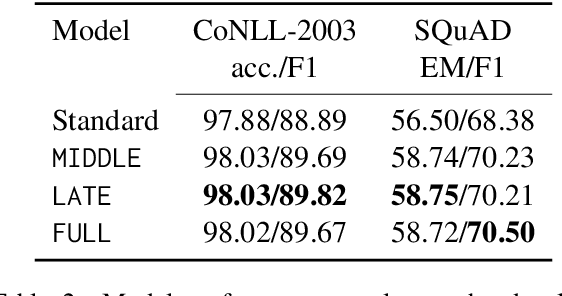
Distillation efforts have led to language models that are more compact and efficient without serious drops in performance. The standard approach to distillation trains a student model against two objectives: a task-specific objective (e.g., language modeling) and an imitation objective that encourages the hidden states of the student model to be similar to those of the larger teacher model. In this paper, we show that it is beneficial to augment distillation with a third objective that encourages the student to imitate the causal computation process of the teacher through interchange intervention training(IIT). IIT pushes the student model to become a causal abstraction of the teacher model - a simpler model with the same causal structure. IIT is fully differentiable, easily implemented, and combines flexibly with other objectives. Compared with standard distillation of BERT, distillation via IIT results in lower perplexity on Wikipedia (masked language modeling) and marked improvements on the GLUE benchmark (natural language understanding), SQuAD (question answering), and CoNLL-2003 (named entity recognition).
Inducing Causal Structure for Interpretable Neural Networks
Dec 01, 2021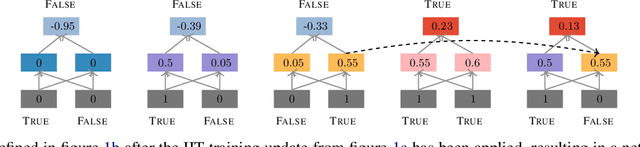
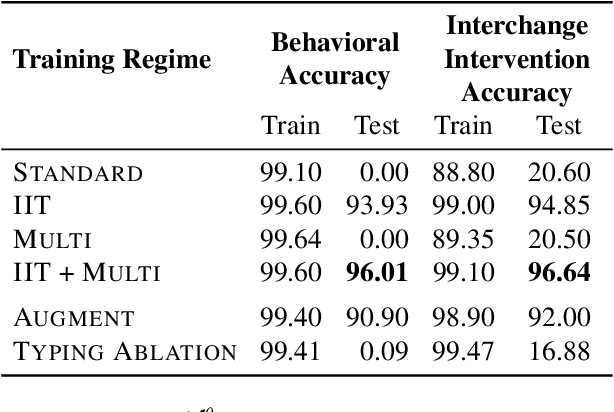
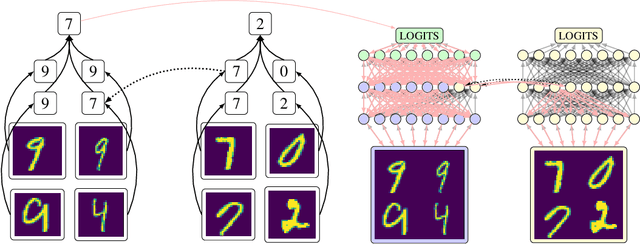
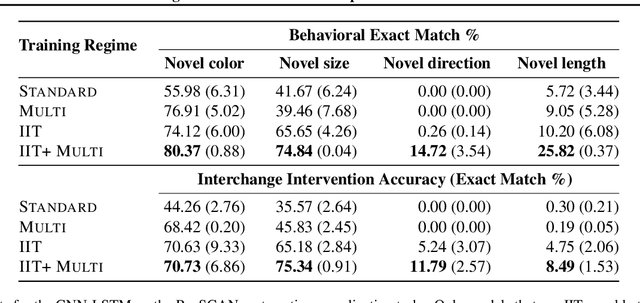
In many areas, we have well-founded insights about causal structure that would be useful to bring into our trained models while still allowing them to learn in a data-driven fashion. To achieve this, we present the new method of interchange intervention training(IIT). In IIT, we (1)align variables in the causal model with representations in the neural model and (2) train a neural model to match the counterfactual behavior of the causal model on a base input when aligned representations in both models are set to be the value they would be for a second source input. IIT is fully differentiable, flexibly combines with other objectives, and guarantees that the target causal model is acausal abstraction of the neural model when its loss is minimized. We evaluate IIT on a structured vision task (MNIST-PVR) and a navigational instruction task (ReaSCAN). We compare IIT against multi-task training objectives and data augmentation. In all our experiments, IIT achieves the best results and produces neural models that are more interpretable in the sense that they realize the target causal model.
Decrypting Cryptic Crosswords: Semantically Complex Wordplay Puzzles as a Target for NLP
Apr 17, 2021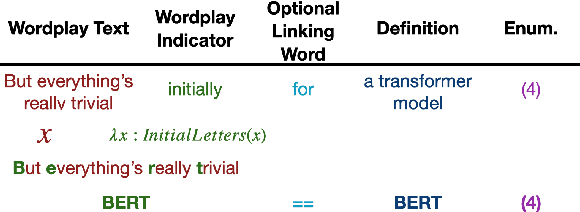
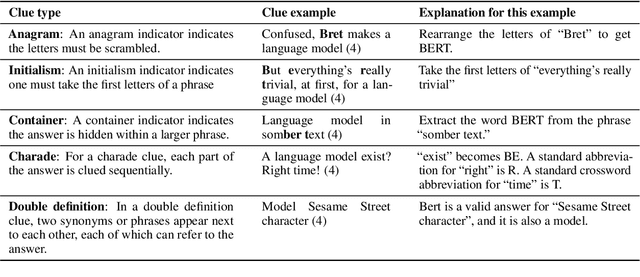

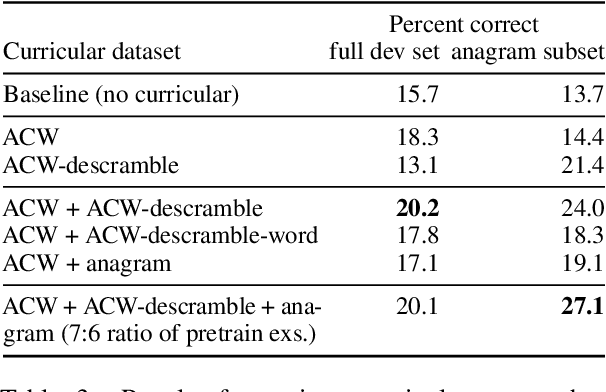
Cryptic crosswords, the dominant English-language crossword variety in the United Kingdom, can be solved by expert humans using flexible, creative intelligence and knowledge of language. Cryptic clues read like fluent natural language, but they are adversarially composed of two parts: a definition and a wordplay cipher requiring sub-word or character-level manipulations. As such, they are a promising target for evaluating and advancing NLP systems that seek to process language in more creative, human-like ways. We present a dataset of cryptic crossword clues from a major newspaper that can be used as a benchmark and train a sequence-to-sequence model to solve them. We also develop related benchmarks that can guide development of approaches to this challenging task. We show that performance can be substantially improved using a novel curriculum learning approach in which the model is pre-trained on related tasks involving, e.g, unscrambling words, before it is trained to solve cryptics. However, even this curricular approach does not generalize to novel clue types in the way that humans can, and so cryptic crosswords remain a challenge for NLP systems and a potential source of future innovation.