 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Neural Networks through Representation Erasure
Paper and Code
Jan 10, 2017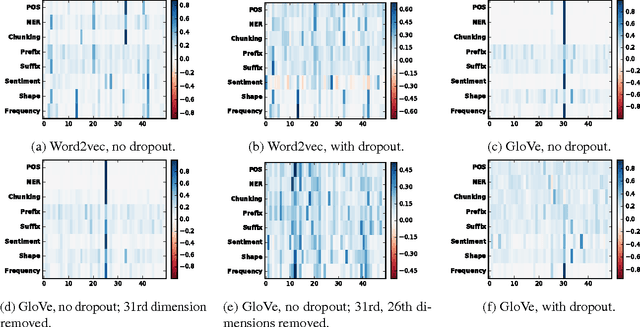

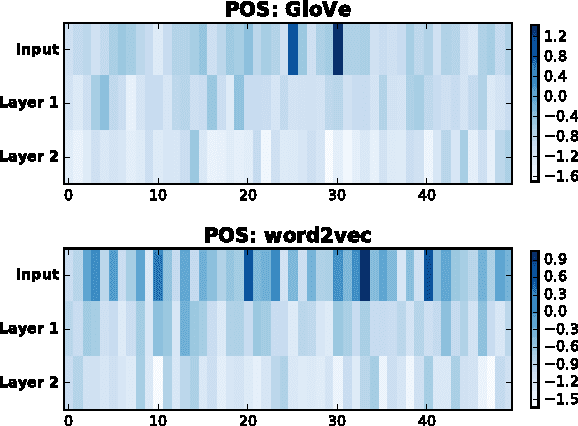

While neural networks have been successfully applied to many natural language processing tasks, they come at the cost of interpretability. In this paper, we propose a general methodology to analyze and interpret decisions from a neural model by observing the effects on the model of erasing various parts of the representation, such as input word-vector dimensions, intermediate hidden units, or input words. We present several approaches to analyzing the effects of such erasure, from computing the relative difference in evaluation metrics, to using reinforcement learning to erase the minimum set of input words in order to flip a neural model's decision. In a comprehensive analysis of multiple NLP tasks, including linguistic feature classification, sentence-level sentiment analysis, and document level sentiment aspect prediction, we show that the proposed methodology not only offers clear explanations about neural model decisions, but also provides a way to conduct error analysis on neural models.