 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
Feb 24, 2018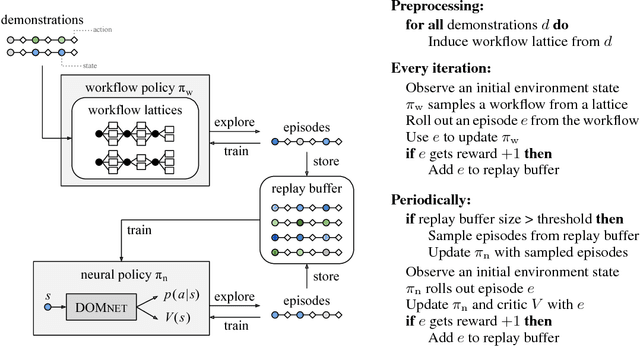

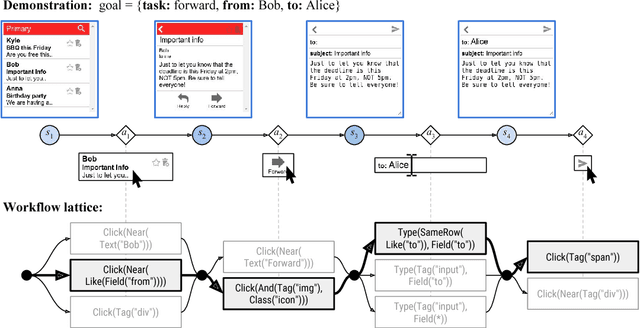
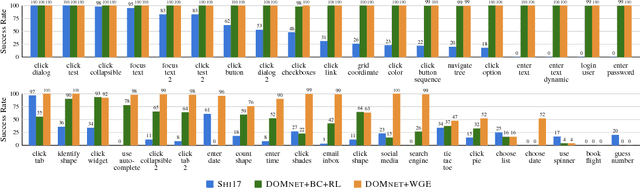
Reinforcement learning (RL) agents improve through trial-and-error, but when reward is sparse and the agent cannot discover successful action sequences, learning stagnates. This has been a notable problem in training deep RL agents to perform web-based tasks, such as booking flights or replying to emails, where a single mistake can ruin the entire sequence of actions. A common remedy is to "warm-start" the agent by pre-training it to mimic expert demonstrations, but this is prone to overfitting. Instead, we propose to constrain exploration using demonstrations. From each demonstration, we induce high-level "workflows" which constrain the allowable actions at each time step to be similar to those in the demonstration (e.g., "Step 1: click on a textbox; Step 2: enter some text"). Our exploration policy then learns to identify successful workflows and samples actions that satisfy these workflows. Workflows prune out bad exploration directions and accelerate the agent's ability to discover rewards. We use our approach to train a novel neural policy designed to handle the semi-structured nature of websites, and evaluate on a suite of web tasks, including the recent World of Bits benchmark. We achieve new state-of-the-art results, and show that workflow-guided exploration improves sample efficiency over behavioral cloning by more than 100x.
Adversarial Learning for Neural Dialogue Generation
Sep 24, 2017
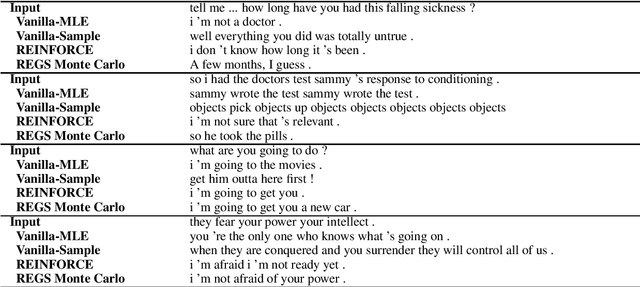

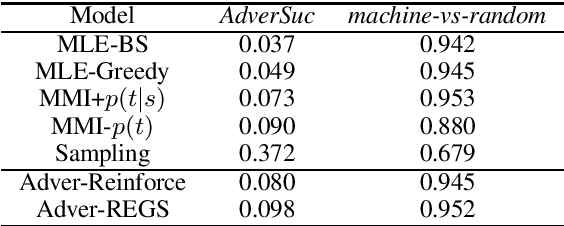
In this paper, drawing intuition from the Turing test, we propose using adversarial training for open-domain dialogue generation: the system is trained to produce sequences that are indistinguishable from human-generated dialogue utterances. We cast the task as a reinforcement learning (RL) problem where we jointly train two systems, a generative model to produce response sequences, and a discriminator---analagous to the human evaluator in the Turing test--- to distinguish between the human-generated dialogues and the machine-generated ones. The outputs from the discriminator are then used as rewards for the generative model, pushing the system to generate dialogues that mostly resemble human dialogues. In addition to adversarial training we describe a model for adversarial {\em evaluation} that uses success in fooling an adversary as a dialogue evaluation metric, while avoiding a number of potential pitfalls. Experimental results on several metrics, including adversarial evaluation, demonstrate that the adversarially-trained system generates higher-quality responses than previous baselines.
Max-margin Deep Generative Models
Dec 15, 2015

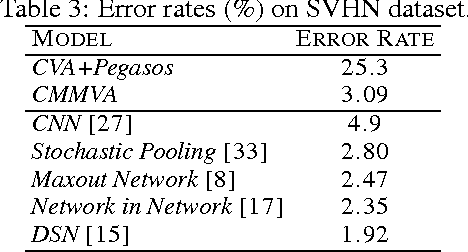
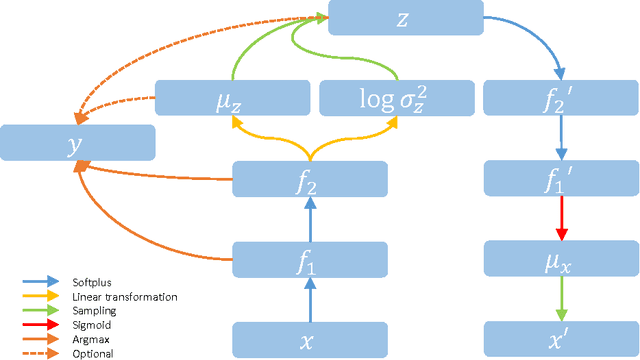
Deep generative models (DGMs) are effective on learning multilayered representations of complex data and performing inference of input data by exploring the generative ability. However, little work has been done on examining or empowering the discriminative ability of DGMs on making accurate predictions. This paper presents max-margin deep generative models (mmDGMs), which explore the strongly discriminative principle of max-margin learning to improve the discriminative power of DGMs, while retaining the generative capability. We develop an efficient doubly stochastic subgradient algorithm for the piecewise linear objective. Empirical results on MNIST and SVHN datasets demonstrate that (1) max-margin learning can significantly improve the prediction performance of DGMs and meanwhile retain the generative ability; and (2) mmDGMs are competitive to the state-of-the-art fully discriminative networks by employing deep convolutional neural networks (CNNs) as both recognition and generative models.
A Reverse Hierarchy Model for Predicting Eye Fixations
Apr 11, 2014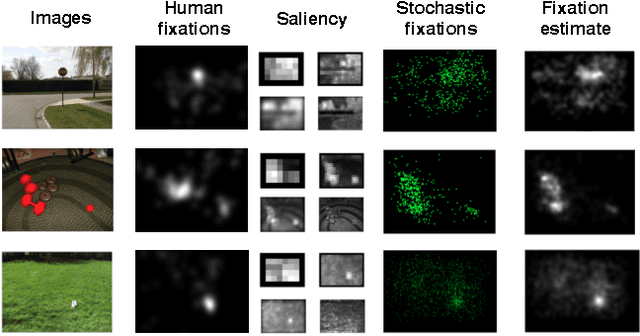



A number of psychological and physiological evidences suggest that early visual attention works in a coarse-to-fine way, which lays a basis for the reverse hierarchy theory (RHT). This theory states that attention propagates from the top level of the visual hierarchy that processes gist and abstract information of input, to the bottom level that processes local details. Inspired by the theory, we develop a computational model for saliency detection in images. First, the original image is downsampled to different scales to constitute a pyramid. Then, saliency on each layer is obtained by image super-resolution reconstruction from the layer above, which is defined as unpredictability from this coarse-to-fine reconstruction. Finally, saliency on each layer of the pyramid is fused into stochastic fixations through a probabilistic model, where attention initiates from the top layer and propagates downward through the pyramid. Extensive experiments on two standard eye-tracking datasets show that the proposed method can achieve competitive results with state-of-the-art models.
Online Bayesian Passive-Aggressive Learning
Dec 12, 2013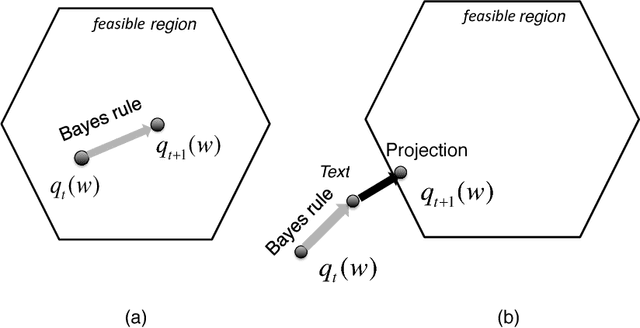

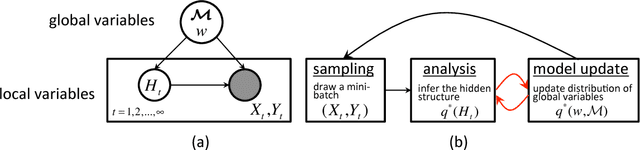
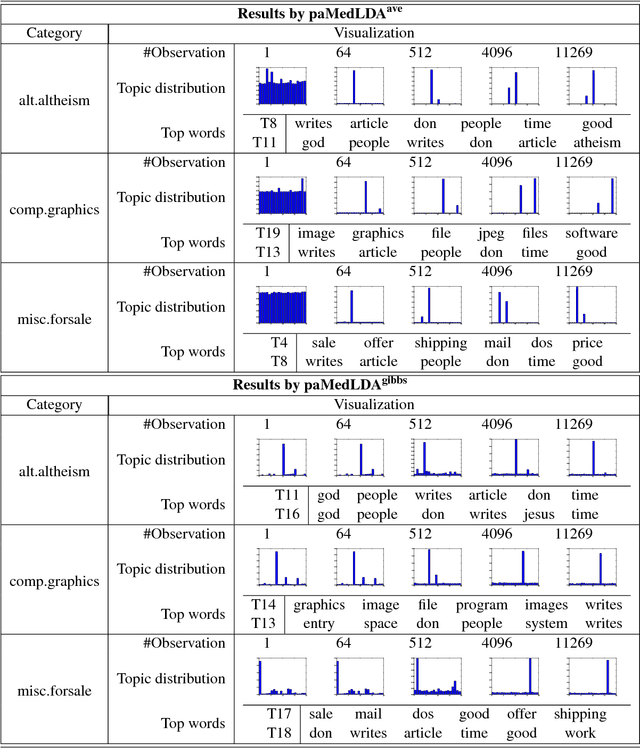
Online Passive-Aggressive (PA) learning is an effective framework for performing max-margin online learning. But the deterministic formulation and estimated single large-margin model could limit its capability in discovering descriptive structures underlying complex data. This pa- per presents online Bayesian Passive-Aggressive (BayesPA) learning, which subsumes the online PA and extends naturally to incorporate latent variables and perform nonparametric Bayesian inference, thus providing great flexibility for explorative analysis. We apply BayesPA to topic modeling and derive efficient online learning algorithms for max-margin topic models. We further develop nonparametric methods to resolve the number of topics. Experimental results on real datasets show that our approaches significantly improve time efficiency while maintaining comparable results with the batch counterparts.