 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFill in the Blanks: Imputing Missing Sentences for Larger-Context Neural Machine Translation
Oct 30, 2019
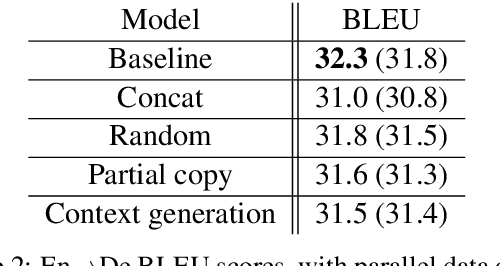
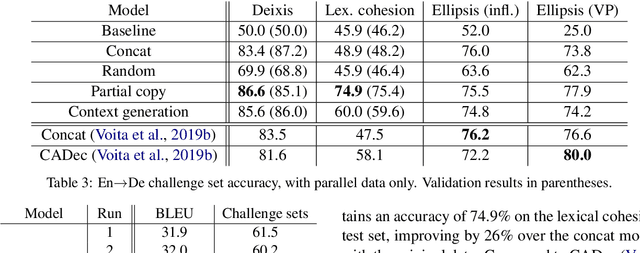
Most neural machine translation systems still translate sentences in isolation. To make further progress, a promising line of research additionally considers the surrounding context in order to provide the model potentially missing source-side information, as well as to maintain a coherent output. One difficulty in training such larger-context (i.e. document-level) machine translation systems is that context may be missing from many parallel examples. To circumvent this issue, two-stage approaches, in which sentence-level translations are post-edited in context, have recently been proposed. In this paper, we instead consider the viability of filling in the missing context. In particular, we consider three distinct approaches to generate the missing context: using random contexts, applying a copy heuristic or generating it with a language model. In particular, the copy heuristic significantly helps with lexical coherence, while using completely random contexts hurts performance on many long-distance linguistic phenomena. We also validate the usefulness of tagged back-translation. In addition to improving BLEU scores as expected, using back-translated data helps larger-context machine translation systems to better capture long-range phenomena.
Adaptive Scheduling for Multi-Task Learning
Sep 13, 2019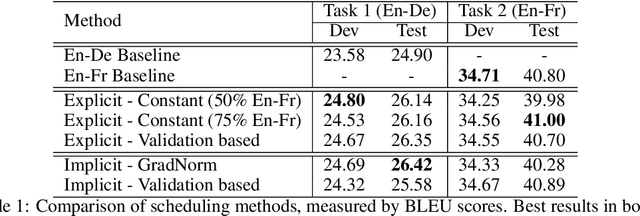
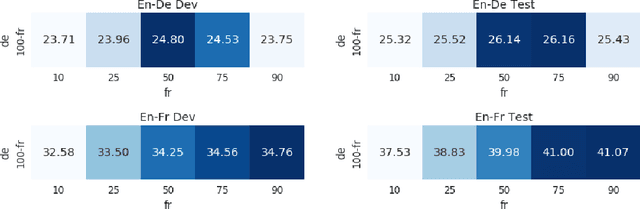
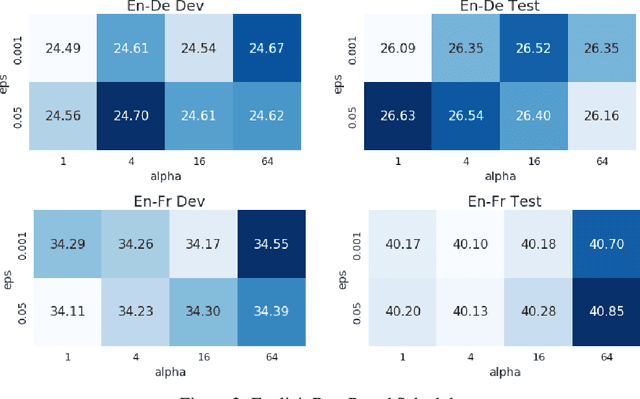
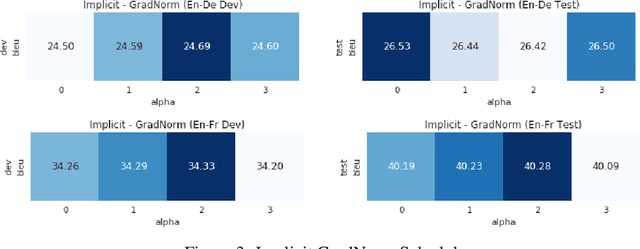
To train neural machine translation models simultaneously on multiple tasks (languages), it is common to sample each task uniformly or in proportion to dataset sizes. As these methods offer little control over performance trade-offs, we explore different task scheduling approaches. We first consider existing non-adaptive techniques, then move on to adaptive schedules that over-sample tasks with poorer results compared to their respective baseline. As explicit schedules can be inefficient, especially if one task is highly over-sampled, we also consider implicit schedules, learning to scale learning rates or gradients of individual tasks instead. These techniques allow training multilingual models that perform better for low-resource language pairs (tasks with small amount of data), while minimizing negative effects on high-resource tasks.
Context-Aware Learning for Neural Machine Translation
Mar 12, 2019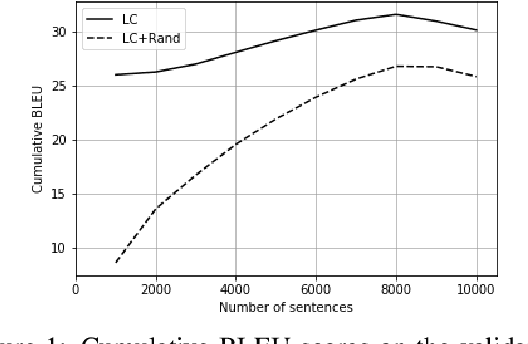
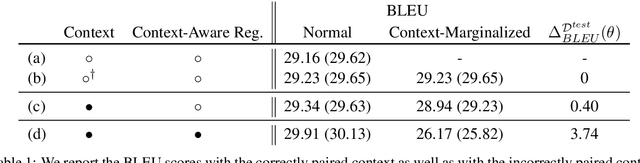
Interest in larger-context neural machine translation, including document-level and multi-modal translation, has been growing. Multiple works have proposed new network architectures or evaluation schemes, but potentially helpful context is still sometimes ignored by larger-context translation models. In this paper, we propose a novel learning algorithm that explicitly encourages a neural translation model to take into account additional context using a multilevel pair-wise ranking loss. We evaluate the proposed learning algorithm with a transformer-based larger-context translation system on document-level translation. By comparing performance using actual and random contexts, we show that a model trained with the proposed algorithm is more sensitive to the additional context.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019
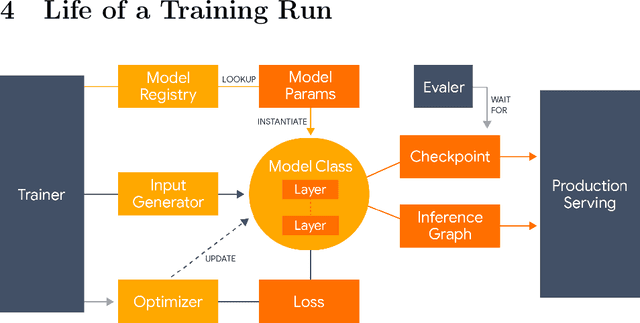
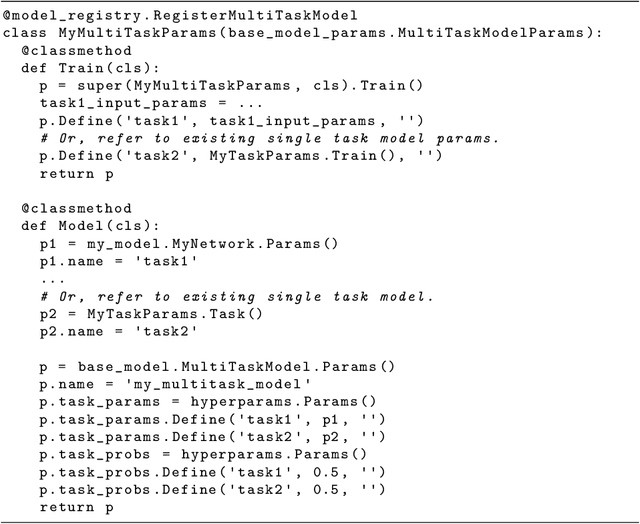
Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Adversarial Learning for Neural Dialogue Generation
Sep 24, 2017
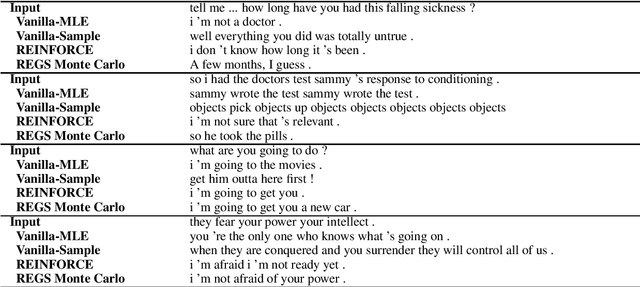

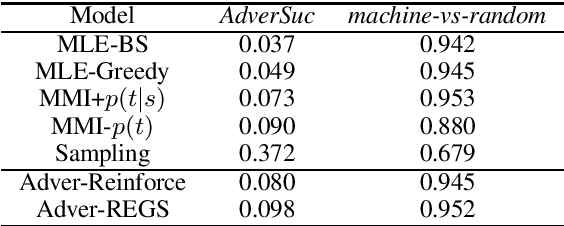
In this paper, drawing intuition from the Turing test, we propose using adversarial training for open-domain dialogue generation: the system is trained to produce sequences that are indistinguishable from human-generated dialogue utterances. We cast the task as a reinforcement learning (RL) problem where we jointly train two systems, a generative model to produce response sequences, and a discriminator---analagous to the human evaluator in the Turing test--- to distinguish between the human-generated dialogues and the machine-generated ones. The outputs from the discriminator are then used as rewards for the generative model, pushing the system to generate dialogues that mostly resemble human dialogues. In addition to adversarial training we describe a model for adversarial {\em evaluation} that uses success in fooling an adversary as a dialogue evaluation metric, while avoiding a number of potential pitfalls. Experimental results on several metrics, including adversarial evaluation, demonstrate that the adversarially-trained system generates higher-quality responses than previous baselines.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016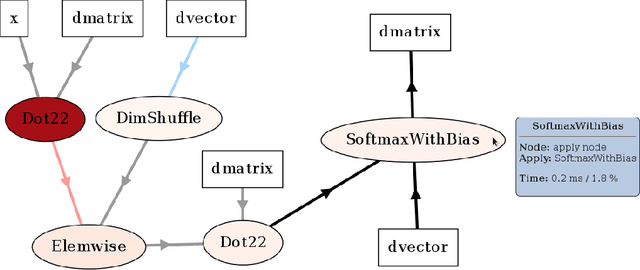
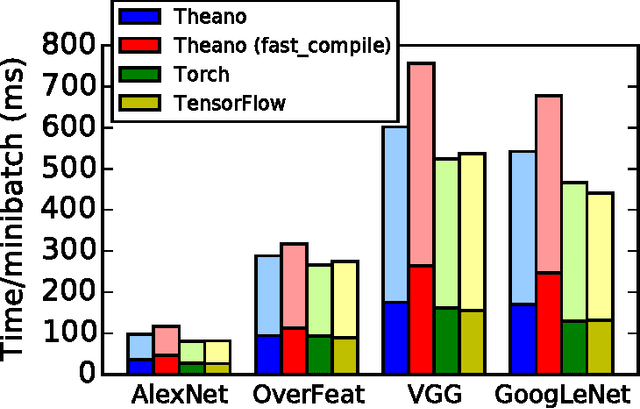
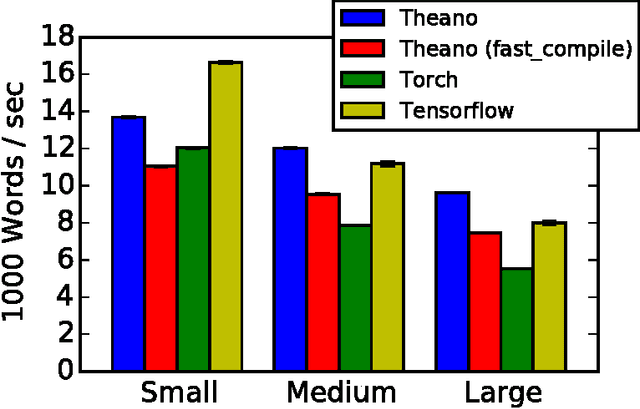
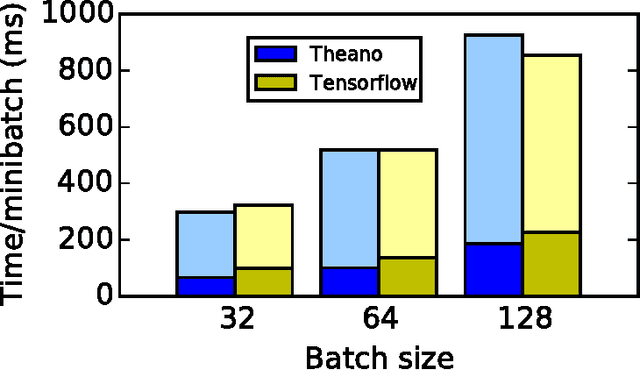
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
EmoNets: Multimodal deep learning approaches for emotion recognition in video
Mar 30, 2015

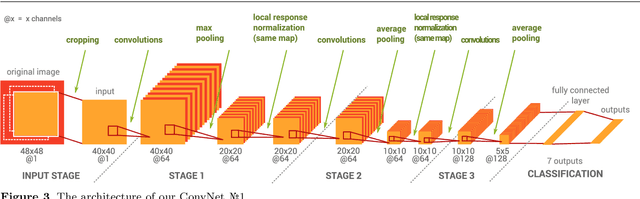
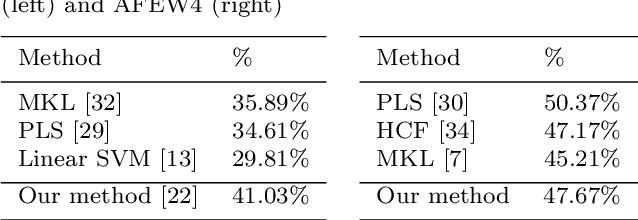
The task of the emotion recognition in the wild (EmotiW) Challenge is to assign one of seven emotions to short video clips extracted from Hollywood style movies. The videos depict acted-out emotions under realistic conditions with a large degree of variation in attributes such as pose and illumination, making it worthwhile to explore approaches which consider combinations of features from multiple modalities for label assignment. In this paper we present our approach to learning several specialist models using deep learning techniques, each focusing on one modality. Among these are a convolutional neural network, focusing on capturing visual information in detected faces, a deep belief net focusing on the representation of the audio stream, a K-Means based "bag-of-mouths" model, which extracts visual features around the mouth region and a relational autoencoder, which addresses spatio-temporal aspects of videos. We explore multiple methods for the combination of cues from these modalities into one common classifier. This achieves a considerably greater accuracy than predictions from our strongest single-modality classifier. Our method was the winning submission in the 2013 EmotiW challenge and achieved a test set accuracy of 47.67% on the 2014 dataset.
On Using Very Large Target Vocabulary for Neural Machine Translation
Mar 18, 2015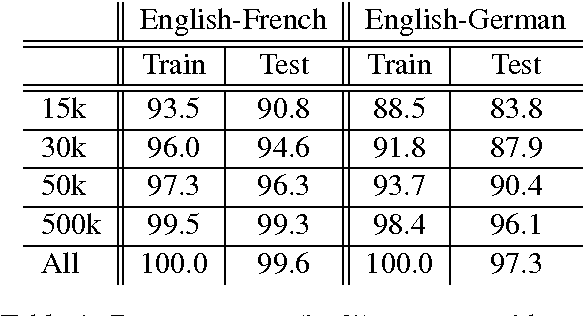
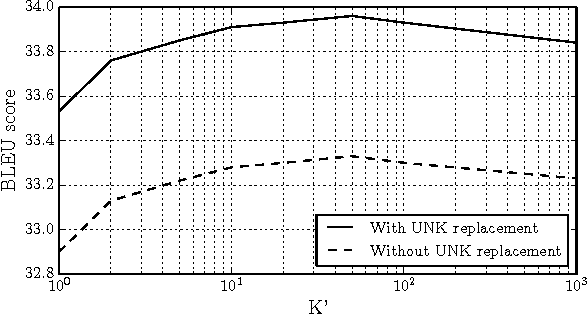
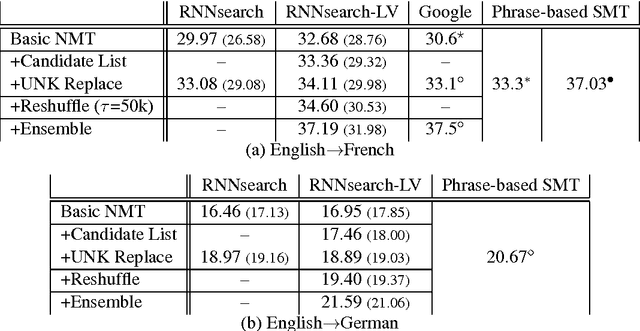
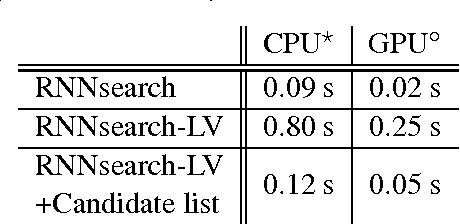
Neural machine translation, a recently proposed approach to machine translation based purely on neural networks, has shown promising results compared to the existing approaches such as phrase-based statistical machine translation. Despite its recent success, neural machine translation has its limitation in handling a larger vocabulary, as training complexity as well as decoding complexity increase proportionally to the number of target words. In this paper, we propose a method that allows us to use a very large target vocabulary without increasing training complexity, based on importance sampling. We show that decoding can be efficiently done even with the model having a very large target vocabulary by selecting only a small subset of the whole target vocabulary. The models trained by the proposed approach are empirically found to outperform the baseline models with a small vocabulary as well as the LSTM-based neural machine translation models. Furthermore, when we use the ensemble of a few models with very large target vocabularies, we achieve the state-of-the-art translation performance (measured by BLEU) on the English->German translation and almost as high performance as state-of-the-art English->French translation system.