 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Scheduling for Multi-Task Learning
Paper and Code
Sep 13, 2019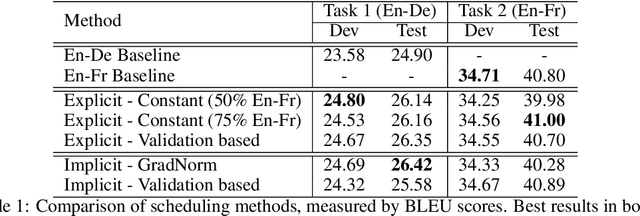
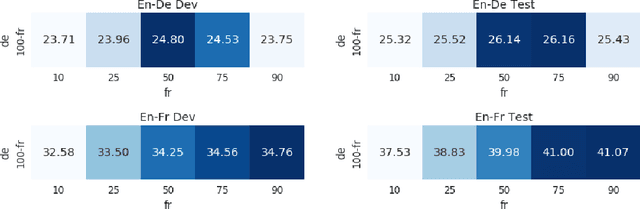
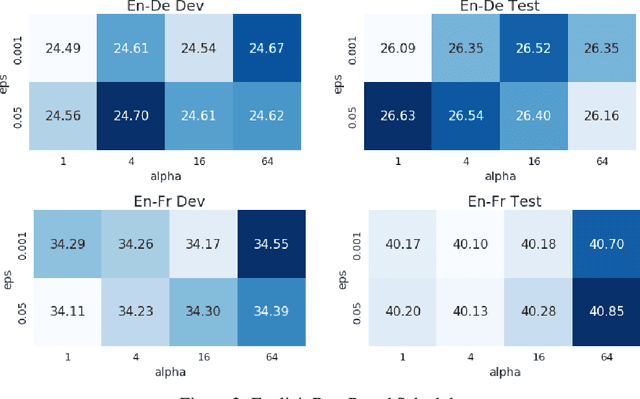
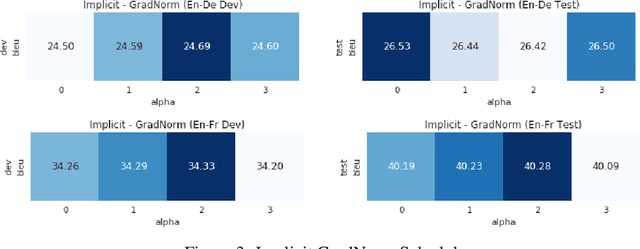
To train neural machine translation models simultaneously on multiple tasks (languages), it is common to sample each task uniformly or in proportion to dataset sizes. As these methods offer little control over performance trade-offs, we explore different task scheduling approaches. We first consider existing non-adaptive techniques, then move on to adaptive schedules that over-sample tasks with poorer results compared to their respective baseline. As explicit schedules can be inefficient, especially if one task is highly over-sampled, we also consider implicit schedules, learning to scale learning rates or gradients of individual tasks instead. These techniques allow training multilingual models that perform better for low-resource language pairs (tasks with small amount of data), while minimizing negative effects on high-resource tasks.